







【温馨提示,本文是理论文,手撕的文章还在加急处理中】
前言:
程序员老张最近失业了。不是因为他写代码时把分号敲成了希腊字母“α”(虽然这确实发生过),而是因为他试图用一坨意大利面条——哦不,是一坨链表——给楼下菜鸟驿站的快递包裹做自动分拣。结果某位邻居收到了一箱猫粮和三双荧光绿洞洞鞋,而隔壁程序员小王则被迫签收了一整箱《母猪产后护理指南》。
“你这分拣系统,简直比量子力学还薛定谔。”小王愤怒地在业主群@他。
老张痛定思痛,终于悟了: 链表就像单身汉的衣柜——东西随便塞,找起来要命; 而二叉搜索树,才是强迫症的天堂——左小右大,泾渭分明。
今天,就让我们用C++给快递小哥打造一棵“二叉搜索树分拣机”,保证从此以后,你的包裹再也不会和邻居的假发、前任的结婚请柬、以及小区广场舞领队的“震楼级”蓝牙音箱纠缠不清。
(小声:如果代码跑着跑着突然开始给你的袜子配对,别慌,那是BST在拓展副业。)
1.二叉搜索树的概念
二叉搜索树又被称之为二叉排序树,它或者是一棵空树,或者是一棵具有以下性质的树:
1.如果它的左子树不为空,则左子树上所有结点的值都小于等于根结点的值。
2.如果它的右子树不为空,则右子树上所有结点的值都大于等于根结点的值。
3.它的左右子树也分别为二叉搜索树。
4.二叉搜索树中可以支持插入相等的值,也可以不支持插入相等的值,这个要看具体的使用场景,小编本篇文章实现的二叉搜索树就是不支持插入相等的值。【因为插入相等的值比较麻烦】。就比如下面一张图就是两棵典型的二叉搜索树。

