



1. 关于 cuquantum 概述
官方文档:
https://docs.nvidia.com/cuda/cuquantum/latest/appliance/overview.html#prerequisitesNVIDIA 的 cuQuantum 是一个专门用于量子计算的高性能库,旨在加速量子电路的模拟和量子算法的执行。cuQuantum 提供了一系列工具和功能,帮助研究人员和开发者在 NVIDIA GPU 上高效地进行量子计算。以下是关于 cuQuantum 的详细介绍:
1.1. 主要功能
量子电路模拟:cuQuantum 提供了高效的量子电路模拟器,能够模拟大规模的量子电路。它支持多种量子计算模型,包括量子门模型和量子态模型。
高性能计算:利用 NVIDIA GPU 的并行计算能力,cuQuantum 可以显著加速量子电路的模拟过程,特别是在处理复杂的量子态和大规模量子系统时。
灵活性:cuQuantum 设计为与其他量子计算框架(如 Qiskit、Cirq 等)兼容,允许用户在不同的量子计算环境中使用 cuQuantum 的功能。
1.2. 组件
cuQuantum 包含多个组件,主要包括:
cuStateVec:用于模拟量子态的库,支持高效的量子态向量操作和量子门应用。
cuTensorNetwork:用于处理张量网络的库,适用于模拟量子系统的复杂性,特别是在量子多体系统的研究中。
cuQuantum SDK:提供了一整套 API 和工具,帮助开发者构建和优化量子算法。
1.3. 应用场景
cuQuantum 可以应用于多个领域,包括:
量子算法开发:研究人员可以使用 cuQuantum 来开发和测试新的量子算法,评估其性能和效率。
量子模拟:在量子物理、化学和材料科学等领域,cuQuantum 可以用于模拟量子系统的行为,帮助理解复杂的量子现象。
量子计算教育:cuQuantum 也可以作为教育工具,帮助学生和研究人员学习量子计算的基本原理和应用。
2,docker 运行 cuquantum
2.1 下载 docker image
x86_64 平台
$ sudo docker pull nvcr.io/nvidia/cuquantum-appliance:24.03-x86_642.2 创建 容器
创建一个可以使用全部gpu 的容器:
$ sudo docker run --gpus all -it --rm nvcr.io/nvidia/cuquantum-appliance:24.03-x86_64
创建一个仅仅使用0到3的gpu:
$ sudo docker run --gpus '"device=0,3"' -it --rm nvcr.io/nvidia/cuquantum-appliance:24.03-x86_64带文件夹映射:
$ sudo docker run --gpus all --name cuquantum_docker_dir_01 -it -v /home/hipper/ex_cuquantum/tmp1_docker:/home/cuquantum/tmp1_docker --rm nvcr.io/nvidia/cuquantum-appliance:24.03-x86_64
2.3 运行并解释示例
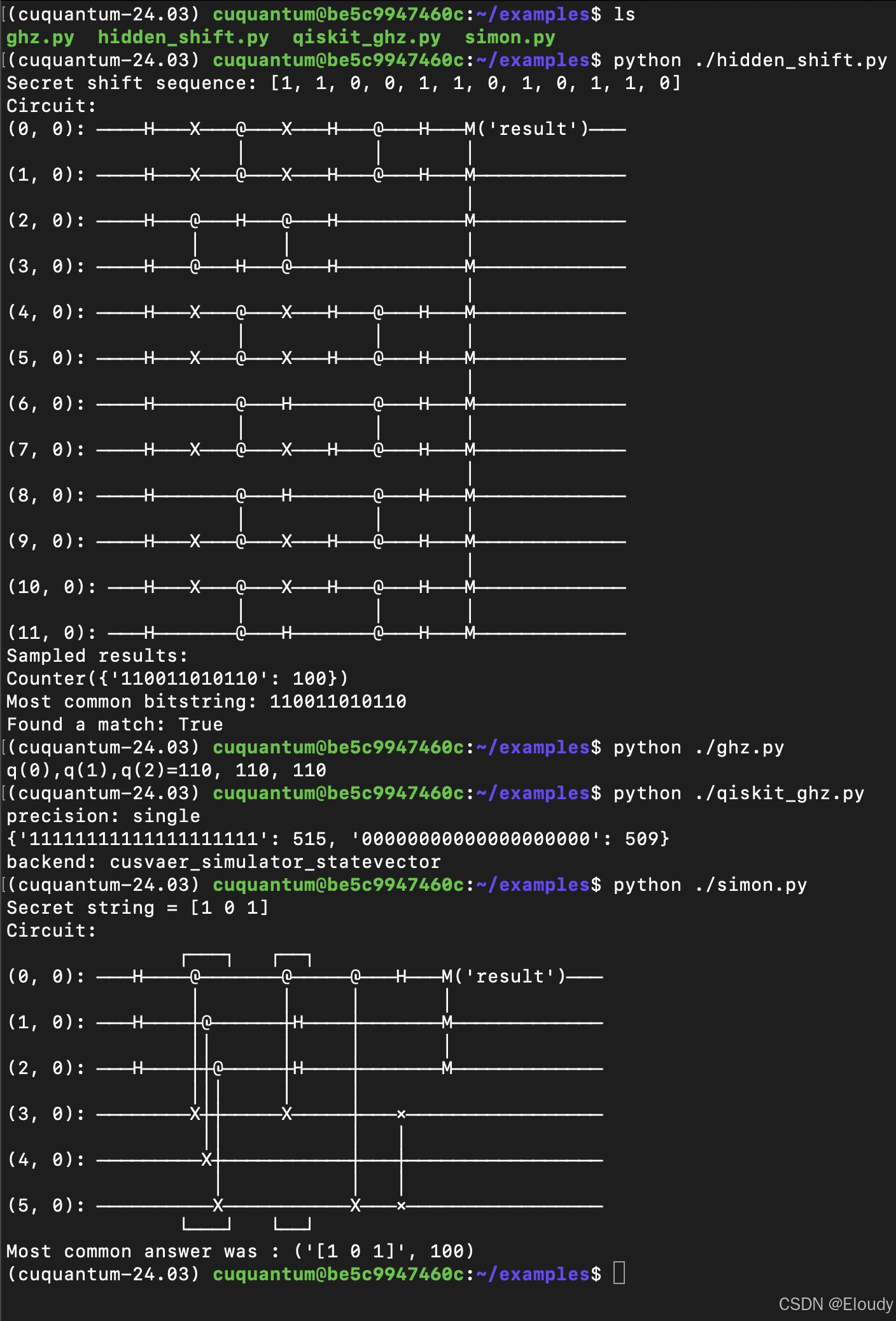
3,分析一下examples
用 nvprof 看一下 调用了哪些 cuda kernel:
$ nvprof python ./qiskit_ghz.py --nbits 16
cuquantum@be5c9947460c:~/examples$ nvprof python ./qiskit_ghz.py --nbits 16
==2331== NVPROF is profiling process 2331, command: python ./qiskit_ghz.py --nbits 16
==2371== Warning: Child processes are not profiled. Use option --profile-child-processes to profile them.
precision: single
{'1111111111111111': 518, '0000000000000000': 506}
backend: cusvaer_simulator_statevector
==2331== Profiling application: python ./qiskit_ghz.py --nbits 16
==2331== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 39.15% 53.473us 1 53.473us 53.473us 53.473us custatevec::_GLOBAL__N__2d201eb2_15_naiveSampler_cu_a2447900::intervalCumulativeSumKernel(double*, int)
22.28% 30.432us 1 30.432us 30.432us 30.432us void cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800, bool=0, double, int, unsigned int>(unsigned int const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800, bool=0, double, int, unsigned int>*, cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800 const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800, bool=0, double, int, unsigned int>**, bool=0, int, int)
9.11% 12.449us 3 4.1490us 4.1280us 4.1930us void custatevec::constMatApplKernel_cc70<int=64, int=1, custatevec::CsComplex<float>, int=4, custatevec::EmptyBitInserter<int=4>>(float*, custatevec::HostMatrixArgument<custatevec::constMatApplKernel_cc70<int=64, int=1, custatevec::CsComplex<float>, int=4, custatevec::EmptyBitInserter<int=4>>, custatevec::CsComplex<float>>, int=4, custatevec::TargetBitArray<custatevec::CsComplex<float>>)
