







摘要
这项工作介绍了MLIR,这是一种构建可重用和可扩展编译器基础设施的新方法。MLIR解决软件碎片化、针对异构硬件的编译,显著降低了构建领域特定编译器的成本,并将现有编译器连接在一起。
MLIR促进了在不同抽象层次和跨多个应用领域、多个硬件目标和多个执行环境时,代码生成器、翻译器和优化器的设计和实现。本文的贡献包括:
(1) 讨论 MLIR 作为一个研究工作,旨在扩展和演化,同时识别这种新颖的 “设计、语义、优化规范、系统和工程” 所带来的挑战和机遇。
(2) 评估 MLIR 作为一种通用基础设施,在降低构建编译器的成本——描述多样化的用例中,展示MLIR 赋予未来的 “编程语言、编译器、执行环境和计算机架构” 上的研究和教育的机会。本文还介绍了MLIR的基本原理、原始设计原则、结构和语义。
I. 引言
编译器设计是一个成熟的领域,应用于代码生成、静态分析等。该领域已经开发出许多成熟的技术平台,使得大规模重用成为可能,包括LLVM编译器基础设施、Java虚拟机(JVM)等。一个共同的特征是它们的“一刀切”方法——与系统接口的单一抽象层次:LLVM中间表示(IR)大致是“带有向量的C”,而JVM提供了“带有垃圾回收器的面向对象类型系统”抽象。这种“一刀切”的方法非常有价值——在实践中,从无处不在的源语言(分别是C/C++和Java)到这些领域的映射是直接的。
然而,许多问题在更高或更低的抽象层次上建模效果更好,例如在LLVM IR上进行C++代码的源码级分析非常困难。我们观察到,许多语言(包括Swift、Rust、Julia、Fortran)开发了自己的IR,以解决领域特定的问题,如语言/库特定的优化、流敏感类型检查(例如线性类型)以及改进编译下降过程的实现。类似地,机器学习系统通常使用“ML图”作为领域特定的抽象。
尽管领域特定IR的开发是一门研究得很透彻的艺术,但它们的工程和实现成本仍然很高。很多时候,对于这些系统的实现者来说,基础设施的质量并不总是首要任务(或容易证明其合理性)。因此,这可能导致较低质量的编译器系统,包括明显影响用户体验的问题,如编译时间慢、实现有错误、诊断质量不佳、被优化了的代码的调试体验差等。
MLIR 项目旨在直接解决这些编程语言设计和实现的挑战——通过使定义和引入新的抽象层次,使上述工程开发成本变得很低,并提供 “开箱即用” 的基础设施来解决常见的编译器工程问题。MLIR通过以下方式实现这一目标:
(1) 标准化基于静态单赋值(SSA)的 IR 数据结构;
(2) 提供一个声明性系统来定义IR方言;
(3) 提供广泛的通用基础设施,包括文档、解析和打印逻辑、位置跟踪、多线程编译的支持、pass 管理等。
本文进一步介绍了 涵盖 MLIR 设计和实现的总体原则。我们将探讨系统的基本设计要点及其与总体原则的关系,并且分享我们在应用 MLIR 于多个编译问题时的经验。
A. 贡献
MLIR系统的大部分是由众所周知的概念和算法构建的。然而,其目标和设计足够的新颖,以至于钻研它们的话能够获得广阔的科研机会,尤其是在以下总体原则的范围内:
简约性:应用奥卡姆剃刀原则于内置的 “语义、概念和编程接口” 的定义之上。通过对 操作和类型的属性的抽象,来连接内在和附带的复杂性。对于不变量,就指定一次,但在整个过程中都会验证其正确性。在给定的编译 pass 的上下文中查询属性。因为内置的事物很少,这为可扩展性和定制化打开了大门。
可追溯性:保留原始信息而不是通过逆向运算来恢复信息。声明规则和属性使转换成为可能,而不是逐步的命令式规范。可扩展性伴随着通用的方法来追踪信息,通过广泛的验证来强制执行。可组合的抽象源于“玻璃盒化”它们的属性并分离它们的角色——类型、控制、数据流等。
渐进性:过早的降低是万恶之源。超越表示层,允许多个转换路径按需降低个别区域。结合与抽象无关的原则和接口,这使得跨多个领域的重用成为可能。
虽然这些原则已经确立,但通常一个原则的实现会以牺牲另一个原则为代价;例如,网络和操作系统堆栈中的分层与渐进性原则一致,但破坏了简约性。这在具有多个IR层的编译器中也是如此。此外,遵循这些原则可能会损害表达性和有效性;例如,在安全关键和安全系统中,可追溯性涉及限制优化及其激进性。
简而言之,我们识别出编译器构建的设计和工程原则,以在支持开放语义生态系统的狭窄中间地带中蓬勃发展。我们发现可以在不限制表达性的情况下驯服复杂性,从而允许快速的IR设计探索和跨领域的整合,这在生产系统中严重缺乏。
本文的贡献是:(1) 从经过验证的设计和工程原则的角度定位构建可扩展和模块化编译器系统的问题;(2) 描述遵循这些原则的新型编译器基础设施,具有重要的工业和研究应用;(3) 探索不同领域的选定应用,说明方法的通用性,并分享基于MLIR基础设施开发系统的经验。
B. MLIR的起源
MLIR的工作始于意识到现代机器学习框架由许多不同的编译器、图技术和运行时系统组成——它们没有共享一个共同的基础设施或设计原则。这在多个用户可见的方面表现出来,包括错误信息不佳、边缘情况失败、性能不可预测以及难以将堆栈推广以支持新硬件。
我们很快意识到,整个编译器行业也面临类似的问题:现有系统(如LLVM)在统一和集成跨多种不同语言的工作方面非常成功,但高级语言通常最终构建自己的高级IR,并为更高层次的抽象重新发明相同类型的技术。
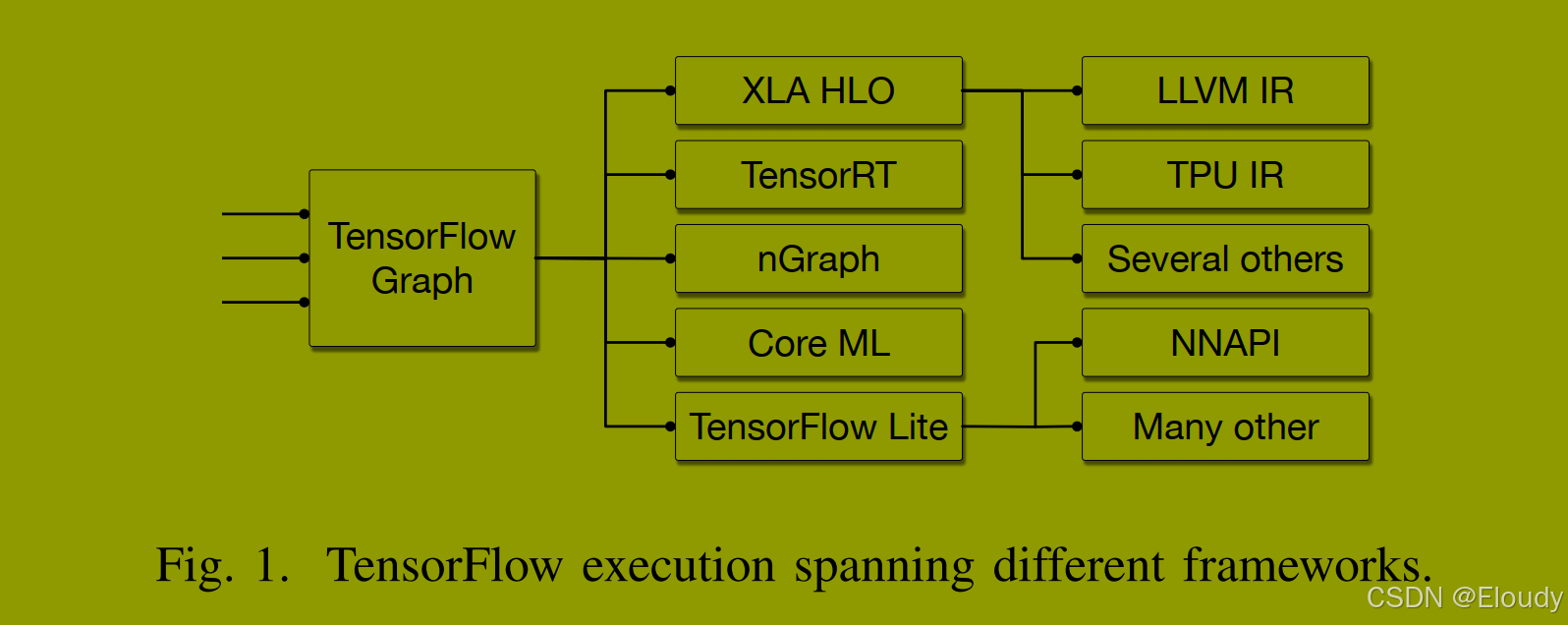
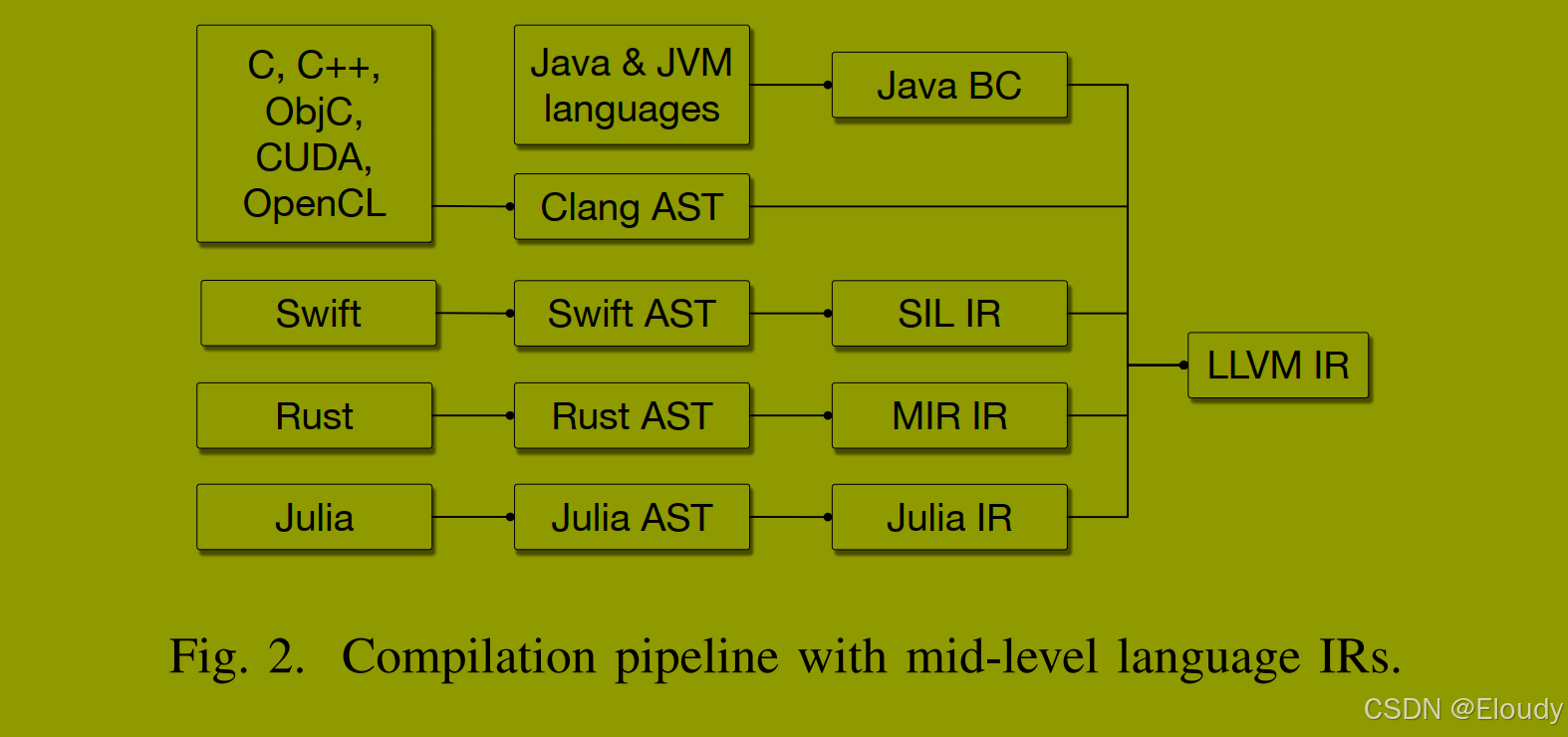
同时,LLVM社区在表示并行构造和共享前端降低基础设施(例如C调用约定或跨语言特性如OpenMP)方面遇到了困难,没有令人满意的解决方案。
面对这一挑战,鉴于我们无法负担实施N个改进的编译器实例,我们决定选择一个更通用的解决方案:投资于一个高质量的基础设施,这将使多个领域受益,逐步升级现有系统,使得更容易解决诸如专用加速器的异构编译等紧迫问题,并提供新的研究机会。现在,我们已经积累了大量基于MLIR的系统构建和部署经验,我们能够回顾其原理和设计,并讨论为什么选择了这个方向。
II. 设计原则
现在让我们探讨指导MLIR设计的要求及其与总体原则的关系。
少量内置,万物可定制 [简约性]:系统基于少量基本概念,留下大部分中间表示完全可定制。少数抽象——类型、操作和属性,这是IR中最常见的——应该用于表达其他所有内容,允许更少且更一致的抽象,易于理解、扩展和采用。广泛地说,可定制性确保系统可以适应不断变化的需求,并更有可能适用于未来的问题。从这个意义上说,我们应该将IR构建为一个丰富的基础设施,具有可重用的组件和编程抽象,支持其中间语言的语法和语义。
定制化的成功标准是能够表达多样化的抽象集,包括机器学习图、AST、数学抽象如多面体、控制流图(CFG)和指令级IR如LLVM IR,所有这些都无需将这些抽象的概念硬编码到系统中。
当然,定制化会因不兼容的抽象而带来内部碎片化的风险。虽然不太可能有纯粹的技术解决方案,但系统应该鼓励设计可重用的抽象,并假设它们将在其初始范围之外使用。
