







我的讲解视频地址:
【论文学习】实时视频插帧模型RIFE解读与代码复现_哔哩哔哩_bilibili
【论文学习】实时视频插帧模型RIFE解读与代码复现
概述
此论文标题是《RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation》,意为一种实时的视频插帧光流估计方法。该论文被ECCV 2022收录,提出了一个十分轻量又准确的光流估计网络IFNet,用于完成视频插帧任务。
论文摘要
我们提出了RIFE,一种用于视频帧插值(VFI)的实时中间流估计算法。大多数现有的基于流的方法首先估计双向光流,然后缩放和反转它们来近似中间流,这会导致运动边界上的伪影。RIFE使用了一个名为IFNet的神经网络,它可以直接从图像中估计中间流,速度更快。基于我们提出的泄露蒸馏损失(leakage distillation loss),RIFE可以以端到端的方式进行训练。实验表明,我们的方法灵活且能在几个公共基准测试上取得令人印象深刻的性能。代码可在GitHub - hzwer/ECCV2022-RIFE: ECCV2022 - Real-Time Intermediate Flow Estimation for Video Frame Interpolation找到。
下图展示了RIFE与其他方法在速度和准确率上的对比,从中可以发现RIFE能够在640*480的分辨率上实现60FPS的处理速度。

创新点
-
设计了一个高效的IFNet来简化基于流的视频帧插值(VFI)方法。IFNet可以从零开始训练,并且直接近似两个输入帧之间的中间流。
-
为中间流估计提供了有效的监督,特别是泄漏蒸馏损失(leakage distillation loss),这有助于更稳定的收敛和显著的性能提升。
-
使用模型缩放来获得具有不同质量和速度权衡的模型。实验表明,RIFE在公共基准测试中能够实现令人印象深刻的性能。
核心方法
下图是整个方法的流程图。主要由光流估计,前后帧扭曲(warping)和融合处理组成。
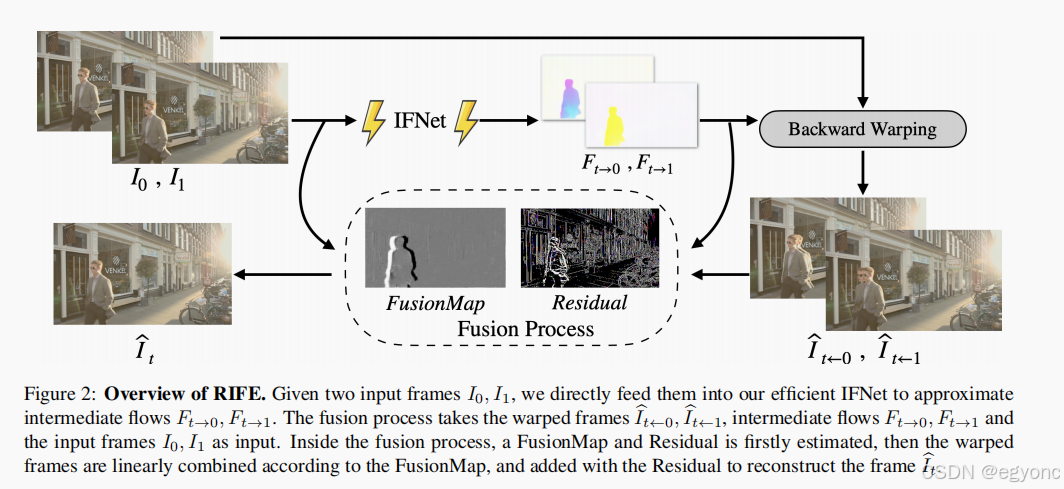
IFNet
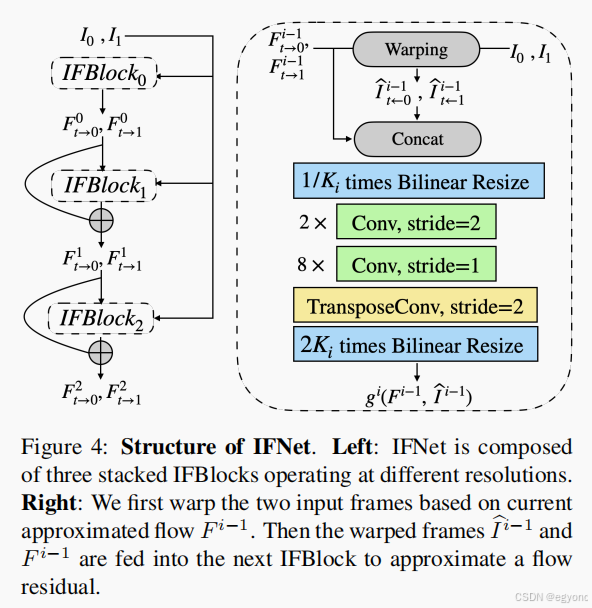
IFNet是论文提出的核心方法,用于估计光流,它的主要涉及如下图。
整个网络由3个IFBlock组成,由粗到细地预测光流。图中的右侧是一个IFBlock的详细设计图。
泄露蒸馏损失函数
泄露蒸馏损失(leakage distillation loss)是本文提出的另一个重要方法。它的核心思想在于,使用一个教师网络获取模型要预测的真实值,从而得到更准确的光流预测。
实现的方法是,IFNet中增加一个IFBlock,它具有额外的真实值(模型需要预测的中间帧,在数据集中提供)作为输入。这个IFBlock作为教师网络,在训练时使用,而在模型推理时则不使用。这样在减小网络参,提高效率的同时,通过教师信息提高光流预测的准确性。
文中对该损失函数的定义如下:
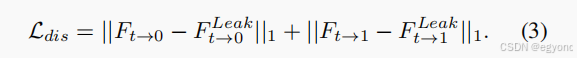
模型表现
首先作者对比了该方法和先前方法在多个数据集上的指标对比,如下图所示