上面的可能部分读者感觉有点“干巴”,不要急,下面我在用比较形象的语言去诉说一下二叉搜索树:
🌳 二叉搜索树的灵魂三问:
-
每个快递包裹(节点)都带着唯一编号(键值)
-
左分拣区的所有包裹编号 < 当前包裹编号
-
右分拣区的所有包裹编号 > 当前包裹编号
📦 快递站长的终极法则(递归定义):
假设你是快递站站长,现在收到一个编号为50的包裹:
-
如果当前货架是空的 ➔ 直接把这个包裹放上去
-
如果货架上已有编号70的包裹 ➔ 把新包裹扔到左边货架区(因为50<70)
-
如果货架上已有编号30的包裹 ➔ 把新包裹扔到右边货架区(因为50>30)
每个货架都会对后续包裹重复这个操作,最终形成这样的结构:
[50]
/ \
[30] [70]
/ \ / \
[20][40][60][80]⚡ 二叉搜索树的超能力:
-
闪电查找:找编号63的包裹?从50→70→60→... 每次淘汰一半错误选项
-
自动排序:中序遍历(左→中→右)直接输出20,30,40,50,60,70,80
-
动态更新:新增/撤单包裹时,整个货架体系会自动重新组织路线
💣 危险操作(常见误区):
[50]
/ \
[30] [70]
/ \
[60] [80]
/
[55] // 合法!60>55且55>50?
// 不!虽然55>50,但它出现在70的左子树里
// 而55<70是合法的,整体依然满足BST定义❌ 这不是二叉搜索树:
[50]
/ \
[30] [70]
/ \
[20] [80] // 灾难!20出现在70的左子树
// 但20<50,应该在整个左半区看到这里,我相信各位读者都大致了解了什么是二叉搜索树,那么可能很多读者会好奇二叉搜索树为什么会出现?这是个好问题,下次不要问了(bushi),其实二叉搜索树在一些需要用到搜索的场景下有一个比较好的性能,下面小编来谈一谈二叉搜索树的性能!
2.二叉搜索树的性能分析
2.1.样例
如果你的老师给了你一组数据,让你写一个算法来实现对一个数的搜索,你可能会想到下面两个解法:
1.纯暴力求解
顾名思义,纯纯的暴力,也就是通过循环一个一个进行查找,相信不少读者会选择这个解法,毕竟暴力求解往往是最简单的,不过这样的话很考察这个数据在哪个位置,如果数据恰巧在最后一个位置,那么就意味着要把整组数据遍历一遍,这样的时间复杂度会很高的,小编不推荐这个解法,不过对于新手来说,这个解法很友好。当然,仅仅局限于新手,老司机一般不会用到这个解法。不过很多学了算法的读者可能会选择下面这个解法。
2.二分查找算法
坦白说,这个算法确实是查找数据比较好用的算法,因为它的时间复杂度是在O(log(N)),对比上面的暴力求解,已经是很又好了,但是这个算法有个很大的局限性:数组必须是“有序”的,这里的有序并不单指是像1,2,3,4的这种有序,还有可能是在一些定义方面是有序的,具体可以参考小编写的二分算法类型的文章,我记着在去年我写了几篇关于它的,不过最后还是处于停更状态,等我状态调好,定会慢慢更新。不过当时我也说了二分算法的一个弊端:非常容易进入死循环,这个就是看你细节不细节了,当然二分算法还有一个缺点就是在插入和删除数据比较低效,不过和我说的例子就没什么关系了。
这时候可能有读者会说了:小编你叨叨了这么多,不就是想来衬托一下二叉搜索树的优点嘛!确实是这样的,铺垫了这么多,下面我就来讲述一下本期的主角:二分查找算法(bushi),二叉搜索树!
2.2.二叉搜素树的价值
根据小编上面讲述的二叉搜索树的定义,相信读者的脑子里已经形成了:左边的结点的数据小,右边的数据大;通过这个特性其实我们就可以进行查找了,如果我们查找的数比根节点小,那么就找左子树,反之则找右子树,通过对数的遍历,我们就可以实现对于一个数据的查找,下面我来说一下最好情况以及最差情况下的时间复杂度
1.最优情况下,二叉搜索树为完全二叉树(或者接近完全二叉树),其高度为: log2 N,时间复杂度大致为O(logN)。
2.最差情况下,二叉搜索树退化为单支树(或者类似单支),其高度为: N时间复杂度大致为O(N)。
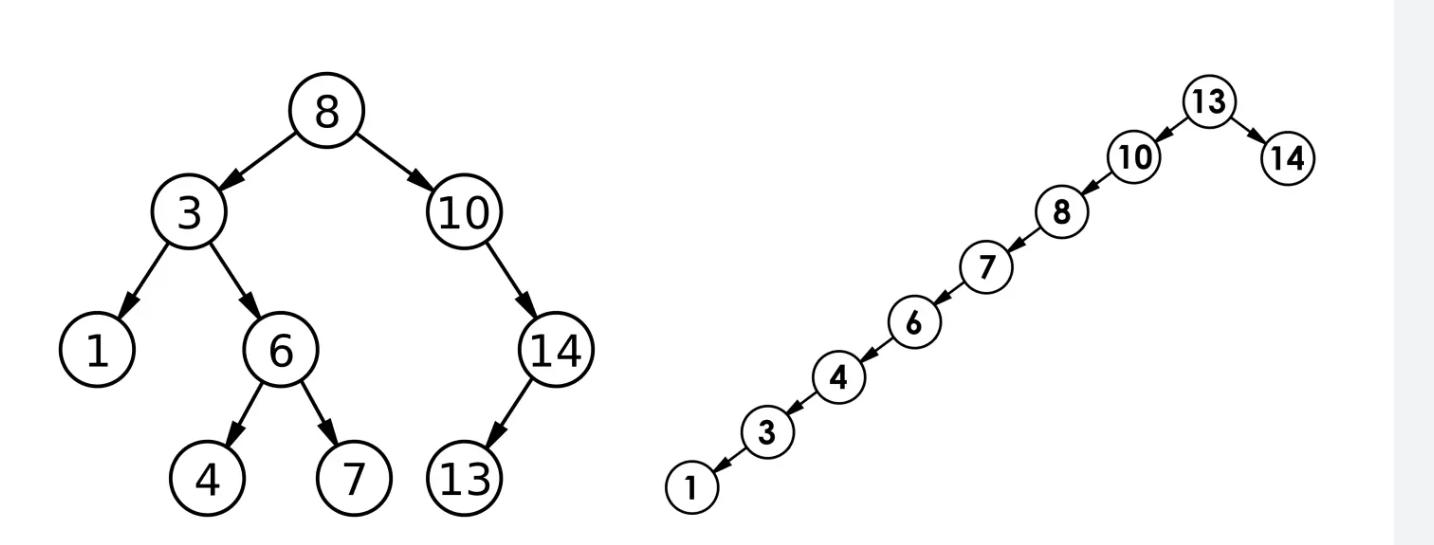
综合来看,二叉搜索树进行数据增删查的时间复杂度为O(N),相信不少读者看到这里会说,这不和暴力查找的时间复杂度一样吗,并且它的时间复杂度远远比不上二分查找,非也非也,大多数情况我们遇不到最差的二叉搜索树,暴力求解在数据很大的时候就很伤,二分查找的要求很高,所以此时我们用二叉搜索树可以解决大部分问题,不过其实二叉搜索树也不是一颗比较完美的树,后期的AVL数和红黑树才算是真正意义上的比较完美的树,不过这些都是后话了,如果我们一上来就说AVL和红黑,相信不少读者是觉得难以啃下的,二叉搜索树作为它们的基本,可以为它们的学习打好基础。
当然,我们学习二叉搜索树并不是为了学习它的理论知识,它的实现才是占大头,不过我准备下次进行二叉搜索树的“手撕”,具体原因可以看结尾我说的。
3.结语
本文到这里也就结束了,相信不少读者朋友会说:作者,你为何这么短?我在这里解释一下:我认为手撕二叉搜索树很重要,并且相信很多后来看文章的读者大多数都是来看手撕的,所以我认为手撕可以单独成一篇文章,这里也就解决了部分读者的需求;对于还在学习的读者,我相信各位理论知识还没有这么充足,所以我觉得本文作为一篇科普文来说对于各位接下来的学习是足够了,看完了本文的读者,完全可以自己去尝试实现一下二叉搜索树,毕竟自己写的和看着我文章写的最后的收获肯定是不一样的,这里我先给各位打个预防针:二叉搜索树的删除算是一个比较坑的点,各位读者如果实现不了,可以看小编下一篇文章,如果我文章还没有写出来,那么可以加一下文末或者主页小编的微信,小编欢迎各位读者来向小编进行提问。学习的时光总是短暂的,那么各位大佬们,我们下一篇文章见啦~【PS:刚发现今天是520,不过小编还是个单身狗,只能让代码来陪伴我了o(╥﹏╥)o】


















 1859
1859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