SSA和区域 [简约性]:静态单赋值(SSA)形式是编译器IR中广泛使用的表示。它提供了许多优点,包括使数据流分析简单和稀疏,被编译器社区广泛理解,因为它与续传风格的关系,并在主要框架中建立。因此,IR强制执行SSA的基于值的语义、其引用透明性和算法效率,所有这些都被认为是现代编译器基础设施的必要条件。然而,虽然许多现有IR使用平坦的线性化CFG,但表示更高级别的抽象推动在IR中引入嵌套区域作为一等概念。这超越了传统的区域形成,以提升更高级别的抽象(例如,循环树),加速编译过程或提取指令或SIMD并行性。为了支持异构编译,系统必须支持结构化控制流、并发构造、源语言中的闭包等多种用途。一个具体的挑战是使基于CFG的分析和转换能够在嵌套区域上组合。
在这样做时,我们同意牺牲LLVM的规范化,有时是规范化属性。能够将各种数据和控制结构降低为较小的规范化表示集合是控制编译器复杂性的关键。具有其预标头、标头、锁存、主体的规范循环结构是前端语言中各种循环构造的线性化控制流表示的原型案例。我们的目标是为用户提供选择:根据感兴趣的编译算法,在编译流程中,嵌套循环可以被捕获为嵌套区域,或作为线性化控制流。通过提供这样的选择,我们偏离了LLVM的仅规范化导向,同时保留了在需要时处理更高级别抽象的能力。反过来,利用这样的选择引发了关于如何控制抽象的规范化的问题,这是下一段的目的。
保持高级语义 [渐进性]:系统需要保留分析或优化性能所需的信息和结构。一旦降低,尝试恢复抽象语义是脆弱的,并且在低级别强行插入这些信息通常是侵入性的(例如,在使用调试信息记录结构的情况下,所有传递都需要重新审视)。相反,系统应该保持计算的结构,并逐步降低到硬件抽象。结构的丧失是有意识的,并且仅在不再需要结构以匹配底层执行模型时发生。例如,系统应在相关转换中保留结构化控制流,如循环结构;移除此结构,即降低到CFG,基本上意味着不会执行进一步利用结构的转换。生产编译器中建模并行计算构造的最新技术突显了任务在一般情况下可能有多困难。
作为推论,在同一IR中混合不同级别的抽象和不同的概念是允许表示的一部分保持在更高级别抽象而另一部分被降低的关键。这将使得,例如,自定义加速器的编译器能够重用系统定义的一些高级结构和抽象,以及特定于加速器的原始标量/向量指令。
另一个推论是,系统应支持渐进降低,从更高级别的表示到最低级别,沿着多个抽象以小步骤进行。需要多个抽象级别源于编译器基础设施必须支持的平台和编程模型的多样性。
以前的编译器已经在其管道中引入了多个固定的抽象级别——例如,Open64 WHIRL表示有五个级别,Clang编译器也是如此,它从AST降低到LLVM IR,再到SelectionDAG,再到MachineInstr,再到MCInst。需要更灵活的设计来支持可扩展性。这对转换的阶段排序有深远的影响。随着编译器专家开始实现越来越多的转换传递,这些传递之间的复杂交互开始出现。早期就显示出结合优化传递可以让编译器发现更多关于程序的事实。结合传递的好处之一的最早例子是混合常量传播、值编号和不可达代码消除。
声明和验证 [简约性和可追溯性]:定义表示修饰符应该像引入新抽象一样简单;编译器基础设施的好坏取决于它支持的转换。常见的转换应可实现为以声明性格式表达的重写规则,以便机器分析重写的属性,如复杂性和完成度。重写系统已被广泛研究其健全性和效率,并应用于从类型系统到指令选择的众多编译问题。由于我们旨在实现前所未有的可扩展性和增量降低能力,这为将程序转换建模为重写系统开辟了许多途径。
这也引发了关于如何表示重写规则和策略以及如何构建能够通过多个抽象层次引导重写策略的机器描述的有趣问题。系统需要在保持可扩展性和强制执行单调和可重复行为的同时解决这些问题。
生态系统的开放性也要求广泛的验证机制。虽然验证和测试对于检测编译器错误和捕获IR不变量是有用的,但在可扩展系统中对健全的验证方法和工具的需求被放大。机制应旨在使其易于定义并尽可能声明化,提供单一的真相来源。长期目标是重现翻译验证和现代编译器测试方法的成功。在可扩展编译器的背景下,这两个问题目前都是开放问题。
源位置跟踪 [可追溯性]:操作的来源——包括其原始位置和应用的转换——应在系统中易于追踪。这旨在解决复杂编译系统中常见的缺乏透明性问题,在这些系统中,几乎不可能理解最终表示是如何从原始表示构建的。
这在编译安全关键和敏感应用程序时尤其成问题,其中跟踪降低和优化步骤是软件认证程序的一个重要组成部分。当在安全代码(如加密协议或在隐私敏感数据上操作的算法)上操作时,编译器通常会面临看似冗余或繁琐的计算,这些计算嵌入了源程序功能语义未完全捕获的安全或隐私属性:此代码可能会防止侧信道的暴露或增强代码对网络或故障攻击的防护。优化可能会改变或完全无效化这些保护;这种缺乏透明性在安全编译中被称为WYSINWYX。准确地将高层信息传播到较低层次的一个间接目标是帮助支持安全和可追溯的编译。
III. IR设计
我们的主要贡献是提出一个遵循前一节定义的原则的IR。这就是MLIR所做的,我们在本节中回顾其主要设计点。MLIR具有通用的文本表示(图3中的示例),支持MLIR的可扩展性,并完全反映内存中的表示,这对于可追溯性、手动IR验证和测试至关重要。可扩展性带来了冗长的负担,可以通过MLIR支持的自定义语法来补偿;例如,图7展示了用户定义的语法。
操作:MLIR中的语义单位是“操作”,简称为Op。从“指令”到“函数”再到“模块”中的一切都在这个系统中建模为Ops。MLIR没有固定的Ops集,但根据简约性和“万物可定制”原则,允许(并鼓励)用户定义扩展。基础设施提供了基于TableGen的声明性语法来定义Ops。


Ops具有唯一的操作码,一个标识操作及其方言的字符串。Ops接收和产生零个或多个值,分别称为操作数和结果,并以SSA形式维护。这些值表示运行时的数据,并具有编码数据编译时知识的类型。除了操作码、操作数和结果外,Ops还可能具有属性、区域、后继块和位置信息。图3展示了值和Ops,%标识符是(包的)命名值,如果多于一个则用“:”指定数量,若为特定值则用“#”。在通用文本表示中,操作名称是带引号的字符串字面量,后跟括号中的操作数。
编译器传递保守地处理未知的Ops,MLIR具有丰富的支持,通过特征和接口描述Ops的语义。Op实现具有验证器,用于强制执行Op不变量并参与整体IR验证。

属性:MLIR属性包含关于操作的编译时信息,除了操作码。属性是类型化的(例如,整数、字符串),每个Op实例都有一个从字符串名称到属性值的开放键值字典。在通用语法中,属性位于大括号括起来的逗号分隔的对。图3使用属性来定义已知为常数仿射形式的循环边界:{lower_bound = () -> (0), step = 1 : index, upper_bound = #map3},其中lower_bound是属性名称的一个示例。() -> (0)表示法用于内联仿射形式,在这种情况下生成一个仿射函数,产生一个常数0值。#map3表示属性别名,允许提前将属性值与标签关联。
属性的含义要么来自与之关联的Op语义,要么来自与之关联的方言。与操作码一样,没有固定的属性集。属性可能引用外部数据结构,这对于与现有系统集成非常有用,例如ML系统中(在编译时已知的)数据存储的内容。
位置信息:MLIR提供了一个紧凑的位置信息表示,并鼓励在整个系统中处理和传播此信息,遵循可追溯性原则。它可用于保留生成Op的源程序堆栈跟踪,以生成调试信息。它标准化了从编译器发出诊断信息的方式,并被广泛的测试工具使用。位置信息也是可扩展的,允许编译器引用现有的位置信息跟踪系统、高级AST节点、LLVM风格的文件-行-列地址、DWARF调试信息等。
