







摘要:快来利用深度学习和维基百科构建一个属于你自己的图书推荐系统吧,手把手教学,够简单够酷炫。
深度学习应用甚广,在诸多方面的表现,如图像分割、时序预测和自然语言处理,都优于其他机器学习方法。以前,你只能在学术论文或者大型商业公司中看到它的身影,但如今,我们已能利用自己的电脑进行深度学习计算。本文将利用深度学习和维基百科构建图书推荐系统。
该推荐系统基于假设:链接到类似的维基百科页面的书籍彼此相似。
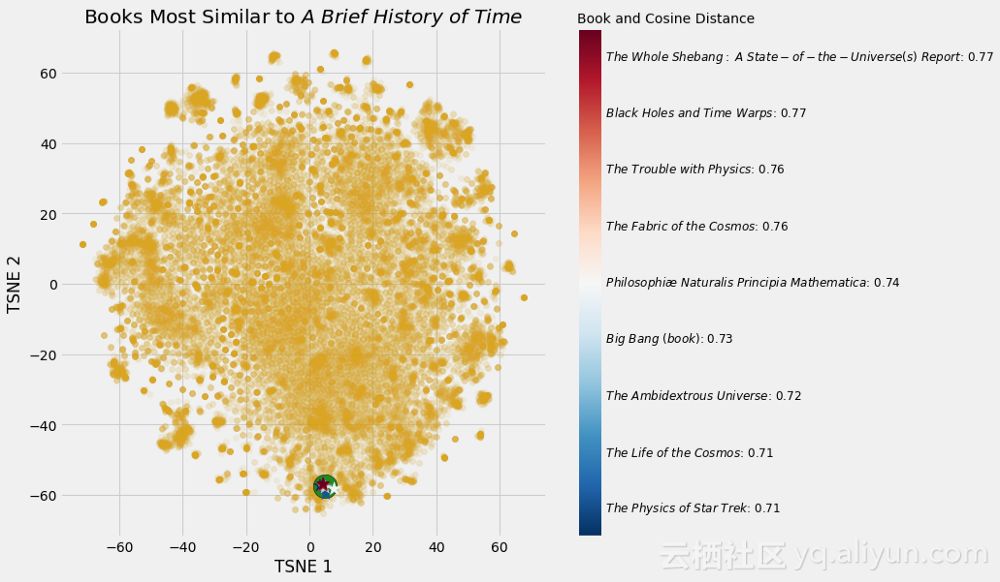
Most Similar Books to Stephen Hawking’s A Brief History of Time
完整代码详见Jupyter Notebook on GitHub。如果你没有GPU也没关系,可以通过notebook on Kaggle获取免费的GPU。
神经网络嵌入(Neural Network Embeddings)
嵌入(embedding),即用连续向量表示离散变量的方法。与独热编码不同的是,神经网络嵌入维度较低,并能令相似实体在嵌入空间中相邻。
神经网络嵌入的主要用途有三种:
在嵌入空间中找到最近邻。
作为有监督的机器学习模型的输入。
挖掘变量间的关系。
数据集:来自维基百科
与以往的数据科学项目一样,我们需要从数据集入手。点击此处,查看如何下载和处理维基百科上的每一篇文章,以及搜索书籍页面。我们保存了图书标题、基本信息以、wikilinks(wikiLinks 在搜索界面中集成了维基百科与维基词典两项服务,可以根据自己的不同需求在页面上方自由切换,而搜索历史与收藏的词条则位于屏幕右上角,点击即可跳转)。

数据下载完成后,我们需要对其进行探索和清洗,此时你可能会发现一些原始数据之间的关系。如下图,展示了与维基百科图书中的页面关联性最强的链接:
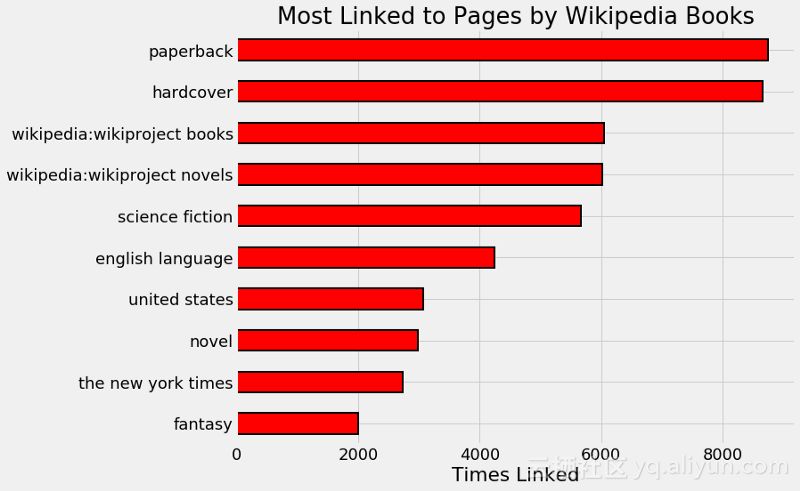
Wikipedia pages most often linked to by books on Wikipedia.
从上图可看出,排名前四的都是常用页面,对构建推荐系统没有任何帮助。就像书籍的装订版本,是平装(paperback)还是精装(hardcover)对我们了解图书的内容没有任何作用,并且神经网络无法根据这个特征判别书籍是否相似。因此,可以选择过滤掉这些无用的特征。
仔细思考哪些数据对构建推荐系统是有帮助的,哪些是无用的,有用的保留,无用的过滤,这样的数据清洗工作才算到位。
接下来,找出与其他书籍联系最紧密的书籍。以下是前10本“联系最紧密”的书籍:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









