







Machine Learning
1. Definition
Field of study that gives computers the ability to learn without being explicitly programmed ---- Arthur Samuel
2. supervised learning
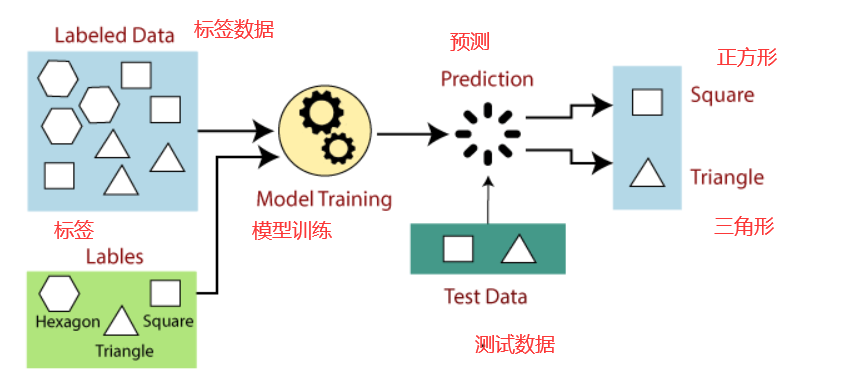
监督学习:学习输入、输出或x到y的预测,学习算法从引出的正确答案中学习,预测一个全新的输入(x)的输出(y)
监督学习的工作原理可以理解为如下:
2.1 回归(Regression)
学习算法试图从无限多的数据中预测一个数据,例如给出房子的面积,预测房价。(从无限多的数据中预测一个数据predict a number)
2.2 分类(Classification)
学习算法必须对一个类别进行预测(从相对较少的可能输出中预测类别)
3. unsupervised learning
无监督学习:无监督学习是一种机器学习技术,其中模型不使用训练数据集进行监督。相反,模型本身会从给定数据中找到隐藏的模式和见解。它可以比作在学习新事物时发生在人脑中的学习。
无监督学习的目标是找到数据集的底层结构,根据相似性对数据进行分组,并以压缩格式表示该数据集。
无监督学习的工作原理可以理解为如下:
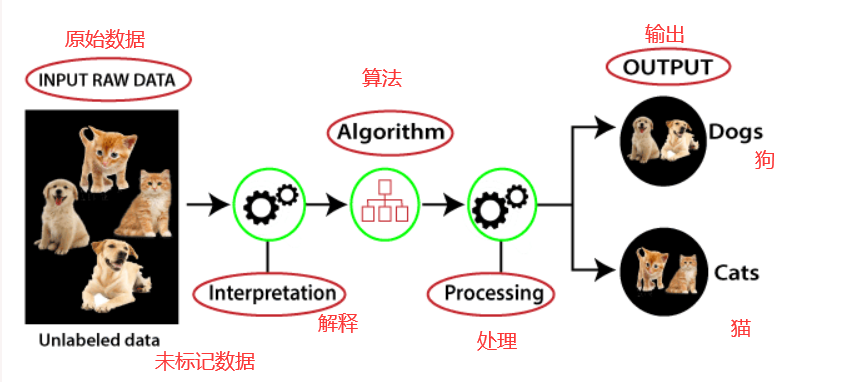
聚类(clustering)
聚类是一种将对象分组为聚类的方法,使得具有最多相似性的对象保留在一个组中,并且与另一组的对象具有较少或没有相似性。聚类分析发现数据对象之间的共性,并根据这些共性的存在和不存在对它们进行分类
异常检测(anomaly detection)
find unusual data points
用于检测异常事件(eg:金融系统的异常交易与异常事件)
降维(dimensionality reduction)
compress data using fewer numbers
将一个大数据集压缩成一个小得多的数据集,同时尽可能少的丢失数据














 2379
2379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