区域和块:Op的实例可能附有一个区域列表。区域提供了MLIR中的嵌套机制:它包含一个块列表,每个块包含一个操作列表(可能包含进一步的区域)。与属性一样,区域的语义由其附加的操作定义,但区域内的块(如果多于一个)形成一个控制流图(CFG)。例如,图3中的affine.for操作是一个“for”循环,其边界表示为函数中需要不变的值的仿射映射。因此,循环具有静态控制流。类似地,affine.if是受仿射整数集限制的条件。循环和条件的主体是使用affine.load和affine.store的区域,以限制对周围循环迭代器的仿射形式的索引。这使得精确的仿射依赖分析成为可能,同时避免了从有损的低级表示中推断仿射形式的需要。
值的支配和可见性:Ops只能使用在作用域内的值,即根据SSA支配、嵌套和由包围操作施加的语义限制可见的值。如果它们遵循标准的SSA支配关系,控制保证在到达使用之前通过定义,则值在CFG中是可见的。
基于区域的可见性是基于简单的区域嵌套定义的:如果Op的操作数在当前区域之外,则它必须在使用的区域之上和之外定义。这就是允许affine.for操作中的Ops使用在外部作用域中定义的值的原因。
MLIR还允许将操作定义为从上方隔离,表示操作是一个作用域屏障——例如,“std.func”Op定义了一个函数,并且在函数内的操作无效地引用在函数外定义的值。除了提供有用的语义检查外,包含从上方隔离Ops的模块可以由MLIR编译器并行处理,因为没有使用-定义链可以跨越隔离屏障。这对于利用多核机器进行编译很重要。
所有这些设计选择都强调了渐进性原则,而当一个概念看起来不够通用和必要以至于内置时,则倾向于简约性。
符号和符号表:Ops可以附有一个符号表。这个表是将名称(表示为字符串)与IR对象(称为符号)关联的标准化方式。IR不规定符号的用途,留给Op定义。符号对于不遵循SSA的命名实体最有用:它们不能在同一个表中重新定义,但可以在定义之前使用。例如,全局变量、函数或命名模块可以表示为符号。没有这个机制,就不可能定义,例如,在定义中引用自己的递归函数。如果附有符号表的Op有相关区域包含类似的Ops,则符号表可以嵌套。MLIR提供了一种从Op引用符号的机制,包括嵌套符号。
方言:MLIR使用方言管理可扩展性,方言在唯一命名空间下提供Ops、属性和类型的逻辑分组。方言本身不引入任何新语义,而是作为一种逻辑分组机制,提供通用的Op功能(例如,方言中所有Ops的常量折叠行为)。它们在遵循简约性原则的同时组织语言和领域特定语义的生态系统。方言命名空间在操作码中显示为点分隔的前缀,例如,图3使用仿射和标准方言。
将Ops、类型和属性分为方言是概念性的,类似于设计一组模块化库。例如,一个方言可以包含用于操作硬件向量的Ops和类型(例如,洗牌、插入/提取元素、掩码),另一个方言可以包含用于操作代数向量的Ops和类型(例如,绝对值、点积等)。这两个方言是否使用相同的向量类型以及该类型属于哪里是留给MLIR用户的设计决策。
虽然可以将所有Ops、类型和属性放在一个方言中,但由于同时存在的大量概念和名称冲突等问题,它很快就会变得难以管理。尽管每个Op、类型和属性都属于一个方言,但MLIR明确支持方言的混合以实现渐进降低。不同方言的Ops可以在IR的任何级别共存,它们可以使用在不同方言中定义的类型等。方言的混合允许更大的重用、可扩展性,并提供灵活性,否则将需要开发人员诉诸于各种不可组合的变通方法。
类型系统:MLIR中的每个值都有一个类型,该类型在生成值的Op中或在将值定义为参数的块中指定。类型编码了关于值的编译时信息。MLIR中的类型系统是用户可扩展的,例如,可以引用现有的外部类型系统。MLIR强制执行严格的类型相等性检查,并且不提供类型转换规则。Ops使用尾随函数样语法列出其输入和结果类型。在图3中,std.load从内存引用和索引类型映射到它加载的值的类型。
从类型理论的角度来看,MLIR仅支持非依赖类型,包括简单的、参数化的、函数、和积类型。虽然可以通过将Ops与符号和用户定义的类型结合来实现依赖类型系统,但这些类型对IR来说是不可见的。
为了方便起见,MLIR提供了一组标准化的常用类型,包括任意精度整数、标准浮点类型和简单的常见容器——元组、多维向量和张量。这些类型仅仅是一个工具,并不要求使用,说明了简约性。
函数和模块:与传统IR类似,MLIR通常被结构化为函数和模块。然而,这些在MLIR中不是独立的概念:它们作为内置方言中的Ops实现,再次说明了设计中的简约性。
模块是一个具有单个区域的Op,该区域包含一个单个块,并由一个不传递控制流的虚拟Op终止。像任何块一样,其主体包含一个Ops列表,这些Ops可能是函数、全局变量、编译器元数据或其他顶级构造。模块可以定义一个符号以便被引用。
类似地,函数是一个具有单个区域的Op,该区域可能包含零(在声明的情况下)或多个块。内置函数与“std”方言的“调用”和“返回”操作兼容,分别将控制转移到函数和从函数转移。其他方言可以自由定义自己的类似函数的Ops。
IV. 评估:MLIR的应用
MLIR是一个旨在推广和推动广泛编译器项目的系统,因此我们的主要评估指标是展示它正在被采用并用于各种项目。通过这样做,我们承认问题和贡献的软件工程性质。我们提供了社区活动的摘要,并详细描述了一些用例,以突出MLIR的通用性和可扩展性,并评估编译器和领域专家对IR设计原则的体验。
今天,MLIR是一个不断发展的开源项目,社区遍布学术界和工业界。例如,关于在高性能计算中使用MLIR的第一次学术研讨会有来自16所大学的个人参加,并涉及来自4个不同国家的4个国家实验室。MLIR还得到了14家跨国公司的支持,在2019年LLVM开发者会议上,超过100名行业开发者参加了关于MLIR的圆桌会议。社区的采用和参与是可用性和需求的代理度量。超过26个方言正在公共或私人开发中,跨不同公司的7个项目正在用MLIR替换自定义基础设施。我们认为这表明了对MLIR的真实需求,并认可了其可用性。
A. TensorFlow图
虽然其他讨论的表示对大多数编译器开发来说是熟悉的,但MLIR的一个关键用例是支持机器学习框架的开发。它们的内部表示通常基于具有动态执行语义的数据流图。
TensorFlow是此类框架的一个例子。其表示是一个高级数据流计算,其中节点是可以放置在各种设备上的计算,包括特定的硬件加速器。

MLIR用于TensorFlow中建模这种内部表示,并执行图1中展示的用例的转换:从简单的代数优化到重新定位图以在数据中心集群和异步硬件加速上进行并行和分布式执行,从降低到适合移动部署的表示到使用领域特定代码生成器(如XLA)生成高效的本机代码。图6中展示了在MLIR中表示的TensorFlow图。它展示了异步并发的建模,其中数据流图通过隐式未来去同步,副作用Ops通过显式控制信号序列化(也遵循数据流语义)。尽管抽象、并发、异步、延迟评估差异很大,MLIR提供了与任何其他方言或编译器传递相同的基础设施、分析和转换能力。特别是,Grappler中实现的基本图级转换可以在MLIR中表达用于TensorFlow模型和低级LLVM IR:死代码/节点消除、常量折叠、规范化、循环不变代码运动、公共子表达式/子图消除、指令/设备特定内核选择、重物化、布局优化;而其他转换可能是领域特定的:混合精度优化、操作融合、形状算术。
B. 多面体代码生成
