






Grill J B, Strub F, Altché F, et al. Bootstrap your own latent-a new approach to self-supervised learning[J]. Advances in neural information processing systems, 2020, 33: 21271-21284.
1. 前言
之前的对比学习总是依赖大量的负样本来训练模型,然而本文的研究发现,图像增强的选择相较于对比大量的负样本更具有鲁棒性。因此,作者认为基于对比学习的方法可以不利用负样本就能够获得较好的表征,这样也可以减少大量的复杂性。
2. 方法
作者这里还是使用了一个双塔模型,一个称为online network,一个称为target network。online network会利用梯度反向传播来更新参数,而target network则使用exponential moving average(EMA)来更新参数。具体如下所示:
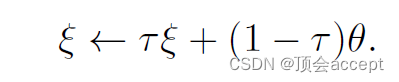
其实思路很简单,就是将online network和target network加权求和。
由于只需要对同一个图像的不同增强视角来对比,因此没有了负样本,损失函数也变得更为简单了:
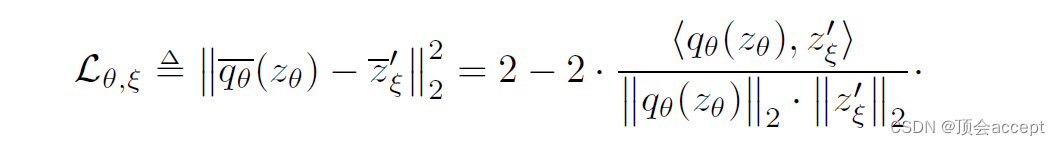
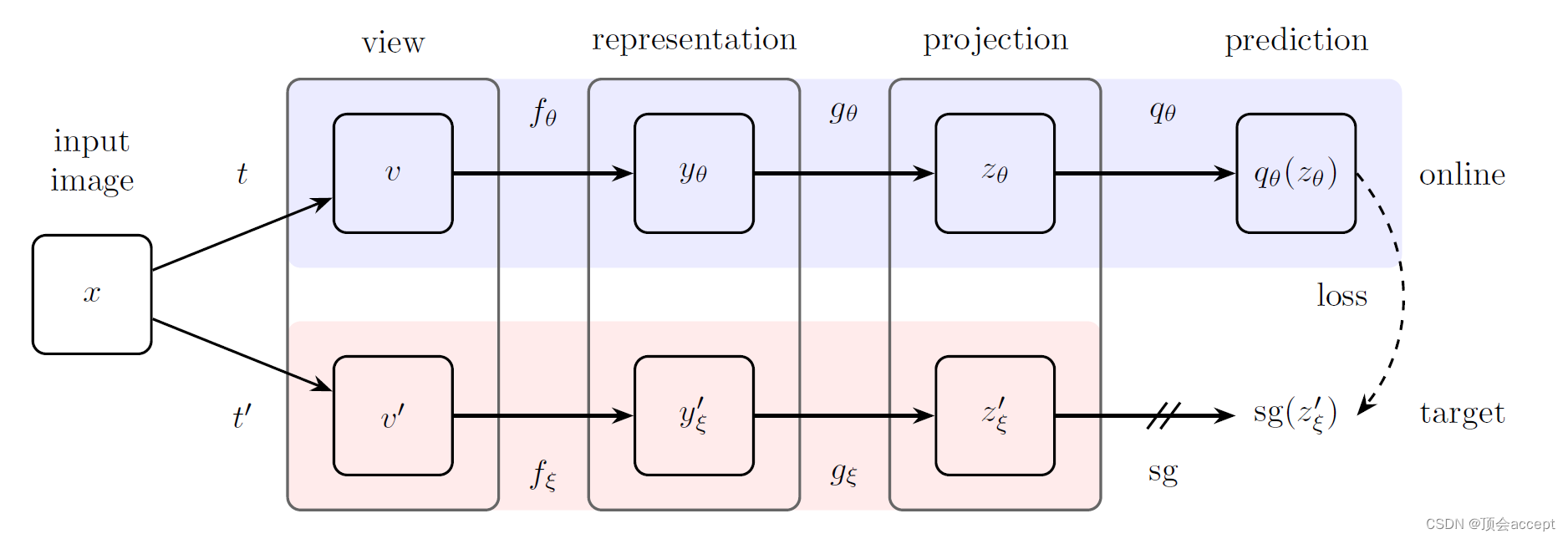
算法流程图如下所示:

一张图片通过两种增强手段,分别输入到online network和target network中,然后计算损失。这里的损失函数有两项是因为有<view1 online, view2 target>, <view2 online, view1 target>两种组合。
3. 代码
计算损失
def update(self, batch1, batch2):
prediction_view_1 = self.predictor(self.online(batch1))
prediction_view_2 = self.predictor(self.online(batch2))
with torch.no_grad():
targets_view_1 = self.target(batch1)
targets_view_2 = self.target(batch2)
loss = self.regression_loss(prediction_view_1, targets_view_2)
loss += self.regression_loss(prediction_view_2, targets_view_1)
return loss.mean()
更新参数
@torch.no_grad()
def update_target_network_parameters(self):
for param_q, param_k in zip(self.online.parameters(), self.target.parameters()):
param_k.data = param_k.data * self.m + param_q.data * (1 - self.m)














 922
922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









