







环境准备
在Dify平台上创建自定义工具时,需要按照以下步骤配置OpenAPI规范:
API规范定义
服务器配置调整
为本地Docker部署指定服务器URL:
servers:
- url: http://192.168.31.15:9001
完整Swagger定义
openapi: 3.1.0
info:
title: Reader Local Deployment API
version: 1.1.0
description: |
Local deployment version of web content processor with screenshot capabilities.
Converts web content to LLM-friendly formats and generates screenshots.
Key Features:
- Local Docker deployment
- Multiple output formats support
- Local screenshot storage
- No authentication required
license:
name: Apache 2.0
url: https://www.apache.org/licenses/LICENSE-2.0.html
servers:
- url: http://xxx.xxx.xxx.xxx:9001
description: Local Docker deployment
- url: https://reader.berlin.cx
description: Public demo instance
paths:
/{targetUrl}:
get:
operationId: processWebContent
summary: Process web content from URL
description: |
Converts web content to specified format and optionally generates screenshots.
Supported formats include raw text, markdown, HTML and various screenshot types.
parameters:
- in: path
name: targetUrl
required: true
schema:
type: string
format: uri
example: "https://github.com/intergalacticalvariable/reader/"
description: |
The full URL to process. Must be properly URL-encoded.
Example value: `https%3A%2F%2Fgithub.com%2Fintergalacticalvariable%2Freader%2F`
allowReserved: true
- in: header
name: X-Respond-With
required: true
schema:
type: string
enum: [text, markdown, html, screenshot, pageshot]
default: text
description: |
Response format selector:
- `text`: Clean text content (default)
- `markdown`: Raw markdown output
- `html`: Full page HTML
- `screenshot`: Viewport-sized screenshot URL