MLIR的最初动机之一是探索加速器的多面体代码生成。仿射方言是一个简化的多面体表示,旨在实现渐进降低。虽然这里的设计点的全面探索超出了本文的范围,但我们通过展示仿射方言的方面来展示MLIR的建模能力,并将仿射方言与过去的表示进行对比。
1) 相似之处
MLIR仿射方言在所有内存访问上操作一个结构化的多维类型。在默认情况下,这些结构化类型是单射的:不同的索引通过构造保证不别名,这是多面体依赖分析的常见前提条件。
仿射建模分为两部分。属性用于在编译时建模仿射映射和整数集,Ops用于将仿射限制应用于代码。即,affine.for Op是一个“for”循环,其边界表示为函数中需要不变的值的仿射映射。因此,循环具有静态控制流。类似地,affine.if是受仿射整数集限制的条件。循环和条件的主体是使用affine.load和affine.store的区域,以限制对周围循环迭代器的仿射形式的索引。这使得精确的仿射依赖分析成为可能,同时避免了从有损的低级表示中推断仿射形式的需要。

2) 与现有多面体的差异
它们是众多的:
(1) 丰富的类型:MLIR结构化内存引用类型包含一个将缓冲区的索引空间连接到实际地址空间的布局映射。这种关注点的分离使得循环和数据转换更好地组合:数据布局的变化不会影响代码,也不会污染依赖分析。这样的转换混合以前已经被探索过,但并不常见。
(2) 抽象的混合:MLIR中仿射循环的主体可以用类型化的SSA值上的操作来表示。因此,所有传统的编译器分析和转换仍然适用,并且可以与多面体转换交错进行。相反,多面体编译器通常完全抽象掉这些细节,使得多面体编译器难以操作,例如,向量类型。
(3) 更小的表示差距:多面体模型的一个关键特征是其能够在类型系统中表示循环迭代的顺序。在这个系统中,大量的循环转换可以直接组合,并且可以使用简单的数学抽象进行推理。然而,多面体转换需要提升到通常与原始表示截然不同的表示。此外,从转换后的多面体到循环的转换在计算上是困难的。基于MLIR的表示保持了低级表示周围的高级循环结构,消除了提升的需要。
(4) 编译速度是MLIR的一个关键目标,但大多数现有的多面体方法并未关注这一点。这些方法严重依赖于具有指数复杂度的算法:在整数线性规划上自动推导循环排序,并在多面体扫描算法上将表示转换回循环。MLIR方法明确不依赖于多面体扫描,因为循环在IR中得以保留。此外,代码生成可以提前进行,例如在为动态形状生成通用代码时,或者在为静态形状的张量操作进行专门化时即时进行。后者对可用资源施加了更严格的约束,这两种情况都很重要。
对仿射方言的经验表明,一等仿射抽象有助于领域特定代码生成器的设计和实现,包括linalg方言和RISE中的声明性重写规则。这些发展和仿射方言本身代表了MLIR设计使之成为现实的重要探索。
C. Fortran IR (FIR)
LLVM Fortran前端“flang”目前正在由NVIDIA/PGI主导进行重大开发。与Swift、Rust和其他语言类似,flang需要一个专门的IR,以支持高性能Fortran代码库的高级转换,并使用MLIR来支持这些Fortran特定的优化。这些高级优化——高级循环优化、数组复制消除、调用专门化、去虚拟化——仅使用LLVM很难实现。
例如,FIR能够将Fortran虚拟调度表建模为一等概念。

在结构化IR中建模编程语言的高级语义的能力非常强大。例如,调度表的一等建模允许实现一个强大的去虚拟化过程。虽然这可以通过定制的编译器IR实现,但使用MLIR使flang开发人员能够专注于其领域的IR设计,而不是重新实现基本基础设施。
选择MLIR还解锁了其他非特定于Fortran的方言的可重用性:语言无关的OpenMP方言可以在Fortran和C语言前端之间共享。类似地,使用OpenACC针对异构平台在MLIR中变得可行,通过共享和重用面向GPU的方言和过程。这很简单,因为MLIR专门设计用于支持可组合方言的混合。
D. 领域特定编译器
上述应用程序在大型工作流中。但MLIR也有助于构建较小的领域特定编译器。可重用和模块化的基础设施使这些专门的路径变得可行且相对便宜。
优化MLIR模式重写:MLIR具有一个可扩展的模式重写系统。除了静态声明的模式外,我们还有一些应用程序需要在运行时动态扩展重写模式,允许硬件供应商在驱动程序中添加新的降低。解决方案是将MLIR模式重写本身表示为一个MLIR方言,允许我们使用MLIR基础设施来动态构建和优化高效的有限状态机(FSM)匹配器和重写器。这项工作包括在其他系统中看到的FSM优化,例如LLVM SelectionDAG和GlobalISel指令选择系统。
格回归编译器:格回归是一种以快速评估时间和可解释性而闻名的机器学习技术。编译器的前身是使用C++模板实现的。这允许使用元编程实现高性能代码,但在端到端模型上表达一般优化并不简单。这个特定的格回归系统用于拥有数百万用户的应用程序,因此性能改进至关重要。
MLIR被用作该专业领域新编译器的基础,该编译器由一种专门的搜索方法驱动——实际上导致在编译期间解决了一个机器学习问题。结果编译器通过投入3人月的努力开发,最终在生产模型上实现了高达8倍的性能提升,同时也提高了编译过程中的透明度。
V. MLIR设计的后果
MLIR设计促进了新语言和编译器抽象的建模,同时重用现有的通用抽象。实际上,解决许多问题的方法是“添加新的操作、新的类型”,可能收集到“一个新的方言”中。这是编译器工程的一个重大设计转变。它产生了新的机会、挑战和见解。本节探讨其中的一些。
A. 可重用的编译器 pass
在一个IR中表示多个抽象层次的能力激励了跨这些层次操作的传递。MLIR通过反转常见的方法来处理可扩展性:由于Ops比传递多,因此Ops更容易了解传递。这也提高了模块化,因为方言特定的逻辑是在方言中实现的,而不是核心转换中。由于传递很少需要了解Op的所有方面,MLIR依赖以下机制来实现通用传递。
操作特征:许多常见的“面包和黄油”编译器传递,例如死代码或公共子表达式消除,依赖于简单的属性,如“是终结者”或“是可交换的”。我们将这些属性定义为Op特征。Op无条件地展示特征,例如,“标准分支”Op始终是一个终结者。对于许多传递,知道Op具有一组特征就足以对其进行操作,例如通过交换操作数或删除没有副作用和没有用户的Ops。
特征可以作为验证钩子,允许在具有特征的多个Ops之间共享逻辑。例如,“从上方隔离”特征验证Op中的区域不使用在Op包围的区域中定义的值。它允许对函数、模块和其他自包含结构进行通用处理。
接口:当无条件的静态行为表达力不足时,可以通过接口参数化处理,这一概念借鉴自面向对象编程。接口定义了IR对象行为的视图,抽象掉不必要的细节。与特征不同,接口由IR对象实现,使用任意C++代码,可以为不同的对象产生不同的结果。例如,“调用”Op实现了一个“类似调用”的接口,但Op的不同实例调用不同的函数。
MLIR传递可以通过接口实现,与任何选择被传递处理的Op建立合同。继续类似调用的例子,考虑在TensorFlow图、Flang函数、函数式语言中的闭包上工作的MLIR内联传递。这样的传递需要知道:(1) 是否有效地将操作内联到给定区域中,以及(2) 如何处理在内联后出现在块中间的终结者操作。
为了查询Op关于这些属性,传递定义了一个专用接口,以便Ops可以注册其实现以从内联中受益。内联传递将保守地对待,即忽略任何未实现相应接口的操作。