7.17% 9.7920us 2 4.8960us 4.8640us 4.9280us void custatevec::constMatApplKernel_cc70_Relocate<int=64, custatevec::CsComplex<float>, int=4, custatevec::EmptyBitInserter<int=4>, int=9>(float*, custatevec::HostMatrixArgument<custatevec::constMatApplKernel_cc70_Relocate<int=64, custatevec::CsComplex<float>, int=4, custatevec::EmptyBitInserter<int=4>, int=9>, custatevec::CsComplex<float>>, int=4, custatevec::TargetBitArray<custatevec::CsComplex<float>>, custatevec::TargetRelocator<int=4, custatevec::CsComplex<float>>)
5.06% 6.9120us 1 6.9120us 6.9120us 6.9120us custatevec::_GLOBAL__N__2d201eb2_15_naiveSampler_cu_a2447900::sampleKernel(double const *, unsigned int, long, double, double const *, double const *, long, custatevec::BitPermutation<int=56> const &, long*)
4.76% 6.4960us 1 6.4960us 6.4960us 6.4960us _ZN10custatevec48_GLOBAL__N__2d201eb2_15_naiveSampler_cu_a244790028blockwiseCumulativeSumKernelIZNS0_26calculateCumulativeAbs2SumINS_9CsComplexIfEEEEvPKT_iRNS_18WorkspaceAllocatorEP11CUstream_stPdEUllE_EEvS5_lSC_
2.62% 3.5840us 2 1.7920us 1.7600us 1.8240us [CUDA memcpy HtoD]
1.83% 2.4960us 1 2.4960us 2.4960us 2.4960us void _GLOBAL__N__1d82f122_17_subStateVector_cu_ed18732a::setZeroStateKernel<custatevec::CsComplex<float>>(float*, long)
1.76% 2.4000us 1 2.4000us 2.4000us 2.4000us custatevec::_GLOBAL__N__2d201eb2_15_naiveSampler_cu_a2447900::applyPrevCumsumKernel(double*, long)
1.73% 2.3680us 1 2.3680us 2.3680us 2.3680us void _GLOBAL__N__1d82f122_17_subStateVector_cu_ed18732a::elementWiseKernel<custatevec::CsComplex<float>, _GLOBAL__N__1d82f122_17_subStateVector_cu_ed18732a::ApplyGlobalPhaseFunc>(float*, long, custatevec<_GLOBAL__N__1d82f122_17_subStateVector_cu_ed18732a::elementWiseKernel<custatevec::CsComplex<float>, _GLOBAL__N__1d82f122_17_subStateVector_cu_ed18732a::ApplyGlobalPhaseFunc>>::CsComplex<float>)
1.31% 1.7920us 1 1.7920us 1.7920us 1.7920us [CUDA memcpy DtoH]
1.24% 1.6960us 1 1.6960us 1.6960us 1.6960us _ZN10custatevec15transformKernelIZNS_7Sampler20revertToRandnumOrderEPKlPKiiP11CUstream_stPlEUllE_EEvT_ll
1.03% 1.4080us 1 1.4080us 1.4080us 1.4080us [CUDA memcpy DtoD]
0.94% 1.2810us 1 1.2810us 1.2810us 1.2810us _ZN10custatevec15transformKernelIZNS_7Sampler6sampleER17custatevecContextPlRKNS_17ConstPointerArrayIiEEPKdj25custatevecSamplerOutput_tEUllE_EEvT_ll
API calls: 85.96% 113.99ms 14 8.1423ms 1.1020us 95.611ms cudaFree
7.46% 9.8872ms 6 1.6479ms 920ns 9.8756ms cudaMallocAsync
2.25% 2.9832ms 14 213.08us 5.6500us 1.6952ms cudaLaunchKernel
1.22% 1.6129ms 1169 1.3790us 136ns 95.703us cuDeviceGetAttribute
1.15% 1.5256ms 1 1.5256ms 1.5256ms 1.5256ms cudaFuncGetAttributes
0.48% 639.60us 9 71.066us 4.3110us 168.95us cudaMalloc
0.42% 561.17us 1 561.17us 561.17us 561.17us cudaGetSymbolAddress
0.33% 440.17us 1546 284ns 147ns 4.0030us cuGetProcAddress
0.23% 303.23us 2 151.62us 131.73us 171.50us cudaGetDeviceProperties
0.10% 135.87us 2 67.934us 3.9910us 131.88us cudaStreamSynchronize
0.07% 91.601us 12 7.6330us 963ns 70.503us cudaSetDevice