该模型在多个数据集上取得了不错的指标效果。同时,在本方法强调的实时性,速度上,小版模型的运行速度是最块的,参数量也较小。
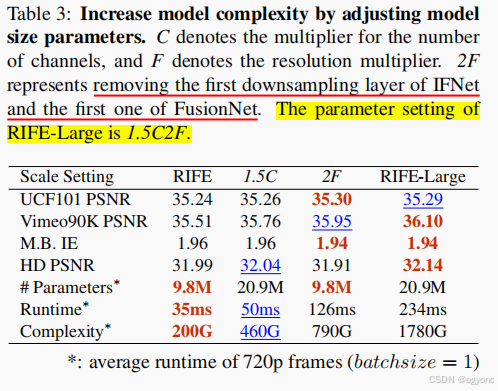
然后作者还增加了模型参数,得到Large版本的模型,它的速度会稍慢一点,但准确率有所上升。下图展示了不同模型参数下的指标对比。
代码复现
核心模型代码
IFNet.py
模型的定义:
class IFNet(nn.Module): def __init__(self): super(IFNet, self).__init__() self.block0 = IFBlock(6, c=240) self.block1 = IFBlock(13+4, c=150) self.block2 = IFBlock(13+4, c=90) self.block_tea = IFBlock(16+4, c=90) self.contextnet = Contextnet() self.unet = Unet()
IFBlock定义:
class IFBlock(nn.Module): def __init__(self, in_planes, c=64): super(IFBlock, self).__init__() self.conv0 = nn.Sequential( conv(in_planes, c//2, 3, 2, 1), conv(c//2, c, 3, 2, 1), ) self.convblock = nn.Sequential( conv(c, c), conv(c, c), conv(c, c), conv(c, c), conv(c, c), conv(c, c), conv(c, c), conv(c, c), ) self.lastconv = nn.ConvTranspose2d(c, 5, 4, 2, 1) def forward(self, x, flow, scale): if scale != 1: x = F.interpolate(x, scale_factor = 1. / scale, mode="bilinear", align_corners=False) if flow != None: flow = F.interpolate(flow, scale_factor = 1. / scale, mode="bilinear", align_corners=False) * 1. / scale x = torch.cat((x, flow), 1) x = self.conv0(x) x = self.convblock(x) + x tmp = self.lastconv(x) # 上采样 tmp = F.interpolate(tmp, scale_factor = scale * 2, mode="bilinear", align_corners=False) flow = tmp[:, :4] * scale * 2 mask = tmp[:, 4:5] return flow, mask
训练
我们的实验环境是Windows 10系统
CUDA=12.3
PyTorch=1.13
修改训练代码
在train.py中,我们需要添加以下代码来使DDP的后端使用gloo,因为windows能支持这种方式,不支持nccl。
os.environ["PL_TORCH_DISTRIBUTED_BACKEND"] = "gloo" os.environ["MASTER_ADDR"] = "localhost" os.environ["MASTER_PORT"] = "12345"
在main函数中,需要修改这行代码,修改DDP后端
torch.distributed.init_process_group(backend="gloo", world_size=args.world_size, rank=args.local_rank)
如果使用Linux系统,则不需要修改这一项。
修改数据集信息
在 dataset.py中,我们需要修改数据集的位置。需要自己下载Vimeo90k数据集,并解压。
数据集可以在 Video Enhancement with Task-Oriented Flow 下载。
以下是我的解压位置对应的修改。
self.data_root = r'E:\Workspace\Datasets\vimeo_triplet'
推理视频插帧
准备好视频文件,并安装好ffmpeg。
然后使用推理代码实现视频插帧
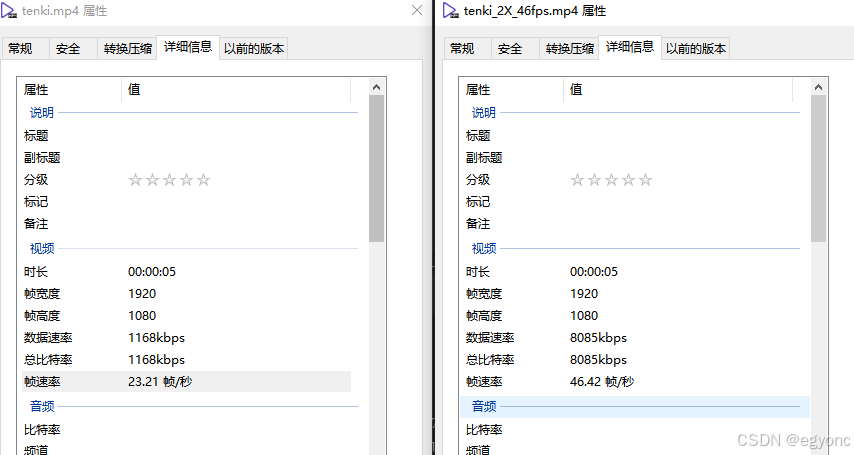
python inference_video.py --exp=1 --video=tenki.mp4
下图对比了推理前后的视频信息,可以看到帧率变成了原来的两倍

















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