常量折叠通过相同的机制实现:每个Op通过提供一个可能产生持有值的属性的函数来实现“折叠”接口,如果Op是可折叠的。更通用的规范化可以类似地实现:一个接口填充适合模式重写的规范化模式列表。此设计将通用逻辑与Op特定逻辑分开,并将后者放在Op本身中,减少了LLVM中“InstCombine”、“PeepholeOptimizer”等的众所周知的维护和复杂性负担。
接口可以由方言而不是特定的Ops实现,这使得在方言中实现共享行为或委托给外部逻辑成为可能,例如在常量折叠TensorFlow Ops时。接口也支持类型和属性,例如加法操作可以支持任何自声明为“整数样”的类型,并具有可查询的符号语义。
B. 特定方言的传递
最后,定义特定于特定方言的传递是有效且有用的,这些传递可以由其设计的方言中的操作的完整语义驱动。这些传递在MLIR系统中与其他编译器系统中一样有用。例如,代码生成器希望根据特定的机器约束或其他不适合更广泛框架的技巧进行自定义调度。这是新转换的一个简单而有用的起点,其中不需要泛化。
C. 混合方言
MLIR最深刻(但也最难理解)的方面之一是它允许并鼓励将来自不同方言的操作混合到一个程序中。虽然某些情况相对容易理解(例如在同一模块中保持主机和加速器计算),但最有趣的情况是方言直接混合——因为这使得在其他系统中未见的整个重用类成为可能。
考虑第IV-B节中描述的仿射方言。仿射控制流和仿射映射的定义独立于包含在仿射区域中的操作的语义。在我们的情况下,我们将仿射方言与表示简单算术的“标准”方言结合在一起,以目标无关的形式,如LLVM IR,具有多个特定于目标的内部加速器的机器指令方言。其他人将其与其他问题领域的抽象结合在一起。
能够重用通用的多面体转换(使用Op接口获取特定转换中操作的语义)是一种强大(对我们来说也很令人兴奋)的编译器基础设施分解方式。另一个例子是,语言无关的OpenMP方言可以在Fortran和C语言前端之间共享。
D. 并行编译
MLIR的一个重要方面是可以使用多核机器来提高编译速度。特别是,“从上方隔离”特征允许函数等Ops选择进入MLIR的传递管理器支持的并发IR遍历机制。实际上,这一特征保证SSA使用-定义链不能跨越区域边界,并且可以独立处理。MLIR也不具有整个模块的使用-定义链,而是通过符号表引用全局对象,并将常量定义为具有属性的操作。
E. 互操作性
我们的工作涉及与大量现有系统的互操作,例如编码为协议缓冲区的机器学习图,包括LLVM IR在内的编译器IR,专有指令集等。通常,表示具有一些在现有系统上下文中有意义的次优或不幸的决策,但MLIR的能力使得更具表现力的表示成为可能。因为导入器和导出器众所周知地难以测试(测试用例通常是二进制的),我们希望确保其复杂性最小化。
解决方案是定义一个尽可能直接对应于外部系统的方言——允许以简单和可预测的方式往返于该格式。一旦IR被导入MLIR,它可以使用所有MLIR基础设施提升和降低到更方便的IR,这允许这些转换像所有其他MLIR传递一样进行测试。有许多这样的方言示例,包括将LLVM IR映射到MLIR的LLVM方言。这种方法对我们来说效果很好,MLIR工具也在编写这些外部文件格式的测试中非常有用。
F. 无偏见设计带来的新挑战
虽然MLIR允许定义几乎任意的抽象,但它对应该做什么提供的指导很少:在实践中什么效果更好或更差?我们现在有一些工程师和研究人员将这些技术和技术应用于新问题领域的经验,并意识到编译器IR设计和抽象设计的“艺术”在编译器和语言领域并不为人所知——许多人在既定系统的约束下工作,但相对较少的人有机会自己定义抽象。
这是一个挑战,但也是未来研究的另一个机会。更广泛的MLIR社区正在积累这些抽象设计权衡的专业知识,我们预计这将是一个长期的研究领域。
G. 展望未来
MLIR的设计与其他编译器基础设施有足够的不同,以至于我们仍在学习——即使在构建和应用于许多不同系统之后。我们相信,仍有许多东西需要发现,并且需要数年的研究来更好地理解设计点并建立最佳实践。例如,树外方言的兴起,使用MLIR的源语言前端数量的增加,可能应用于抽象语法树和结构化数据(如JSON、协议缓冲区等)的应用,这些仍处于早期阶段,可能会揭示有趣的新挑战和机会。更好地支持即时编译和精确的垃圾收集也将是有趣的,利用IR的模块化和可编程性。
VI. 相关工作
MLIR是一个与多个不同领域重叠的项目。虽然组合的基础设施提供了一个新颖的系统,但个别组件在文献中有类似物。有关直接与IR设计相关的参考文献和讨论,请参阅第II节。
MLIR是一个类似于LLVM的编译器基础设施,但LLVM在标量优化和同构编译方面取得了巨大成功,而MLIR旨在将丰富的数据结构和算法建模为一等值和操作,包括张量代数和算法、图表示以及异构编译。MLIR允许混合和匹配优化,将编译过程分解为组件,并重新定义降低、清理角色。这在很大程度上归因于模式重写基础设施,将完整的转换捕获为小型局部模式的组合,并在单个操作的粒度上控制应用哪些模式重写。自动扩展、形式化和验证重写逻辑将是下一步的重要步骤。在后端,MLIR的DDR与LLVM的指令选择基础设施类似,支持具有多结果模式和作为约束的规范的可扩展操作。
许多编程语言和模型解决硬件异构性问题。最初是一个同构编程模型,OpenMP增加了对任务卸载和并行区域的支持,基于早期的提议如StarSs和OpenACC。C++ AMP、HCC和SyCL利用传统的Clang/LLVM流程和现代C++提供硬件加速的高级抽象。不幸的是,所有这些例子都很快将高级构造降低为对运行时执行环境的调用,依赖于宿主语言(通常是C++)中预先存在的优化来减轻抽象惩罚。针对异构编译过程的努力要少得多。扩展LLVM IR的并行中间表示解决了部分问题,但传统上专注于同构设置。迄今为止最雄心勃勃的努力可能是Liquid Metal,它与领域特定语言(DSL)和编译流共同设计,将托管对象语义转换为静态、向量或可重构硬件;然而,其Lime编译器中的大部分工作集中在将圆形对象适配到方形硬件中。MLIR通过可扩展的操作和类型集直接嵌入支持异构性的高级语言,同时提供一个通用的基础设施,以最大限度地重用不同目标的常见组件,逐步降低这些构造。
解决语言异构性问题一直是元编程系统的长期承诺,特别是在多阶段编程中。轻量级模块化分级(LMS)是一个最先进的框架和运行时代码生成器,提供了一个核心组件库,用于生成高效代码并在Scala中嵌入DSL。Delite承诺为DSL开发人员带来显著的生产力提升,同时支持并行和异构执行。这种方法与MLIR互为补充,提供了更高层次的抽象来嵌入DSL,并通过通用的元编程构造实现优化。
在语言语法上更进一步,ANTLR是旨在促进编译器前端开发的一类解析器生成器之一。MLIR目前没有通用的解析器生成器,没有AST构建或建模功能。将MLIR与ANTLR等系统结合可以将可重用性扩展到前端和开发环境。
更狭义地说,XLA、Glow和TVM通过提供从图形抽象开始并针对加速器的多维向量抽象的领域特定代码生成实例,解决了类似的异构编译目标。所有这些都可以利用MLIR作为基础设施,利用通用功能,同时使用其当前的代码生成策略。类似地,Halide和TVM的循环嵌套元编程技术、早期的循环嵌套元编程和自动化流程(如PolyMage、Tensor Comprehensions、Stripe、Diesel、Tiramisu及其底层的多面体编译技术)可以在基于MLIR的框架中作为不同的代码生成路径共存。这将大大增加代码重用、减少领域间的碎片化、提高互操作性和可移植性。这实际上是IREE项目的动机之一,基于MLIR在多个抽象层次上构建,从张量代数和操作符图到异步协程的低级编排和多CPU和GPU架构的代码生成。