0.06% 79.063us 10 7.9060us 3.8030us 14.732us cuDeviceGetName
0.05% 68.091us 4 17.022us 8.4410us 28.861us cudaMemcpyAsync
0.03% 45.182us 10 4.5180us 1.2030us 19.282us cudaDeviceSynchronize
0.03% 39.552us 38 1.0400us 480ns 13.937us cudaEventCreateWithFlags
0.03% 33.551us 38 882ns 395ns 5.2870us cudaEventDestroy
0.02% 27.488us 15 1.8320us 312ns 9.1020us cudaGetDevice
0.02% 27.099us 6 4.5160us 786ns 21.412us cudaFreeAsync
0.02% 23.308us 17 1.3710us 571ns 4.8130us cudaPointerGetAttributes
0.01% 15.184us 1 15.184us 15.184us 15.184us cudaStreamDestroy
0.01% 14.544us 1 14.544us 14.544us 14.544us cudaStreamCreate
0.01% 11.311us 2 5.6550us 2.0680us 9.2430us cuDeviceGetPCIBusId
0.01% 9.4620us 9 1.0510us 257ns 5.3700us cudaGetDeviceCount
0.01% 9.0560us 16 566ns 315ns 1.9580us cudaDeviceGetAttribute
0.01% 8.9320us 4 2.2330us 1.4670us 2.6370us cuInit
0.01% 6.9670us 35 199ns 133ns 703ns cudaGetLastError
0.00% 4.2820us 17 251ns 150ns 824ns cuDeviceGet
0.00% 3.3340us 10 333ns 229ns 601ns cuDeviceTotalMem
0.00% 2.8110us 9 312ns 193ns 843ns cuDeviceGetCount
0.00% 2.7800us 2 1.3900us 203ns 2.5770us cuCtxGetCurrent
0.00% 2.1550us 10 215ns 169ns 248ns cuDeviceGetUuid
0.00% 1.2690us 5 253ns 223ns 305ns cuModuleGetLoadingMode
0.00% 1.1090us 4 277ns 157ns 385ns cuCtxGetDevice
0.00% 869ns 4 217ns 181ns 257ns cuDriverGetVersion
0.00% 448ns 2 224ns 157ns 291ns cudaPeekAtLastError
$ nvprof python ./ghz.py
cuquantum@be5c9947460c:~/examples$ nvprof python ./ghz.py
==2389== NVPROF is profiling process 2389, command: python ./ghz.py
q(0),q(1),q(2)=101, 101, 101
==2389== Profiling application: python ./ghz.py
==2389== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 50.03% 29.341us 1 29.341us 29.341us 29.341us void cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800, bool=0, double, int, unsigned int>(unsigned int const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800, bool=0, double, int, unsigned int>*, cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800 const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800, bool=0, double, int, unsigned int>**, bool=0, int, int)
10.75% 6.3040us 5 1.2600us 1.0560us 1.7280us [CUDA memcpy HtoD]
8.84% 5.1830us 1 5.1830us 5.1830us 5.1830us _ZN10custatevec48_GLOBAL__N__2d201eb2_15_naiveSampler_cu_a244790028blockwiseCumulativeSumKernelIZNS0_26calculateCumulativeAbs2SumINS_9CsComplexIfEEEEvPKT_iRNS_18WorkspaceAllocatorEP11CUstream_stPdEUllE_EEvS5_lSC_
7.31% 4.2880us 2 2.1440us 1.9840us 2.3040us void custatevec::constMatApplKernel<int=64, custatevec::CsComplex<float>, int=2, custatevec::EmptyBitInserter<int=2>>(float*, long, custatevec::HostMatrixArgument<custatevec::constMatApplKernel<int=64, custatevec::CsComplex<float>, int=2, custatevec::EmptyBitInserter<int=2>>, custatevec::CsComplex<float>>, int=2, custatevec::TargetBitArray<custatevec::CsComplex<float>>)
