







人工神经网络(ANN)
一、什么是人工神经网络
人工神经网络的灵感来自其生物学对应物。生物神经网络使大脑能够以复杂的方式处理大量信息。大脑的生物神经网络由大约1000亿个神经元组成,这是大脑的基本处理单元。神经元通过彼此之间巨大的连接(称为突触)来执行其功能。
人体神经元模型,下如图:
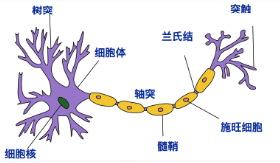
- 接收区(receptive zone):树突接收到输入信息。
- 触发区(trigger zone):位于轴突和细胞体交接的地方,决定是否产生神经冲动。
- 传导区(conducting zone):由轴突进行神经冲动的传递。
- 输出区(output zone):神经冲动的目的就是要让神经末梢,突触的神经递质或电力释出,才能影响下一个接受的细胞(神经元、肌肉细胞或是腺体细胞),此称为突触传递。
人工神经网络定义为:人工神经网络是一种由具有自适应性的简单单元构成的广泛并行互联的网络,它的组织结构能够模拟生物神经系统对真实世界所做出的交互反应。
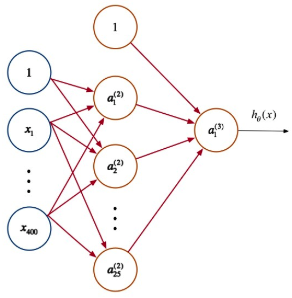
人工神经网络的结构为
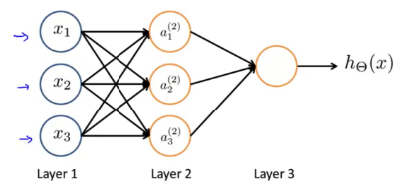
- 输入层:输入层接收特征向量 x 。
- 输出层:输出层产出最终的预测 h 。
- 隐含层:隐含层介于输入层与输出层之间,之所以称之为隐含层,是因为当中产生的值并不像输入层使用的样本矩阵 X 或者输出层用到的标签矩阵 y 那样直接可见。
- 人工神经网络由一个输入层和一个输出层组成,其中输入层从外部源(数据文件,图像,硬件传感器等)接收数据,一个或多个隐藏层处理数据,输出层提供一个或多个数据点基于网络的功能。根据不同的问题,可以加入多个隐藏层,由图中这种全连接改为部 分连接,甚至是环形连接等。
二、人工神经网络的运行原理
人工神经网络的强大之处在于,它拥有很强的学习能力。在得到一个训练集之后,它能通过学习提取所观察事物的各个部分的特征,将特征之间用不同网络节点连接,通过训练连接的网络权重,改变每一个连接的强度,直到顶层的输出得到正确的答案。
神经网络算法大致过程:
- 第一步,我们要预先设定一种网络结构和激活函数, 这一步其实很困难,因为网络结构可以无限拓展,要知道什么样的结构才符合我们的问题需要做大量的试验。
- 第二步,初始化模型中的权重。 模型中的每一个连接都会有一个权重,在初始化的时候可以都随机给予一个值。
- 第三步,就是根据输入数据和权重来预测结果。 由于最开始的参数都是随机设置的,所以获得的结果肯定与真实的结果差距比较大,所以在这里要计算一个误差,误差反映了预测结果和真实结果的差距有多大。
- 最后一步,模型要调节权重 。这里我们可以参与的就是需要设置一个 “学习率”,这个学习率是针对误差的,每次获得误差后,连接上的权重都会按照误差的这个比率来进行调整,从而期望在下次计算时获得一个较小的误差。经过若干次循环这个过程,我们可以选择达到一个比较低的损失值的时候停止并输出模型,也可以选择一个确定的循环轮次来结束。
神经网络每层都包含有若干神经元,层间的神经元通过权值矩阵 Θl 连接。一次信息传递过程可以如下描述:
第 j 层神经元接收上层传入的刺激(神经冲动):
该激活函数(activation function)g 作用后,会产生一个激活向量 aj 。 aji 表示的就是 j 层第 i
个神经元获得的激活值(activation):
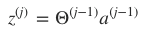
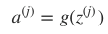
人工神经网络算法主要是前向传播: 刺激由前一层传向下一层,故而称之为前向传递。
对于非线性分类问题,逻辑回归会使用多项式扩展特征,导致维度巨大的特征向量出现,而在神经网络中,并不会增加特征的维度,不是扩展神经网络输入层的规模,而是通过增加隐含层,调节隐含层中的权值,从而不断优化特征,前向传播过程每次在神经元上产出的激励值都可看做是优化后的特征。
代价函数
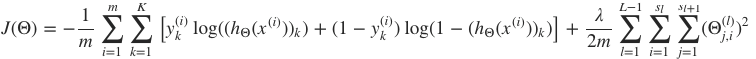