最后,ONNX等互操作性格式通过提供一组不同框架可以映射到的通用操作集,采用了不同的方法来解决ML前端的多样性。ONNX可以作为MLIR中的一个方言候选,以便在MLIR中进行操作的转换。
VII. 结论与未来工作
我们介绍了MLIR,这是一种具体的解决方案,旨在解决设计灵活和可扩展的编译器基础设施的科学和工程挑战,涵盖从后端代码生成和异构系统的编排,到机器学习的图级建模,再到编程语言和领域特定框架的高级语言语义。我们展示了其在多个领域的适用性,并讨论了研究的影响。
受到LLVM成功的激励并展望未来,我们渴望看到编程语言和高性能计算的既定社区,以及领域专家如何从引入更高级别、语言特定的IR中受益。我们还相信,MLIR将催化新的研究领域,以及教授编译器和IR设计艺术的新方法。
致谢
本文和项目的完成离不开许多其他个人的贡献。我们对所有人表示感谢。我们还感谢Google访问学者计划在MLIR早期阶段对第三作者的支持。
附录
A. 摘要
本文的工件包括MLIR系统、下载和构建它的说明以及链接到TensorFlow中与MLIR相关的源代码。
B. 工件清单(元信息)
程序:MLIR
编译:LLVM C++ 工具链
运行环境:推荐使用Linux
公开可用吗?:是
存档:DOI 10.5281/zenodo.4283090
C. 描述
1) 交付方式
要下载MLIR,请运行以下命令:
git clone https://github.com/llvm/llvm-project.git下载和构建MLIR的说明也可以在MLIR Getting Started找到。更多信息可在mlir.llvm.org获取。
2) 软件依赖
下载MLIR需要git。构建MLIR需要Ninja(https://ninja-build.org/)和一个包括clang和lld的工作C++工具链。
D. 安装
要在Linux上构建和测试MLIR,请执行以下命令:
mkdir llvm-project/build
cd llvm-project/build
cmake -G Ninja ../llvm \
-DLLVM_ENABLE_PROJECTS=mlir \
-DLLVM_BUILD_EXAMPLES=ON \
-DLLVM_TARGETS_TO_BUILD="X86;NVPTX;AMDGPU" \
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_ENABLE_ASSERTIONS=ON \
-DLLVM_C_COMPILER=clang \
-DLLVM_CXX_COMPILER=clang++ \
-DLLVM_ENABLE_LLD=ON
cmake --build . --target check-mlirE. 应用
MLIR在TensorFlow中的使用可以在以下代码中观察到:
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/compiler/mlir/位于tensorflow/tests子目录中的测试包含MLIR代码片段,说明了TensorFlow图表示和转换。有关从源代码构建TensorFlow的说明,请访问:
https://www.tensorflow.org/install/source参考
[1] C. Lattner and V. Adve, “LLVM: A compilation framework for
lifelong program analysis & transformation,” in Proceedings of
the International Symposium on Code Generation and Optimization:
Feedback-directed and Runtime Optimization, ser. CGO ’04. Washington,
DC, USA: IEEE Computer Society, 2004, pp. 75–. [Online]. Available:
http://dl.acm.org/citation.cfm?id=977395.977673
[2] T. Lindholm and F. Yellin, Java Virtual Machine Specification, 2nd ed.
Boston, MA, USA: Addison-Wesley Longman Publishing Co., Inc., 1999.
[3] R. Cytron, J. Ferrante, B. K. Rosen, M. N. Wegman, and F. K.
Zadeck, “Efficiently computing static single assignment form and
the control dependence graph,” ACM Trans. Program. Lang. Syst.,
vol. 13, no. 4, pp. 451–490, Oct. 1991. [Online]. Available:
http://doi.acm.org/10.1145/115372.115320
[4] R. Johnson, D. Pearson, and K. Pingali, “The program structure tree:
Computing control regions in linear time,” in Proceedings of the ACM
SIGPLAN 1994 Conference on Programming Language Design and
Implementation, ser. PLDI ’94. New York, NY, USA: ACM, 1994, pp.
171–185. [Online]. Available: http://doi.acm.org/10.1145/178243.178258
[5] W. A. Havanki, S. Banerjia, and T. M. Conte, “Treegion scheduling
for wide issue processors,” in Proceedings of the Fourth International
Symposium on High-Performance Computer Architecture, Las Vegas,
Nevada, USA, January 31 - February 4, 1998, 1998, pp. 266–276.
[Online]. Available: https://doi.org/10.1109/HPCA.1998.650566
[6] G. Ramalingam, “On loops, dominators, and dominance frontiers,” ACM
Trans. Program. Lang. Syst., vol. 24, no. 5, pp. 455–490, 2002. [Online].
