






摘要
为了缓解神经网络灾难性遗忘,作者们提出了一种类似于人工神经网络突触巩固的算法(EWC)。该方法通过选择性地放慢对那些任务重要权重的学习来记住旧任务,即该方法会根据权重对之前看到的任务的重要性来减慢学习速度。
EWC
以往的学习任务包括调整一组权重和偏差
θ
\theta
θ 的线性投影,以优化性能。
θ
\theta
θ 的许多配置将导致相同的性能。这种过度参数化使得任务 B 可能有一个解决方案
θ
B
\theta_B
θB ,它接近于之前为任务 A 找到的解决方案
θ
A
\theta_A
θA 。因此,在学习任务 B 时,EWC通过将以
θ
A
\theta_A
θA 为中心的任务 A 的参数限制在一个低误差的区域来保护任务 A 的表现,如图1所示。该约束被实现为二次惩罚,因此可以想象为一个将参数锚定到前一个解决方案的弹簧,因此有elastic的名称。重要的是,这个弹簧的刚度不应该对所有参数都一样;相反,对任务 A 的表现影响最大的参数应该更大。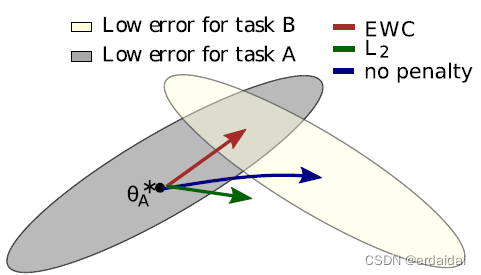
fig.1 EWC确保在训练任务 B 的时候记住任务 A。(训练轨迹在示意图参数空间中显示,参数区域导致任务a(灰色)和任务B(奶油色)的良好表现。当训练第一个任务时,参数为
θ
A
∗
\theta_A^*
θA∗。如果我们单独根据任务B(蓝色箭头)采取梯度步骤,我们会使任务B的损失最小化,但会破坏我们从任务A中学到的东西。另一方面,如果我们用相同的系数(绿色箭头)来约束每个权重,那么这个限制就太严格了,我们只能记住任务A,而不能学习任务B。相反,EWC通过显式计算任务 A 的权重有多重要,进而找到任务B的解决方案,而不会在任务 A 上造成重大损失(红色箭头)。)
现在的问题便是如何找到那些权值对任务最重要!
从概率的角度是有用的!
可以通过贝叶斯规则由参数
p
(
θ
)
p(\theta)
p(θ) 的先验概率和数据
p
(
D
∣
θ
)
p(D|\theta)
p(D∣θ) 的概率计算出这个条件概率
p
(
θ
)
∣
D
p(\theta)|D
p(θ)∣D:
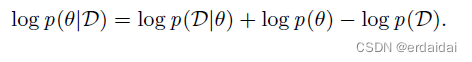
给定参数 log
p
(
θ
)
∣
D
p(\theta)|D
p(θ)∣D 的数据对数概率只是当前问题的损失函数的负数
−
L
(
θ
)
-\mathcal{L}(\theta)
−L(θ)。假设将数据集分成两个独立的部分,一个被定义为任务
A
(
D
A
)
A(D_A)
A(DA),另一个被定义为任务
B
(
D
B
)
B(D_B)
B(DB),根据以下公式可以重新调整:
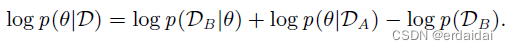
其中,左侧仍然描述给定整个数据集的参数的后验概率,而右侧仅取决于任务 B 的损失函数 log
p
(
D
B
∣
θ
)
p(D_B|\theta)
p(DB∣θ)。因此,关于任务 A 的所有信息都必须被吸收到后验分布
p
(
θ
∣
D
A
)
p(\theta|D_A)
p(θ∣DA) 中。这个后验概率必须包含哪些参数对任务A是重要的,因此是完成 EWC 的关键。真正的后验概率是难以处理的,因此,在 Mackay (19) 的拉普拉斯近似工作之后,作者将后验近似为高斯分布,其均值由参数
θ
A
∗
\theta^*_A
θA∗ 给出,对角精度由 Fisher 信息矩阵
F
F
F 的对角线给出。
其中,
F
F
F 包含三个关键性质:
1)它相当于损失接近最小值的二阶导数;
2)它可以单独从一阶导数计算,因此即使对于大型模型也很容易计算;
3)它保证是半正定的。
这种方法类似于期望传播,每个子任务都被视为后验因素。给定这个近似,在 EWC中最小化的函数
L
\mathcal{L}
L 是:
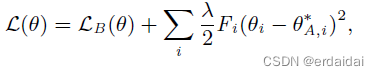
其中的
L
B
(
θ
)
\mathcal{L}_B(\theta)
LB(θ) 只是任务 B 的损失,
λ
\lambda
λ 设置旧任务相对于新任务的重要程度,
i
i
i 标记每个参数。
当移动到第三个任务 C 时,EWC 会尽量使网络参数接近任务 A 和任务 B 的学习参数。这可以通过两个单独的惩罚来执行,也可以通过注意到两个二次惩罚的总和本身就是一个二次惩罚来执行。















 7604
7604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









