







 本文详细解析了Spark集群的运行原理,包括Spark的五大核心对象:Master、Worker、Executor、Driver和CoarseGrainedExecutorBackend。讲解了Job提交过程、Job生成与接受、Task的运行以及Shuffle。强调了Spark的模块化设计和资源调度策略,同时介绍了DAGScheduler、TaskShedulerImpl等关键组件在任务调度中的作用。
本文详细解析了Spark集群的运行原理,包括Spark的五大核心对象:Master、Worker、Executor、Driver和CoarseGrainedExecutorBackend。讲解了Job提交过程、Job生成与接受、Task的运行以及Shuffle。强调了Spark的模块化设计和资源调度策略,同时介绍了DAGScheduler、TaskShedulerImpl等关键组件在任务调度中的作用。
一:Spark集群部署
二:Job提交解密
三:Job生成和接受
四:Task的运行
五:再论shuffle
1,从spark Runtime 的角度讲来讲有5大核心对象:Master , Worker , Executor ,Driver , CoarseGrainedExecutorbacked ;
2,Spark 在做分布式集群系统的设计的时候,最大化功能的独立,模块化封装具体的独立的对象,强内聚低耦合 (耦合性也称块间联系,指软件系统结构中各模块间相互联系紧密程度的一种度量。模块之间联系越紧密,其耦合性就越强,模块的独立性则越差。模块间耦合高低取决于模块间接口的复杂性、调用的方式及传递的信息。内聚性又称块内联系。指模块的功能强度的度量,即一个模块内部各个元素彼此结合的紧密程度的度量。若一个模块内各元素(语名之间、程序段之间)联系的越紧密,则它的内聚性就越高。)
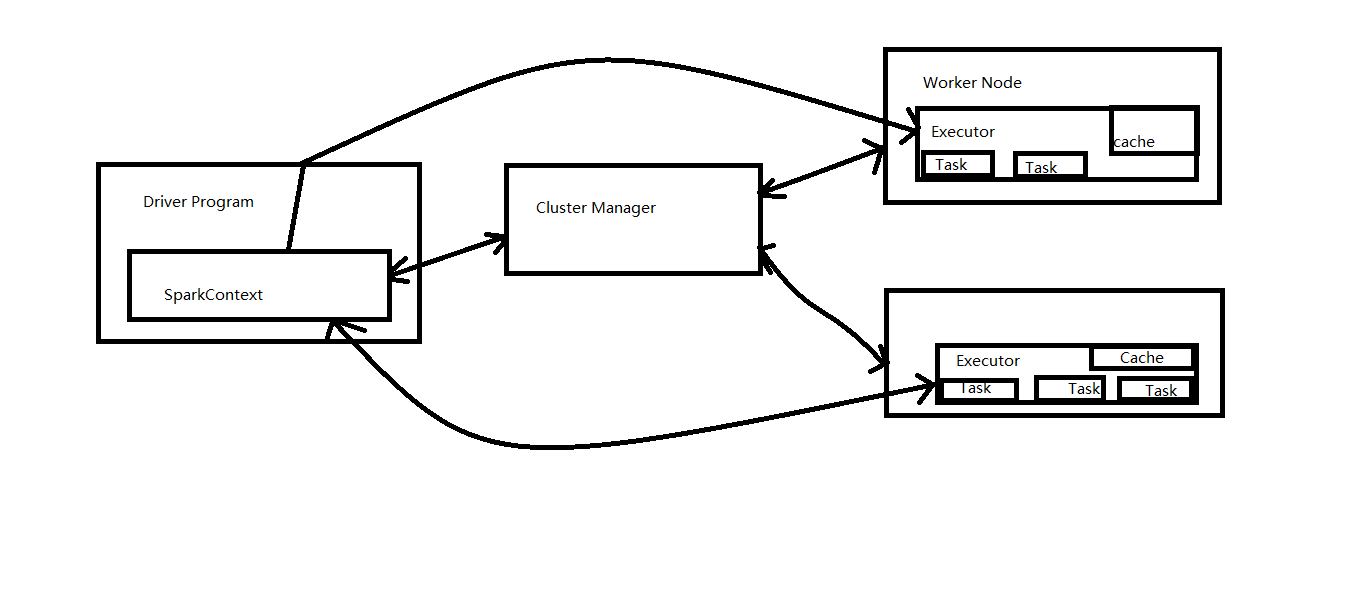
3,当Driver中的sparkContext 初始化的时候会提交程序给Master,Master如果接受该程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









