










1.简介
本篇文章开始,会陆续学习一些其它的常用的非线性分类方法,虽然它们同属于非线性方法,但是它们与前面介绍的稍有不同,原理上具有特殊性,这篇就来学习近邻法中的最近邻法。最近邻法是基于这样一个基本思想的:把一个新样本逐一与已知分好类的样本进行比较,然后把与其距离最近的样本类别作为它的类别,这种思想是不是很好理解,有点类似于我们学英语中的就近原则。
2.原理
已知有标签样本集 ,假设有c类,
,假设有c类, ;
;
定义两个样本间的距离度量为 ;
;
任务:对未知样本x,找出样本集Xn中与之距离最近的样本;
设与未知样本x距离最近的样本为 ,上述目标可以形式化为:
,上述目标可以形式化为:
 (1)
(1)
那么,就可以未知样本x决策为 ,而这种分类方法就成为最近邻决策;
,而这种分类方法就成为最近邻决策;
根据公式(1)写出每一类wi对应的判别函数:
 (2)
(2)
决策规则为各类的判别函数进行比较,即:
若 ,则
,则 ;
;
实际应用中,可以根据需要选择不同的距离度量,当然也可以利用相似性度量,即把未知样本的类别决策为已知样本中与之最相似的那个样本的类别(也就是相似度最大)。
3.错误率分析
假设在样本集下,最近邻决策的平均错误率为 ,有:
,有:
 (3)
(3)
设贝叶斯错误率(即理论上最优的错误率)为 ,当样本足够多或趋于无穷多,即
,当样本足够多或趋于无穷多,即 ,令
,令 ,则下面结论可以证明:
,则下面结论可以证明:
 (4)
(4)
上述结论画图表示就是:
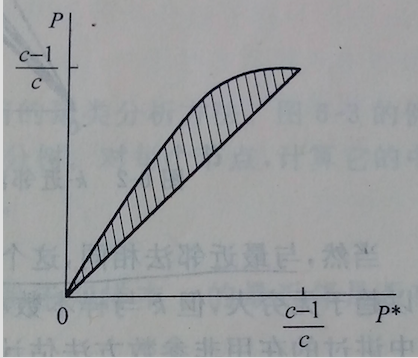
上图中阴影区域就是最近邻法决策的平均错误率,横轴的P*就是上面的贝叶斯错误率,可以看出,其上界不会超出贝叶斯错误率的2倍,而下界则有可能逼近贝叶斯错误率,但前提是样本无限多。如果样本数有限,有时也会得到不错的分类结果,但是不满足公式(4),并且样本太少会导致样本分布的偶然性,就会影响最近邻法的性能,尤其是样本数据内在规律复杂、类别间出现重叠以及有噪声的情况。
等学习了k近邻,你就会发现,最近邻其实只是k近邻的而一个特殊形式,就是k=1。















 1169
1169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