Available: https://doi.org/10.1145/570886.570887
[7] D. Khaldi, P. Jouvelot, F. Irigoin, C. Ancourt, and B. Chapman,
“LLVM parallel intermediate representation: Design and evaluation
using OpenSHMEM communications,” in Proceedings of the Second
Workshop on the LLVM Compiler Infrastructure in HPC, ser. LLVM ’15.
New York, NY, USA: ACM, 2015, pp. 2:1–2:8. [Online]. Available:
http://doi.acm.org/10.1145/2833157.2833158
[8] T. B. Schardl, W. S. Moses, and C. E. Leiserson, “Tapir: Embedding forkjoin parallelism into LLVM’s intermediate representation,” SIGPLAN
Not., vol. 52, no. 8, pp. 249–265, Jan. 2017. [Online]. Available:
http://doi.acm.org/10.1145/3155284.3018758
[9] Open64 Developers, “Open64 compiler and tools,” 2001.
[10] C. Click and K. D. Cooper, “Combining analyses, combining
optimizations,” ACM Trans. Program. Lang. Syst., vol. 17, no. 2, pp.
181–196, Mar. 1995. [Online]. Available: http://doi.acm.org/10.1145/
201059.201061
[11] A. Pnueli, M. Siegel, and E. Singerman, “Translation validation,” in
Tools and Algorithms for Construction and Analysis of Systems, 4th
International Conference, TACAS ’98, Held as Part of the European
Joint Conferences on the Theory and Practice of Software, ETAPS’98,
Lisbon, Portugal, March 28 - April 4, 1998, Proceedings, 1998, pp.
151–166. [Online]. Available: https://doi.org/10.1007/BFb0054170
[12] G. C. Necula, “Translation validation for an optimizing compiler,”
SIGPLAN Not., vol. 35, no. 5, pp. 83–94, May 2000. [Online]. Available:
http://doi.acm.org/10.1145/358438.349314
[13] J. Tristan and X. Leroy, “Formal verification of translation validators:
a case study on instruction scheduling optimizations,” in Proceedings
of the 35th ACM SIGPLAN-SIGACT Symposium on Principles of
Programming Languages, POPL 2008, San Francisco, California,
USA, January 7-12, 2008, 2008, pp. 17–27. [Online]. Available:
https://doi.org/10.1145/1328438.1328444
[14] ——, “Verified validation of lazy code motion,” in Proceedings of the
2009 ACM SIGPLAN Conference on Programming Language Design and
Implementation, PLDI 2009, Dublin, Ireland, June 15-21, 2009, 2009, pp.
316–326. [Online]. Available: https://doi.org/10.1145/1542476.1542512
[15] Y. Chen, A. Groce, C. Zhang, W. Wong, X. Z. Fern, E. Eide, and
J. Regehr, “Taming compiler fuzzers,” in ACM SIGPLAN Conference on
Programming Language Design and Implementation, PLDI ’13, Seattle,
WA, USA, June 16-19, 2013, 2013, pp. 197–208. [Online]. Available:
https://doi.org/10.1145/2491956.2462173
[16] B. Schommer, C. Cullmann, G. Gebhard, X. Leroy, M. Schmidt, and
S. Wegener, “Embedded Program Annotations for WCET Analysis,” in
WCET 2018: 18th International Workshop on Worst-Case Execution
Time Analysis, vol. 63. Barcelona, Spain: Dagstuhl Publishing, Jul.
2018. [Online]. Available: https://hal.inria.fr/hal-01848686
[17] S. T. Vu, K. Heydemann, A. de Grandmaison, and A. Cohen, “Secure
delivery of program properties through optimizing compilation,” in ACM
SIGPLAN 2020 International Conference on Compiler Construction (CC
2020), San Diego, CA, Feb. 2020.
[18] G. Balakrishnan and T. Reps, “Wysinwyx: What you see is not
what you execute,” ACM Trans. Program. Lang. Syst., vol. 32,
no. 6, pp. 23:1–23:84, Aug. 2010. [Online]. Available: http:
//doi.acm.org/10.1145/1749608.1749612
[19] “TableGen - LLVM 10 Documentation,” Online,
=https://llvm.org/docs/TableGen/, accessed Nov 22, 2019, 2019.
[Online]. Available: https://llvm.org/docs/TableGen/
[20] A. W. Appel, “SSA is functional programming,” ACM SIGPLAN
NOTICES, vol. 33, no. 4, pp. 17–20, 1998.
[21] C. Click and M. Paleczny, “A simple graph-based intermediate
representation,” in Papers from the 1995 ACM SIGPLAN Workshop
on Intermediate Representations, ser. IR ’95. New York, NY, USA:
Association for Computing Machinery, 1995, p. 35–49. [Online].
Available: https://doi.org/10.1145/202529.202534
[22] A. Veen, “Dataflow machine architecture,” ACM Comput. Surv., vol. 18,
pp. 365–396, 12 1986.
[23] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S.
Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow,
A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser,
M. Kudlur, J. Levenberg, D. Mané, R. Monga, S. Moore, D. Murray,
C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar,
P. Tucker, V. Vanhoucke, V. Vasudevan, F. Viégas, O. Vinyals,
P. Warden, M. Wattenberg, M. Wicke, Y. Yu, and X. Zheng,
“TensorFlow: Large-scale machine learning on heterogeneous systems,”
2015, software available from tensorflow.org. [Online]. Available:
https://www.tensorflow.org/
[24] “XLA - TensorFlow, compiled,” Google Developers Blog, https:
//developers.googleblog.com/2017/03/xla-tensorflow-compiled.html, Mar
2017. [Online]. Available: https://developers.googleblog.com/2017/03/
xla-tensorflow-compiled.html
[25] P. Feautrier, “Some efficient solutions to the affine scheduling problem.
part II. multidimensional time,” Int. J. Parallel Program., vol. 21, no. 6,
pp. 389–420, 1992.
[26] S. Girbal, N. Vasilache, C. Bastoul, A. Cohen, D. Parello, M. Sigler,
and O. Temam, “Semi-automatic composition of loop transformations
for deep parallelism and memory hierarchies,” Int. J. Parallel
Program., vol. 34, no. 3, pp. 261–317, Jun. 2006. [Online]. Available:
http://dx.doi.org/10.1007/s10766-006-0012-3
[27] S. Verdoolaege, “ISL: An integer set library for the polyhedral
model,” in Proceedings of the Third International Congress Conference
on Mathematical Software, ser. ICMS’10. Berlin, Heidelberg:
Springer-Verlag, 2010, pp. 299–302. [Online]. Available: http:
//dl.acm.org/citation.cfm?id=1888390.1888455
[28] S. Verdoolaege, J. Carlos Juega, A. Cohen, J. Ignacio Gómez, C. Tenllado,
and F. Catthoor, “Polyhedral parallel code generation for CUDA,” ACM
Trans. Archit. Code Optim., vol. 9, no. 4, pp. 54:1–54:23, Jan. 2013.
[Online]. Available: http://doi.acm.org/10.1145/2400682.2400713
[29] N. Vasilache, O. Zinenko, T. Theodoridis, P. Goyal, Z. Devito,
W. S. Moses, S. Verdoolaege, A. Adams, and A. Cohen, “The next
700 accelerated layers: From mathematical expressions of network
computation graphs to accelerated GPU kernels, automatically,” ACM
Trans. Archit. Code Optim., vol. 16, no. 4, pp. 38:1–38:26, Oct. 2019.
[Online]. Available: http://doi.acm.org/10.1145/3355606
[30] C. Reddy and U. Bondhugula, “Effective automatic computation
placement and data allocation for parallelization of regular programs,”
in Proceedings of the 28th ACM International Conference on
Supercomputing, ser. ICS ’14. New York, NY, USA: ACM, 2014, pp.
13–22. [Online]. Available: http://doi.acm.org/10.1145/2597652.2597673
[31] T. Grosser, A. Größlinger, and C. Lengauer, “Polly - performing
polyhedral optimizations on a low-level intermediate representation,”
Parallel Processing Letters, vol. 22, no. 4, 2012. [Online]. Available:
https://doi.org/10.1142/S0129626412500107
[32] L. Chelini, O. Zinenko, T. Grosser, and H. Corporaal, “Declarative loop
tactics for domain-specific optimization,” TACO, vol. 16, no. 4, pp.
55:1–55:25, 2020. [Online]. Available: https://doi.org/10.1145/3372266
[33] C. Bastoul, “Code generation in the polyhedral model is easier than you
think,” in Proceedings of the 13th International Conference on Parallel
Architectures and Compilation Techniques, ser. PACT ’04. Washington,
DC, USA: IEEE Computer Society, 2004, pp. 7–16. [Online]. Available:
https://doi.org/10.1109/PACT.2004.11
[34] E. Schweitz, “An MLIR dialect for high-level optimization of fortran,”
LLVM Developer Meeting, Oct 2019.