6.49% 3.8080us 1 3.8080us 3.8080us 3.8080us void cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<long, cub::NullType, unsigned int>::Policy800, bool=0, long, cub::NullType, unsigned int>(unsigned int const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<long, cub::NullType, unsigned int>::Policy800, bool=0, long, cub::NullType, unsigned int>*, cub::DeviceRadixSortPolicy<long, cub::NullType, unsigned int>::Policy800 const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<long, cub::NullType, unsigned int>::Policy800, bool=0, long, cub::NullType, unsigned int>**, bool=0, int, int)
5.29% 3.1040us 2 1.5520us 1.3760us 1.7280us [CUDA memcpy DtoH]
4.64% 2.7200us 1 2.7200us 2.7200us 2.7200us custatevec::_GLOBAL__N__2d201eb2_15_naiveSampler_cu_a2447900::sampleKernel(double const *, unsigned int, long, double, double const *, double const *, long, custatevec::BitPermutation<int=56> const &, long*)
2.40% 1.4070us 1 1.4070us 1.4070us 1.4070us [CUDA memcpy DtoD]
2.18% 1.2800us 1 1.2800us 1.2800us 1.2800us [CUDA memset]
2.07% 1.2150us 1 1.2150us 1.2150us 1.2150us _ZN10custatevec15transformKernelIZNS_7Sampler6sampleER17custatevecContextPlRKNS_17ConstPointerArrayIiEEPKdj25custatevecSamplerOutput_tEUllE_EEvT_ll
API calls: 78.70% 77.993ms 24 3.2497ms 365ns 77.952ms cudaSetDevice
15.01% 14.870ms 9 1.6522ms 3.7330us 11.715ms cudaFree
3.35% 3.3208ms 7 474.40us 6.1400us 1.8814ms cudaLaunchKernel
1.01% 1.0033ms 894 1.1220us 106ns 69.024us cuDeviceGetAttribute
0.60% 591.70us 1 591.70us 591.70us 591.70us cudaFuncGetAttributes
0.30% 294.50us 1156 254ns 117ns 28.017us cuGetProcAddress
0.24% 241.16us 2 120.58us 118.86us 122.30us cudaGetDeviceProperties
0.23% 227.60us 6 37.933us 2.9740us 78.188us cudaMalloc
0.21% 210.56us 1 210.56us 210.56us 210.56us cudaGetSymbolAddress
0.08% 76.766us 6 12.794us 7.0950us 14.465us cudaMemcpyAsync
0.05% 47.590us 8 5.9480us 2.7780us 11.755us cuDeviceGetName
0.04% 40.766us 22 1.8530us 231ns 10.119us cudaGetDevice
0.03% 26.450us 19 1.3920us 360ns 13.476us cudaEventCreateWithFlags
0.02% 19.417us 2 9.7080us 5.0390us 14.378us cudaMemcpy
0.01% 14.769us 1 14.769us 14.769us 14.769us cudaMemset
0.01% 14.649us 9 1.6270us 466ns 4.7300us cudaPointerGetAttributes
0.01% 13.839us 2 6.9190us 2.6740us 11.165us cudaStreamSynchronize
0.01% 13.305us 2 6.6520us 2.0260us 11.279us cudaStreamCreate
0.01% 13.086us 20 654ns 394ns 2.6680us cudaEventDestroy
0.01% 12.275us 2 6.1370us 2.5440us 9.7310us cudaStreamDestroy
0.01% 10.659us 39 273ns 100ns 4.9440us cudaGetLastError
0.01% 9.8780us 4 2.4690us 1.0810us 4.5180us cudaDeviceSynchronize
0.01% 8.6500us 2 4.3250us 1.8390us 6.8110us cuDeviceGetPCIBusId
0.01% 5.9160us 16 369ns 232ns 1.3640us cudaDeviceGetAttribute
0.00% 4.7430us 3 1.5810us 1.0890us 2.4190us cuInit
0.00% 4.1090us 8 513ns 208ns 914ns cuDeviceTotalMem
0.00% 2.2900us 10 229ns 113ns 465ns cuDeviceGet
0.00% 1.9400us 8 242ns 136ns 799ns cuDeviceGetUuid
0.00% 1.5700us 1 1.5700us 1.5700us 1.5700us cudaEventCreate
0.00% 1.3290us 6 221ns 149ns 481ns cuDeviceGetCount
0.00% 1.1760us 4 294ns 175ns 601ns cudaPeekAtLastError
0.00% 821ns 4 205ns 173ns 241ns cuModuleGetLoadingMode
0.00% 506ns 2 253ns 232ns 274ns cudaGetDeviceCount