- `pageshot`: Full-page screenshot URL
responses:
'200':
description: Successfully processed content
content:
text/plain:
schema:
oneOf:
- type: string
description: Text/markdown/HTML content
example: "This is cleaned text content..."
- type: string
format: uri
description: Local screenshot path
example: "/screenshots/20240501-142356_google.com.png"
application/json:
schema:
type: object
properties:
content:
oneOf:
- type: string
description: Text content
- type: object
properties:
screenshot_url:
type: string
format: uri
example: "/screenshots/fullpage_google.com.png"
screenshot_type:
type: string
enum: [viewport, fullpage]
processed_at:
type: string
format: date-time
source_url:
type: string
format: uri
'400':
description: Invalid URL format or unsupported response type
content:
application/json:
schema:
$ref: '#/components/schemas/Error'
'500':
description: Content processing failure
content:
application/json:
schema:
$ref: '#/components/schemas/Error'
components:
schemas:
Error:
type: object
properties:
error_type:
type: string
enum: [invalid_url, processing_error, screenshot_error]
message:
type: string
example: "Failed to capture screenshot"
debug_info:
type: string
example: "Timeout waiting for page load"
required: [error_type, message]
实现步骤
- 登录Dify控制台,选择「新建工具」
- 将服务器地址改为本地环境
- 将上述Swagger定义粘贴到API规范区域
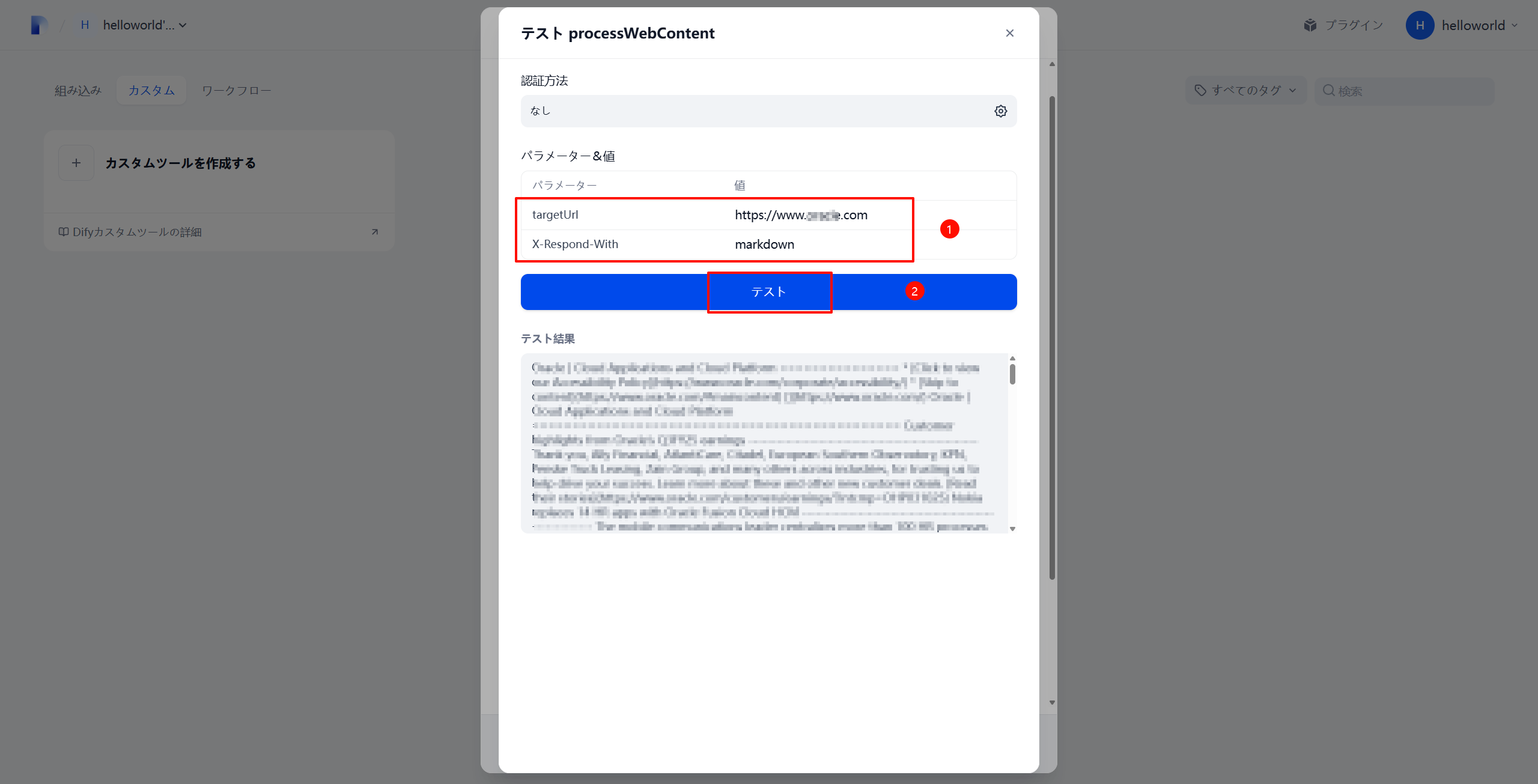
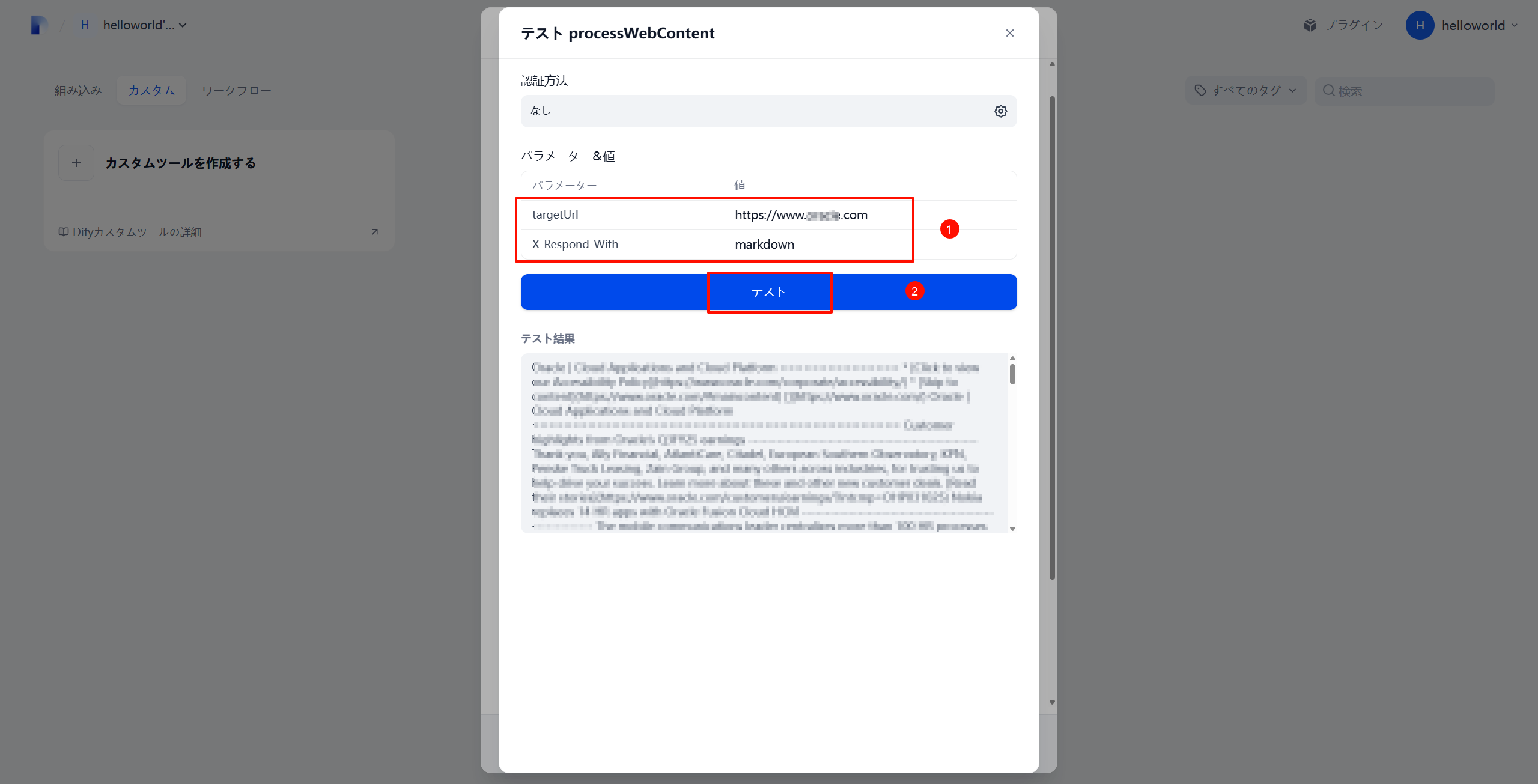
测试执行
测试结果示例:
总结
通过本方法,我们可以在Dify平台上快速构建本地部署的网页内容处理工具。清晰的Swagger规范定义显著提升了API开发和文档维护的效率,特别适合需要处理网页内容并集成到智能助手场景的开发者。
相关阅读推荐:
- Dify与本地Web阅读器的实战结合(日文原文参考)
希望本文能帮到正在探索Dify生态集成的开发者!


















 1358
1358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









