YUV是编译true-color颜色空间(color space)的种类,Y'UV, YUV, YCbCr,YPbPr等专有名词都可以称为YUV,彼此有重叠。“Y”表示明亮度(Luminance、Luma),“U”和“V”则是色度与浓度(Chrominance、Chroma)
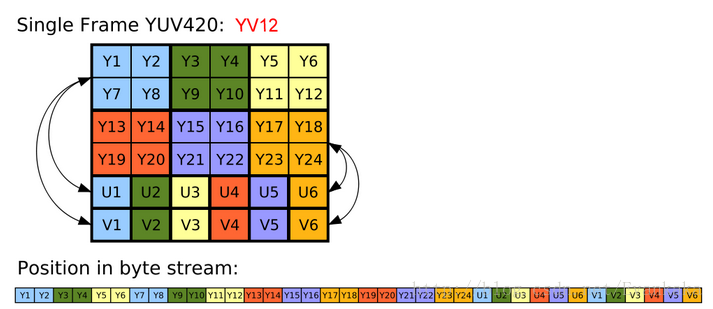
YV12是常用的CODEC格式,它的格式如下:
图1中:

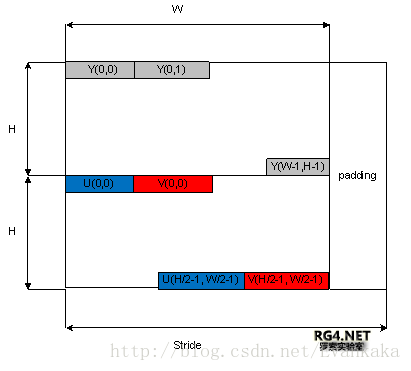
W即图像的宽度,H即图像的高度,Stride表示图像行的跨度,超出W部分为填充数据,主要目的是为了字节对齐,一般以16字节或者或者32字节对齐居多。
NV12是英特尔定义的视频格式,它在英特尔硬件平台上是原生态支持,它的格式如下:
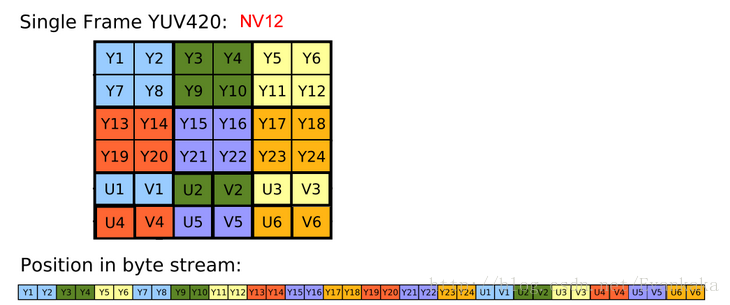
在YV12中U和V都是连续排布的,而在NV12中,U和V就交错排布的。看到内存中的排布很清楚,先开始都是Y,之后的都是U1V1U2V2的交错式排布。
补充知识:
YUV格式
主要的采样格式有YCbCr 4:2:0、YCbCr 4:2:2、YCbCr 4:1:1和 YCbCr 4:4:4。其中YCbCr 4:1:1 比较常用,其含义为:每个点保存一个 8bit 的亮度值(也就是Y值),每 2x2 个点保存一个 Cr 和Cb 值,图像在肉眼中的感觉不会起太大的变化。所以, 原来用 RGB(R,G,B 都是 8bit unsigned) 模型, 1个点需要 8x3=24 bits(如下图第一个图),(全采样后,YUV仍各占8bit)。按4:1:1采样后,而现在平均仅需要 8+(8/4)+(8/4)=12bits(4个点,8*4(Y)+8(U)+8(V)=48bits), 平均每个点占12bits(如下图第二个图)。这样就把图像的数据压缩了一半。上边仅给出了理论上的示例,在实际数据存储中是有可能是不同的,下面给出几种具体的存储形式:
(1) YUV 4:4:4
YUV三个信道的抽样率相同,因此在生成的图像里,每个象素的三个分量信息完整(每个分量通常8比特),经过8比特量化之后,未经压缩的每个像素占用3个字节。
下面的四个像素为: [Y0 U0 V0] [Y1 U1 V1] [Y2 U2 V2] [Y3 U3 V3]
存放的码流为: Y0 U0 V0 Y1 U1 V1 Y2 U2 V2 Y3 U3 V3
(2) YUV 4:2:2
每个色差信道的抽样率是亮度信道的一半,所以水平方向的色度抽样率只是4:4:4的一半。对非压缩的8比特量化的图像来说,每个由两个水平方向相邻的像素组成的宏像素需要占用4字节内存。
下面的四个像素为:[Y0 U0 V0] [Y1 U1 V1] [Y2 U2 V2] [Y3 U3 V3]
存放的码流为:Y0 U0 Y1 V1 Y2 U2 Y3 V3
映射出像素点为:[Y0 U0 V1] [Y1 U0 V1] [Y2 U2 V3] [Y3 U2 V3]
(3) YUV 4:1:1
4:1:1的色度抽样,是在水平方向上对色度进行4:1抽样。对于低端用户和消费类产品这仍然是可以接受的。对非压缩的8比特量化的视频来说,每个由4个水平方向相邻的像素组成的宏像素需要占用6字节内存。
下面的四个像素为: [Y0 U0 V0] [Y1 U1 V1] [Y2 U2 V2] [Y3 U3 V3]
存放的码流为: Y0 U0 Y1 Y2 V2 Y3
映射出像素点为:[Y0 U0 V2] [Y1 U0 V2] [Y2 U0 V2] [Y3 U0 V2]
(4)YUV4:2:0
4:2:0并不意味着只有Y,Cb而没有Cr分量。它指得是对每行扫描线来说,只有一种色度分量以2:1的抽样率存储。相邻的扫描行存储不同的色度分量,也就是说,如果一行是4:2:0的话,下一行就是4:0:2,再下一行是4:2:0...以此类推。对每个色度分量来说,水平方向和竖直方向的抽样率都是2:1,所以可以说色度的抽样率是4:1。对非压缩的8比特量化的视频来说,每个由2x2个2行2列相邻的像素组成的宏像素需要占用6字节内存。
下面八个像素为:[Y0 U0 V0] [Y1 U1 V1] [Y2 U2 V2] [Y3 U3 V3]
[Y5 U5 V5] [Y6 U6 V6] [Y7U7 V7] [Y8 U8 V8]
存放的码流为:Y0 U0 Y1 Y2 U2 Y3
Y5 V5 Y6 Y7 V7 Y8
映射出的像素点为:[Y0 U0 V5] [Y1 U0 V5] [Y2 U2 V7] [Y3 U2 V7]
[Y5 U0 V5] [Y6 U0 V5] [Y7U2 V7] [Y8 U2 V7]

























 5255
5255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