0.00% 495ns 3 165ns 158ns 169ns cuDriverGetVersion
(cuquantum-24.03) cuquantum@be5c9947460c:~/examples$
$ nvprof python ./hidden_shift.py
(cuquantum-24.03) cuquantum@be5c9947460c:~/examples$ nvprof python ./hidden_shift.py
==2475== NVPROF is profiling process 2475, command: python ./hidden_shift.py
Secret shift sequence: [1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1]
Circuit:
(0, 0): ────H───X───@───X───H───@───H───M('result')───
│ │ │
(1, 0): ────H───────@───H───────@───H───M─────────────
│
(2, 0): ────H───X───@───X───H───@───H───M─────────────
│ │ │
(3, 0): ────H───────@───H───────@───H───M─────────────
│
(4, 0): ────H───────@───H───────@───H───M─────────────
│ │ │
(5, 0): ────H───X───@───X───H───@───H───M─────────────
│
(6, 0): ────H───X───@───X───H───@───H───M─────────────
│ │ │
(7, 0): ────H───────@───H───────@───H───M─────────────
│
(8, 0): ────H───────@───H───────@───H───M─────────────
│ │ │
(9, 0): ────H───X───@───X───H───@───H───M─────────────
│
(10, 0): ───H───X───@───X───H───@───H───M─────────────
│ │ │
(11, 0): ───H───X───@───X───H───@───H───M─────────────
Sampled results:
Counter({'101001100111': 100})
Most common bitstring: 101001100111
Found a match: True
==2475== Profiling application: python ./hidden_shift.py
==2475== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 41.65% 53.403us 1 53.403us 53.403us 53.403us custatevec::_GLOBAL__N__2d201eb2_15_naiveSampler_cu_a2447900::intervalCumulativeSumKernel(double*, int)
22.96% 29.437us 1 29.437us 29.437us 29.437us void cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800, bool=0, double, int, unsigned int>(unsigned int const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800, bool=0, double, int, unsigned int>*, cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800 const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800, bool=0, double, int, unsigned int>**, bool=0, int, int)
5.29% 6.7830us 5 1.3560us 1.0560us 1.8230us [CUDA memcpy HtoD]
4.99% 6.3990us 3 2.1330us 1.9200us 2.3350us void custatevec::constMatApplKernel_Relocate<int=64, custatevec::CsComplex<float>, int=2, custatevec::EmptyBitInserter<int=2>, int=8>(float*, custatevec::HostMatrixArgument<custatevec::constMatApplKernel_Relocate<int=64, custatevec::CsComplex<float>, int=2, custatevec::EmptyBitInserter<int=2>, int=8>, custatevec::CsComplex<float>>, int=2, custatevec::TargetBitArray<custatevec::CsComplex<float>>, custatevec::TargetRelocator<int=2, custatevec::CsComplex<float>>)
4.72% 6.0480us 1 6.0480us 6.0480us 6.0480us void cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<long, cub::NullType, unsigned int>::Policy800, bool=0, long, cub::NullType, unsigned int>(unsigned int const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<long, cub::NullType, unsigned int>::Policy800, bool=0, long, cub::NullType, unsigned int>*, cub::DeviceRadixSortPolicy<long, cub::NullType, unsigned int>::Policy800 const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<long, cub::NullType, unsigned int>::Policy800, bool=0, long, cub::NullType, unsigned int>**, bool=0, int, int)