[35] E. Garcia and M. Gupta, “Lattice regression,” in Advances in Neural
Information Processing Systems 22, Y. Bengio, D. Schuurmans,
J. D. Lafferty, C. K. I. Williams, and A. Culotta, Eds. Curran
Associates, Inc., 2009, pp. 594–602. [Online]. Available: http:
//papers.nips.cc/paper/3694-lattice-regression.pdf
[36] M. Bravenboer, K. T. Kalleberg, R. Vermaas, and E. Visser, “Stratego/xt
0.17. A language and toolset for program transformation,” Sci. Comput.
Program., vol. 72, no. 1-2, pp. 52–70, 2008. [Online]. Available:
https://doi.org/10.1016/j.scico.2007.11.003
[37] J. Meseguer, “Twenty years of rewriting logic,” in Proceedings of the
8th International Conference on Rewriting Logic and Its Applications,
ser. WRLA’10. Berlin, Heidelberg: Springer-Verlag, 2010, pp. 15–17.
[Online]. Available: http://dl.acm.org/citation.cfm?id=1927806.1927809
[38] P. Thier, M. A. Ertl, and A. Krall, “Fast and flexible instruction
selection with constraints,” in Proceedings of the 27th International
Conference on Compiler Construction, ser. CC 2018. New York,
NY, USA: ACM, 2018, pp. 93–103. [Online]. Available: http:
//doi.acm.org/10.1145/3178372.3179501
[39] OpenMP ARB, “The OpenMP API specification for parallel programming,” Online, https://www.openmp.org, accessed Feb 19, 2020.
[40] J. Planas, R. M. Badia, E. Ayguadé, and J. Labarta, “Hierarchical taskbased programming with starss,” IJHPCA, vol. 23, no. 3, pp. 284–299,
2009. [Online]. Available: https://doi.org/10.1177/1094342009106195
[41] “OpenACC application programming interface,” Online, https://www.
openacc.org, accessed Feb 19, 2020.
[42] “SyCL: C++ single-source heterogeneous programming for OpenCL,”
Online, https://www.khronos.org/sycl, accessed Feb 19, 2020.
[43] J. Auerbach, D. F. Bacon, I. Burcea, P. Cheng, S. J. Fink, R. Rabbah,
and S. Shukla, “A compiler and runtime for heterogeneous computing,”
in Proceedings of the 49th Annual Design Automation Conference, ser.
DAC ’12. New York, NY, USA: ACM, 2012, pp. 271–276. [Online].
Available: http://doi.acm.org/10.1145/2228360.2228411
[44] S. Kou and J. Palsberg, “From oo to fpga: Fitting round objects into
square hardware?” in Proceedings of the ACM International Conference
on Object Oriented Programming Systems Languages and Applications,
ser. OOPSLA ’10. New York, NY, USA: ACM, 2010, pp. 109–124.
[Online]. Available: http://doi.acm.org/10.1145/1869459.1869470
[45] T. Rompf and M. Odersky, “Lightweight modular staging: a pragmatic
approach to runtime code generation and compiled dsls,” Commun.
ACM, vol. 55, no. 6, pp. 121–130, 2012. [Online]. Available:
https://doi.org/10.1145/2184319.2184345
[46] A. K. Sujeeth, K. J. Brown, H. Lee, T. Rompf, H. Chafi, M. Odersky, and
K. Olukotun, “Delite: A compiler architecture for performance-oriented
embedded domain-specific languages,” ACM Trans. Embedded Comput.
Syst., vol. 13, no. 4s, pp. 134:1–134:25, 2014. [Online]. Available:
https://doi.org/10.1145/2584665
[47] T. J. Parr and R. W. Quong, “Antlr: A predicated-ll(k) parser generator,”
Softw. Pract. Exper., vol. 25, no. 7, pp. 789–810, Jul. 1995. [Online].
Available: http://dx.doi.org/10.1002/spe.4380250705
[48] N. Rotem, J. Fix, S. Abdulrasool, G. Catron, S. Deng, R. Dzhabarov,
N. Gibson, J. Hegeman, M. Lele, R. Levenstein, J. Montgomery, B. Maher,
S. Nadathur, J. Olesen, J. Park, A. Rakhov, M. Smelyanskiy, and M. Wang,
“Glow: Graph lowering compiler techniques for neural networks,” 2018.
[49] T. Chen, T. Moreau, Z. Jiang, L. Zheng, E. Yan, H. Shen, M. Cowan,
L. Wang, Y. Hu, L. Ceze, C. Guestrin, and A. Krishnamurthy,
“TVM: An automated end-to-end optimizing compiler for deep
learning,” in 13th USENIX Symposium on Operating Systems
Design and Implementation (OSDI 18). Carlsbad, CA: USENIX
Association, Oct. 2018, pp. 578–594. [Online]. Available: https:
//www.usenix.org/conference/osdi18/presentation/chen
[50] J. Ragan-Kelley, A. Adams, D. Sharlet, C. Barnes, S. Paris, M. Levoy,
S. Amarasinghe, and F. Durand, “Halide: Decoupling algorithms
from schedules for high-performance image processing,” Commun.
[51] G. Rudy, M. M. Khan, M. Hall, C. Chen, and J. Chame, “A programming
language interface to describe transformations and code generation,” in
Languages and Compilers for Parallel Computing, K. Cooper, J. MellorCrummey, and V. Sarkar, Eds. Berlin, Heidelberg: Springer Berlin
Heidelberg, 2011, pp. 136–150.
[52] L. Bagnères, O. Zinenko, S. Huot, and C. Bastoul, “Opening polyhedral
compiler’s black box,” in Proceedings of the 2016 International Symposium on Code Generation and Optimization, CGO 2016, Barcelona,
Spain, March 12-18, 2016, 2016, pp. 128–138.
[53] A. Cohen, S. Donadio, M.-J. Garzaran, C. Herrmann, O. Kiselyov,
and D. Padua, “In search of a program generator to implement
generic transformations for high-performance computing,” Sci. Comput.
Program., vol. 62, no. 1, pp. 25–46, Sep. 2006. [Online]. Available:
http://dx.doi.org/10.1016/j.scico.2005.10.013
[54] R. T. Mullapudi, V. Vasista, and U. Bondhugula, “PolyMage: Automatic
optimization for image processing pipelines,” in International Conference
on Architectural Support for Programming Languages and Operating
Systems (ASPLOS), 2015, pp. 429–443.
[55] T. Zerrell and J. Bruestle, “Stripe: Tensor compilation via the
nested polyhedral model,” CoRR, vol. abs/1903.06498, 2019. [Online].
Available: http://arxiv.org/abs/1903.06498
[56] V. Elango, N. Rubin, M. Ravishankar, H. Sandanagobalane, and
V. Grover, “Diesel: Dsl for linear algebra and neural net computations
on gpus,” in Proceedings of the 2nd ACM SIGPLAN International
Workshop on Machine Learning and Programming Languages, ser.
MAPL 2018. New York, NY, USA: ACM, 2018, pp. 42–51. [Online].
Available: http://doi.acm.org/10.1145/3211346.3211354
[57] R. Baghdadi, J. Ray, M. B. Romdhane, E. Del Sozzo, A. Akkas, Y. Zhang,
P. Suriana, S. Kamil, and S. Amarasinghe, “Tiramisu: A polyhedral
compiler for expressing fast and portable code,” in Proceedings of the
2019 IEEE/ACM International Symposium on Code Generation and
Optimization, ser. CGO 2019. IEEE Press, 2019, p. 193–205.
USA, June 7-13, 2008, 2008, pp. 101–113. [Online]. Available:
https://doi.org/10.1145/1375581.1375595
[58] U. Bondhugula, A. Hartono, J. Ramanujam, and P. Sadayappan,
“A practical automatic polyhedral parallelizer and locality optimizer,”
in Proceedings of the ACM SIGPLAN 2008 Conference on
Programming Language Design and Implementation, Tucson, AZ,
ACM, vol. 61, no. 1, pp. 106–115, Dec. 2017. [Online]. Available:
http://doi.acm.org/10.1145/3150211
[59] The Linux Foundation, “ONNX: Open neural network exchange,”
Online, https://github.com/onnx/onnx, accessed Feb 19, 2020. [Online].

















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









