







一.示例图:
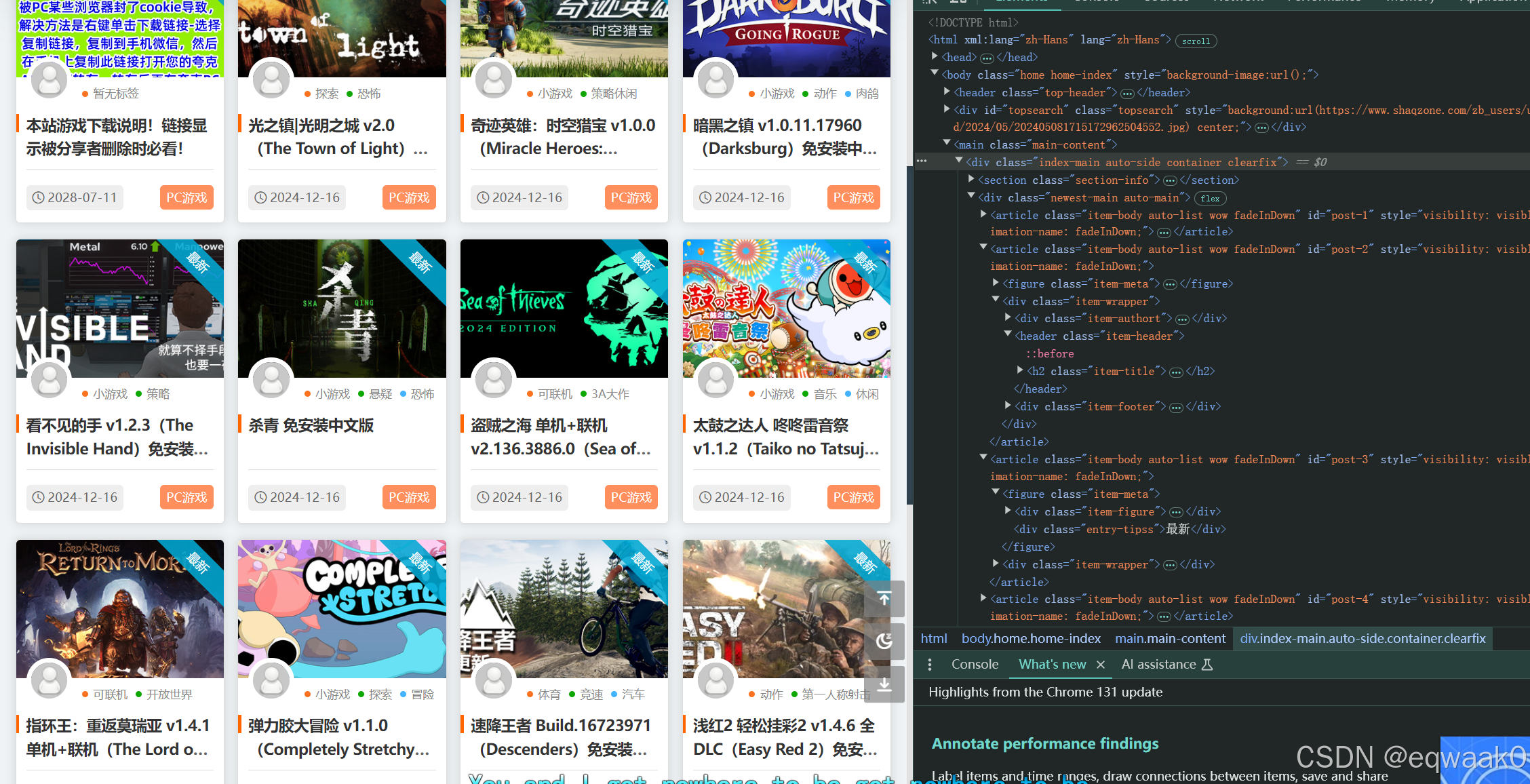
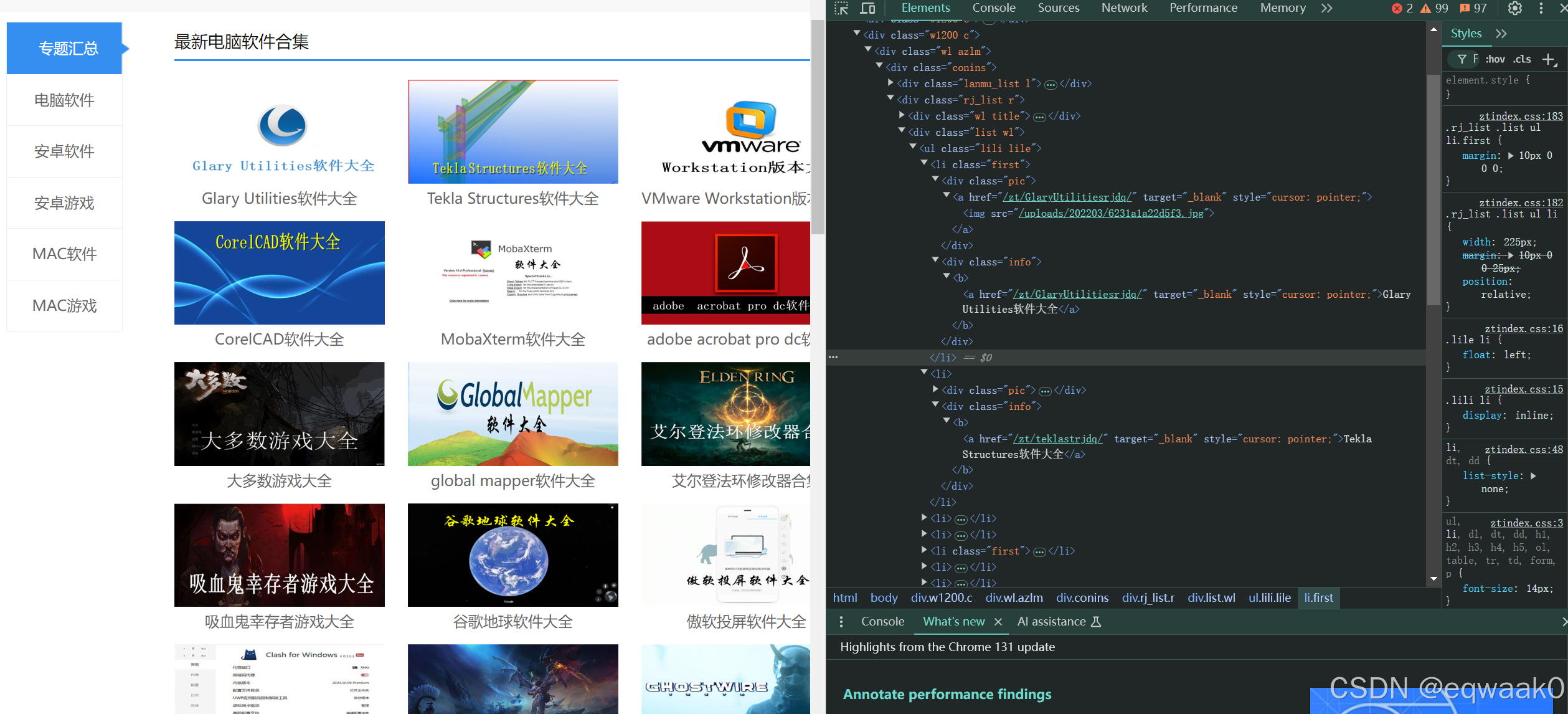
我们可以看出来数据的分组在div里面,我们现在只需要分析下里面的数据拿出就好了。
这次我们先爬取第二张图的数据
二.分析数据,并爬出数据
先写出最基本的代码:()
import requests
from bs4 import BeautifulSoup
from lxml import etree
#模拟登录
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/123.0.0.0 Safari/537.36'}
#爬取的网址
link="https://www.xue51.com/zt/"
r=requests.get(link,headers=headers)
r.encoding='utf-8'然后我们打印输出下:
soup = BeautifulSoup(r.text,'lxml')
print(soup)三.开始解析爬取的数据:
我们通过分析网页源码,找出指定的标签和对应的数据:
stock = soup.find_all('div',class_="info")
for i in stock:
b_tag = i.find('b') # 找到<b>标签
if b_tag: # 检查是否找到了标签
name = b_tag.get_text() # 获取文本
print(name)我们把需要的数据拿到了,如果继续想拿去更多数据,就像获取b标签的方法一样举一反三。
四.保存为csv文件:
import csv
with open('eqwaak.csv', 'w', newline='',encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerows(b_tag)
五.总结
最简单的数据抓取和分析完成了,也保存为csv文件了。
完整的代码如下:
import requests
from bs4 import BeautifulSoup
import csv
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36'}
link="https://www.xue51.com/zt/"
r=requests.get(link,headers=headers)
r.encoding='utf-8'
soup = BeautifulSoup(r.text,'lxml')
# print(soup)
stock = soup.find_all('div',class_="info")
for i in stock:
b_tag = i.find('b') # 找到<b>标签
if b_tag: # 检查是否找到了标签
name = b_tag.get_text() # 获取文本
print(name)
with open('eqwaak.csv', 'w', newline='',encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerows(b_tag)

















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