4.34% 5.5670us 1 5.5670us 5.5670us 5.5670us custatevec::_GLOBAL__N__2d201eb2_15_naiveSampler_cu_a2447900::sampleKernel(double const *, unsigned int, long, double, double const *, double const *, long, custatevec::BitPermutation<int=56> const &, long*)
4.24% 5.4390us 1 5.4390us 5.4390us 5.4390us _ZN10custatevec48_GLOBAL__N__2d201eb2_15_naiveSampler_cu_a244790028blockwiseCumulativeSumKernelIZNS0_26calculateCumulativeAbs2SumINS_9CsComplexIfEEEEvPKT_iRNS_18WorkspaceAllocatorEP11CUstream_stPdEUllE_EEvS5_lSC_
4.24% 5.4390us 3 1.8130us 1.7920us 1.8240us void custatevec::constMatApplLoopKernel<int=64, int=1, custatevec::CsComplex<float>, int=2, custatevec::EmptyBitInserter<int=2>>(float*, custatevec::HostMatrixArgument<custatevec::constMatApplLoopKernel<int=64, int=1, custatevec::CsComplex<float>, int=2, custatevec::EmptyBitInserter<int=2>>, custatevec::CsComplex<float>>, int=2, custatevec::TargetBitArray<custatevec::CsComplex<float>>)
2.47% 3.1680us 2 1.5840us 1.4080us 1.7600us [CUDA memcpy DtoH]
1.67% 2.1440us 1 2.1440us 2.1440us 2.1440us [CUDA memset]
1.35% 1.7280us 1 1.7280us 1.7280us 1.7280us custatevec::_GLOBAL__N__2d201eb2_15_naiveSampler_cu_a2447900::applyPrevCumsumKernel(double*, long)
1.10% 1.4080us 1 1.4080us 1.4080us 1.4080us [CUDA memcpy DtoD]
0.97% 1.2480us 1 1.2480us 1.2480us 1.2480us _ZN10custatevec15transformKernelIZNS_7Sampler6sampleER17custatevecContextPlRKNS_17ConstPointerArrayIiEEPKdj25custatevecSamplerOutput_tEUllE_EEvT_ll
API calls: 78.80% 76.443ms 28 2.7301ms 351ns 76.390ms cudaSetDevice
15.29% 14.828ms 9 1.6476ms 3.0460us 11.683ms cudaFree
1.93% 1.8769ms 1 1.8769ms 1.8769ms 1.8769ms cudaFuncGetAttributes
1.51% 1.4641ms 13 112.62us 4.0570us 1.0059ms cudaLaunchKernel
1.05% 1.0185ms 894 1.1390us 107ns 60.991us cuDeviceGetAttribute
0.27% 262.48us 1156 227ns 115ns 1.5530us cuGetProcAddress
0.24% 232.01us 2 116.01us 113.30us 118.71us cudaGetDeviceProperties
0.24% 230.85us 6 38.475us 2.9520us 81.170us cudaMalloc
0.21% 206.58us 1 206.58us 206.58us 206.58us cudaGetSymbolAddress
0.15% 145.30us 6 24.216us 7.0990us 46.920us cudaMemcpyAsync
0.05% 45.538us 8 5.6920us 2.8540us 11.606us cuDeviceGetName
0.04% 39.664us 22 1.8020us 238ns 11.700us cudaGetDevice
0.03% 32.140us 1 32.140us 32.140us 32.140us cudaMemset
0.03% 26.795us 21 1.2750us 357ns 9.1970us cudaPointerGetAttributes
0.02% 21.216us 19 1.1160us 371ns 10.852us cudaEventCreateWithFlags
0.02% 20.466us 2 10.233us 5.4000us 15.066us cudaMemcpy
0.02% 20.445us 39 524ns 102ns 11.355us cudaGetLastError
0.02% 15.262us 20 763ns 410ns 3.5490us cudaEventDestroy
0.01% 13.969us 2 6.9840us 3.2660us 10.703us cudaStreamDestroy
0.01% 13.245us 2 6.6220us 1.9790us 11.266us cudaStreamCreate
0.01% 10.542us 2 5.2710us 2.5070us 8.0350us cudaStreamSynchronize
0.01% 9.0670us 4 2.2660us 1.1500us 3.9240us cudaDeviceSynchronize
0.01% 7.4570us 2 3.7280us 1.3670us 6.0900us cuDeviceGetPCIBusId
0.01% 5.9220us 16 370ns 265ns 1.2850us cudaDeviceGetAttribute
0.00% 4.3070us 3 1.4350us 1.0770us 1.9440us cuInit
