






1. framwork

1)![]() two distribution of augmentation
two distribution of augmentation
2)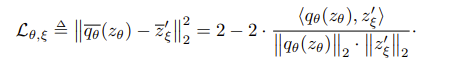
3)![]()
4)
5) q uses the same architecture as g(FC+BN+RELU+FC)
6)![]() with k the current training step and K the maximum number of training steps.(, the exponential moving average parameter τ starts from τbase = 0.996 and is increased to one during training.)
with k the current training step and K the maximum number of training steps.(, the exponential moving average parameter τ starts from τbase = 0.996 and is increased to one during training.)
2 Intuitions on BYOL’s behavior
a collapsed constant representation
1)BYOL’s target parameters ξ updates are not in the direction of ∇ξL BYOL θ,ξ ,There is therefore no a priori reason why BYOL’s parameters would converge to a minimum of L BYOL θ,ξ .
2)assuming BYOL’s predictor to be optimal
![]()
====>![]()
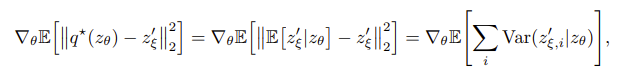
![]()
![]()
hence our hypothesis on these collapsed constant equilibria being unstable.
3.Building intuitions with ablations
batch size

only drops for smaller values due to batch normalization layers in the encoder
image augmentation

bootstrapping

ablation to contrastive methods

. To evaluate the influence of the target network, the predictor and the coefficient β, we perform an ablation over them
1)


2) target network
using a target network is beneficial but it has two distinct effects we would like to understand from which effect the improvement comes from.(stopping the gradient through the prediction targets and stabilizing the targets with averaging)

conclusion:making the prediction targets stable and stale is the main cause of the improvement rather than the change in the objective due to the stop gradient.
3)predictor
In this setup, we remove the exponential moving average (i.e., set τ = 0 over the full training in Eq. 1), and multiply the learning rate of the predictor by a constant λ compared to the learning rate used for the rest of the network; all other hyperparameters are unchanged. As shown in Table 21, using sufficiently large values of λ provides a reasonably good level of performance and the performance sharply decreases with λ to 0.01% top-1 accuracy (no better than random) for λ = 0.

To show that this effect is directly related to a change of behavior in the predictor, and not only to a change of learning rate in any subpart of the network, we perform a similar experiment by using a multiplier λ on the predictor’s learning rate, and a different multiplier µ for the projector.

conclusion : one of the contributions of the target network is to maintain a near optimal predictor at all times
Optimal linear predictor in closed form
![]()
At 300 epochs, when using the closed form optimal predictor, and directly hard copying the weights of the online network into the target, we obtain a top-1 accuracy of fill.
Network hyperparameters
removing the weight decay in either BYOL or SimCLR leads to network divergence
















 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