矩阵表示方法为:
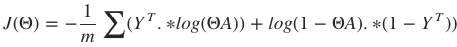
其中, .∗ 代表点乘操作,A∈R(K×m) 为所有样本对应的输出矩阵,其每一列对应一个样本的输出, Y∈R(m×K) 为标签矩阵,其每行对应一个样本的类型。
三、神经网络训练过程
参考:https://zhuanlan.zhihu.com/p/111288383
人工神经网络首先为神经元之间的连接权重分配随机值。ANN正确而准确地执行其任务的关键是将这些权重调整为正确的数字。 但是找到合适的权重并不是一件容易的事,特别是处理多层和成千上万的神经元时。
通过对带有注释示例的网络进行“培训”来完成此校准。基本上,训练期间发生的事情是网络进行自我调整以从数据中收集特定模式。同样,对于图像分类器网络,当您使用质量示例训练AI模型时,每一层都会检测到特定的特征类别。例如,第一层可能检测到水平和垂直边缘,第二层可能检测到拐角和圆形。在网络的更深处,更深的层次将开始挑选出更高级的功能,例如面部和物体。

神经网络的每一层都将从输入图像中提取特定特征。
当您通过训练有素的神经网络运行新图像时,调整后的神经元权重将能够提取正确的特征并准确确定图像属于哪个输出类别。
训练神经网络的挑战之一是找到正确数量和质量的训练示例。而且,训练大型AI模型需要大量的计算资源。为了克服这一挑战,许多工程师使用“ 转移学习”(一种培训技术),您可以采用预先训练的模型,并使用针对特定领域的新示例对其进行微调。当已经有一个与您的用例接近的AI模型时,转移学习特别有效。
四、神经网络 MLPClassifier 参数用法
clf = MLPClassifier(solver=’sgd’, activation=’relu’,alpha=1e-4,
hidden_layer_sizes=(50,50), random_state=1,
max_iter=10,verbose=10,learning_rate_init=.1)
参数说明:
- hidden_layer_sizes :例如hidden_layer_sizes=(50, 50),表示有两层隐藏层,第一层隐藏层有50个神经元,第二层也有50个神经元。
- activation :{‘identity’, ‘logistic’, ‘tanh’, ‘relu’}, 默认‘relu
- identity: no-op activation, useful to implement linear bottleneck, 返回f(x) = x
- logistic:the logistic sigmoid function, returns f(x) = 1 / (1 + exp(-x)).
- tanh:the hyperbolic tan function, returns f(x) = tanh(x).
- relu:the rectified linear unit function, returns f(x) = max(0, x)
- solver: {‘lbfgs’, ‘sgd’, ‘adam’}, 默认adam,用来优化权重
- lbfgs:quasi-Newton方法的优化器
- sgd:随机梯度下降
- adam: Kingma, Diederik, and Jimmy Ba提出的机遇随机梯度的优化器 注意:默认solver ‘adam’在相对较大的数据集上效果比较好(几千个样本或者更多),对小数据集来说,lbfgs收敛更快效果也更好。
- alpha :float,可选的,默认0.0001,正则化项参数。
- learning_rate :学习率,用于权重更新,只有当solver为’sgd’时使用,{‘constant’,’invscaling’, ‘adaptive’},默认constant
- constant: 有’learning_rate_init’给定的恒定学习率
- incscaling:随着时间t使用’power_t’的逆标度指数不断降低学习率learning_rate_ ,effective_learning_rate = learning_rate_init / pow(t, power_t)
- adaptive:只要训练损耗在下降,就保持学习率为’learning_rate_init’不变,当连续两次不能降低训练损耗或验证分数停止升高至少tol时,将当前学习率除以5.
- random_state:int 或RandomState,可选,默认None,随机数生成器的状态或种子。
- max_iter: int,可选,默认200,最大迭代次数。
- verbose : bool, 可选, 默认False,是否将过程打印到stdout。
五、人工神经网络算法实现
属性说明:
- classes_:每个输出的类标签
- loss_:损失函数计算出来的当前损失值
- coefs_:列表中的第i个元素表示i层的权重矩阵
- intercepts_:列表中第i个元素代表i+1层的偏差向量
- n_iter_ :迭代次数
- n_layers_:层数
- n_outputs_:输出的个数
- out_activation_:输出激活函数的名称。
1.首先简单使用sklearn中的neural_network的例子
- 实例1
from sklearn.neural_network import MLPClassifier
X = [[0., 0.], [1., 1.]]
y = [0, 1]
mlp = MLPClassifier(solver='lbfgs', alpha=1e-5,hidden_layer_sizes=(5, 5), random_state=1)
mlp.fit(X, y)
print(mlp.n_layers_) # n_layers_:层数
print(mlp.n_iter_) # n_iter_ :迭代次数
print(mlp.loss_) # loss_:损失函数计算出来的当前损失值
print(mlp.out_activation_)# out_activation_:输出激活函数的名称。
输出为:
4
13
0.00014123347253650121
logistic
2.用神经网络训练iris数据集
- 实例2
from sklearn import datasets
import numpy as np
from sklearn.neural_network import MLPClassifier
np.random.seed(0)
iris=datasets.load_iris()
iris_x=iris.data
iris_y=iris.target
indices = np.random.permutation(len(iris_x))
# 训练数据集
iris_x_train = iris_x[indices[:-10]]
iris_y_train = iris_y[indices[:-10 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4509
4509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