0.00% 2.5300us 10 253ns 104ns 1.0290us cuDeviceGet
0.00% 2.0550us 8 256ns 147ns 416ns cuDeviceTotalMem
0.00% 1.8860us 4 471ns 372ns 683ns cudaPeekAtLastError
0.00% 1.6140us 1 1.6140us 1.6140us 1.6140us cudaEventCreate
0.00% 1.5720us 6 262ns 153ns 689ns cuDeviceGetCount
0.00% 1.4170us 8 177ns 133ns 259ns cuDeviceGetUuid
0.00% 1.0910us 2 545ns 332ns 759ns cudaGetDeviceCount
0.00% 774ns 4 193ns 137ns 248ns cuModuleGetLoadingMode
0.00% 468ns 3 156ns 150ns 163ns cuDriverGetVersion
(cuquantum-24.03) cuquantum@be5c9947460c:~/examples$ $ nvprof python ./simon.py
(cuquantum-24.03) cuquantum@be5c9947460c:~/examples$ nvprof python ./simon.py
==2559== NVPROF is profiling process 2559, command: python ./simon.py
Secret string = [0 1 0]
Circuit:
┌───┐ ┌──┐
(0, 0): ───H────@───────H─────────M('result')───
│ │
(1, 0): ───H────┼@──────@─────H───M─────────────
││ │ │
(2, 0): ───H────┼┼@─────┼H────────M─────────────
│││ │
(3, 0): ────────X┼┼─────┼×──────────────────────
││ ││
(4, 0): ─────────X┼─────X┼──────────────────────
│ │
(5, 0): ──────────X──────×──────────────────────
└───┘ └──┘
Most common answer was : ('[0 1 0]', 100)
==2559== Profiling application: python ./simon.py
==2559== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 46.93% 7.9627ms 276 28.850us 28.606us 29.470us void cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800, bool=0, double, int, unsigned int>(unsigned int const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800, bool=0, double, int, unsigned int>*, cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800 const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<double, int, unsigned int>::Policy800, bool=0, double, int, unsigned int>**, bool=0, int, int)
12.35% 2.0960ms 1104 1.8980us 1.6640us 2.3350us void custatevec::constMatApplKernel<int=64, custatevec::CsComplex<float>, int=2, custatevec::EmptyBitInserter<int=2>>(float*, long, custatevec::HostMatrixArgument<custatevec::constMatApplKernel<int=64, custatevec::CsComplex<float>, int=2, custatevec::EmptyBitInserter<int=2>>, custatevec::CsComplex<float>>, int=2, custatevec::TargetBitArray<custatevec::CsComplex<float>>)
10.28% 1.7437ms 1380 1.2630us 1.0230us 2.0800us [CUDA memcpy HtoD]
8.32% 1.4108ms 276 5.1110us 5.0550us 5.2470us _ZN10custatevec48_GLOBAL__N__2d201eb2_15_naiveSampler_cu_a244790028blockwiseCumulativeSumKernelIZNS0_26calculateCumulativeAbs2SumINS_9CsComplexIfEEEEvPKT_iRNS_18WorkspaceAllocatorEP11CUstream_stPdEUllE_EEvS5_lSC_
6.07% 1.0299ms 276 3.7310us 3.6790us 3.8400us void cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<long, cub::NullType, unsigned int>::Policy800, bool=0, long, cub::NullType, unsigned int>(unsigned int const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<long, cub::NullType, unsigned int>::Policy800, bool=0, long, cub::NullType, unsigned int>*, cub::DeviceRadixSortPolicy<long, cub::NullType, unsigned int>::Policy800 const *, cub::DeviceRadixSortSingleTileKernel<cub::DeviceRadixSortPolicy<long, cub::NullType, unsigned int>::Policy800, bool=0, long, cub::NullType, unsigned int>**, bool=0, int, int)
5.35% 907.08us 276 3.2860us 3.2310us 3.5200us custatevec::_GLOBAL__N__2d201eb2_15_naiveSampler_cu_a2447900::sampleKernel(double const *, unsigned int, long, double, double const *, double const *, long, custatevec::BitPermutation<int=56> const &, long*)
4.16% 705.46us 552 1.2780us 1.1510us 1.6950us [CUDA memcpy DtoH]
2.30% 390.33us 276 1.4140us 1.2800us 1.5350us [CUDA memset]
2.24% 380.11us 276 1.3770us 1.3430us 1.4400us [CUDA memcpy DtoD]
2.00% 340.07us 276 1.2320us 1.1830us 1.2810us _ZN10custatevec15transformKernelIZNS_7Sampler6sampleER17custatevecContextPlRKNS_17ConstPointerArrayIiEEPKdj25custatevecSamplerOutput_tEUllE_EEvT_ll
API calls: 23.28% 86.005ms 6626 12.979us 356ns 77.873ms cudaSetDevice
18.26% 67.458ms 2209 30.537us 617ns 11.727ms cudaFree
17.00% 62.811ms 1656 37.929us 2.8550us 94.336us cudaMalloc
16.76% 61.944ms 552 112.22us 102.57us 133.54us cudaGetDeviceProperties
8.29% 30.642ms 2484 12.335us 3.6740us 1.8943ms cudaLaunchKernel
7.55% 27.890ms 1656 16.841us 4.7660us 416.00us cudaMemcpyAsync
1.07% 3.9504ms 552 7.1560us 5.0270us 17.266us cudaMemcpy
1.03% 3.7977ms 9939 382ns 100ns 490.27us cudaGetLastError
1.01% 3.7487ms 4140 905ns 331ns 24.341us cudaPointerGetAttributes
0.99% 3.6644ms 4972 737ns 231ns 12.264us cudaGetDevice
0.74% 2.7287ms 5520 494ns 310ns 76.789us cudaEventDestroy
0.72% 2.6553ms 5244 506ns 346ns 12.715us cudaEventCreateWithFlags
0.62% 2.2923ms 552 4.1520us 1.4640us 37.640us cudaStreamCreate
0.52% 1.9392ms 276 7.0260us 6.2760us 20.021us cudaMemset
0.51% 1.8667ms 552 3.3810us 1.6160us 14.254us cudaStreamDestroy
0.42% 1.5343ms 1104 1.3890us 814ns 10.198us cudaDeviceSynchronize
0.34% 1.2702ms 552 2.3010us 1.5970us 11.166us cudaStreamSynchronize
0.27% 1.0103ms 894 1.1300us 106ns 61.499us cuDeviceGetAttribute
0.27% 1.0098ms 1 1.0098ms 1.0098ms 1.0098ms cudaFuncGetAttributes
0.10% 386.38us 1104 349ns 105ns 766ns cudaPeekAtLastError
0.09% 346.86us 276 1.2560us 1.0510us 6.8000us cudaEventCreate
0.07% 266.56us 1156 230ns 115ns 1.3930us cuGetProcAddress
0.06% 204.05us 1 204.05us 204.05us 204.05us cudaGetSymbolAddress
0.01% 46.269us 8 5.7830us 2.7020us 11.757us cuDeviceGetName
0.00% 7.5370us 2 3.7680us 1.4460us 6.0910us cuDeviceGetPCIBusId
0.00% 5.6830us 3 1.8940us 1.1150us 2.3370us cuInit
0.00% 5.3210us 16 332ns 239ns 971ns cudaDeviceGetAttribute
0.00% 2.9670us 6 494ns 179ns 1.7530us cuDeviceGetCount
0.00% 2.4640us 8 308ns 161ns 608ns cuDeviceTotalMem
0.00% 1.7730us 10 177ns 104ns 440ns cuDeviceGet
0.00% 1.3460us 8 168ns 127ns 217ns cuDeviceGetUuid
0.00% 1.2010us 2 600ns 400ns 801ns cudaGetDeviceCount
0.00% 942ns 4 235ns 161ns 367ns cuModuleGetLoadingMode
0.00% 474ns 3 158ns 148ns 169ns cuDriverGetVersion
(cuquantum-24.03) cuquantum@be5c9947460c:~/examples$
4, 官方cu语言调用 cuquantum 示例
将源代码下载到映射进 docker container 中的文件夹里,
下载示例源代码:
$ git clone https://github.com/NVIDIA/cuQuantum.git示例代码位置:
![]()
$ tree

















 1397
1397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









