







现在到了自动编码器和解码器,同样,先练几遍代码,再去理解
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
import numpy as np
# torch.manual_seed(1) # reproducible
# Hyper Parameters
EPOCH = 10
BATCH_SIZE = 64
LR = 0.005 # learning rate
DOWNLOAD_MNIST = False
N_TEST_IMG = 5
# Mnist digits dataset
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST, # download it if you don't have it
)
# plot one example
print(train_data.train_data.size()) # (60000, 28, 28)
print(train_data.train_labels.size()) # (60000)
plt.imshow(train_data.train_data[2].numpy(), cmap='gray')
plt.title('%i' % train_data.train_labels[2])
plt.show()
# Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.Tanh(),
nn.Linear(128, 64),
nn.Tanh(),
nn.Linear(64, 12),
nn.Tanh(),
nn.Linear(12, 3), # compress to 3 features which can be visualized in plt
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.Tanh(),
nn.Linear(12, 64),
nn.Tanh(),
nn.Linear(64, 128),
nn.Tanh(),
nn.Linear(128, 28*28),
nn.Sigmoid(), # compress to a range (0, 1)
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
autoencoder = AutoEncoder()
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=LR)
loss_func = nn.MSELoss()
# initialize figure
f, a = plt.subplots(2, N_TEST_IMG, figsize=(5, 2))
plt.ion() # continuously plot
# original data (first row) for viewing
view_data = train_data.train_data[:N_TEST_IMG].view(-1, 28*28).type(torch.FloatTensor)/255.
for i in range(N_TEST_IMG):
a[0][i].imshow(np.reshape(view_data.data.numpy()[i], (28, 28)), cmap='gray'); a[0][i].set_xticks(()); a[0][i].set_yticks(())
for epoch in range(EPOCH):
for step, (x, b_label) in enumerate(train_loader):
b_x = x.view(-1, 28*28) # batch x, shape (batch, 28*28)
b_y = x.view(-1, 28*28) # batch y, shape (batch, 28*28)
encoded, decoded = autoencoder(b_x)
loss = loss_func(decoded, b_y) # mean square error
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step % 100 == 0:
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy())
# plotting decoded image (second row)
_, decoded_data = autoencoder(view_data)
for i in range(N_TEST_IMG):
a[1][i].clear()
a[1][i].imshow(np.reshape(decoded_data.data.numpy()[i], (28, 28)), cmap='gray')
a[1][i].set_xticks(()); a[1][i].set_yticks(())
plt.draw(); plt.pause(0.05)
plt.ioff()
plt.show()
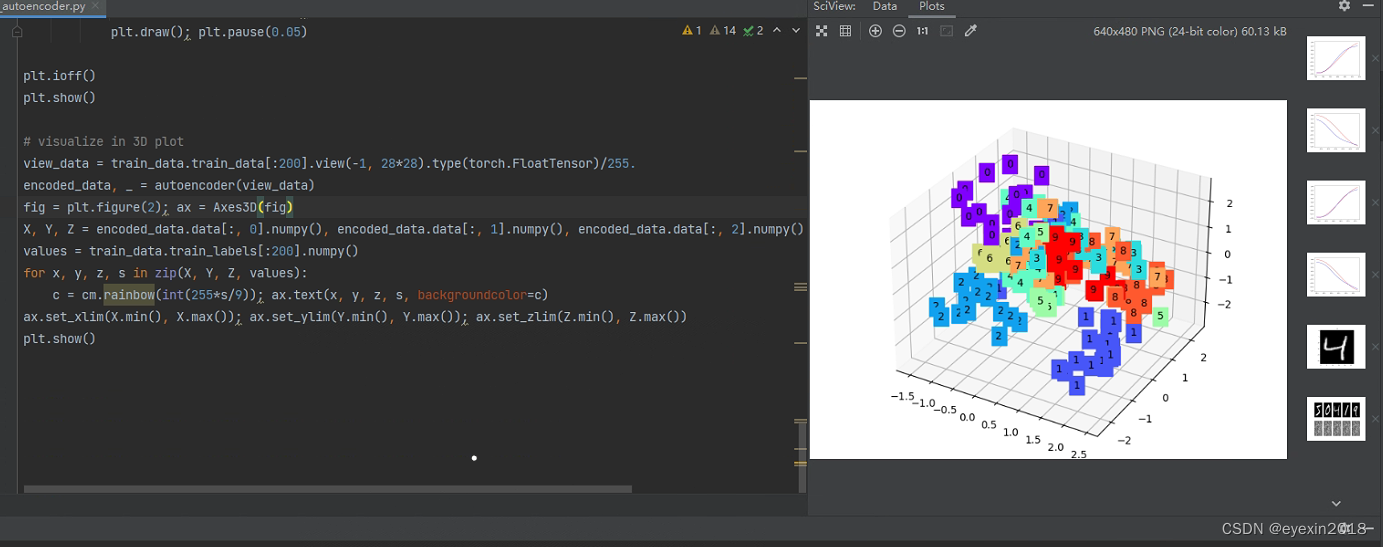
# visualize in 3D plot
view_data = train_data.train_data[:200].view(-1, 28*28).type(torch.FloatTensor)/255.
encoded_data, _ = autoencoder(view_data)
fig = plt.figure(2); ax = Axes3D(fig)
X, Y, Z = encoded_data.data[:, 0].numpy(), encoded_data.data[:, 1].numpy(), encoded_data.data[:, 2].numpy()
values = train_data.train_labels[:200].numpy()
for x, y, z, s in zip(X, Y, Z, values):
c = cm.rainbow(int(255*s/9)); ax.text(x, y, z, s, backgroundcolor=c)
ax.set_xlim(X.min(), X.max()); ax.set_ylim(Y.min(), Y.max()); ax.set_zlim(Z.min(), Z.max())
plt.show()
好,当练习了几遍代码后,对整体有点了解了,然后再理解每一步是什么作用。
问:编码器和解码器设计的作用是什么?
答:编码器和解码器在AutoEncoder中的设计有以下作用:
编码器(Encoder):编码器负责将输入数据映射到一个低维度的表示,也称为编码或隐藏层。通过降低输入数据的维度,编码器可以提取出数据的关键特征,并将其压缩成更紧凑的表示形式。这种压缩表示通常具有良好的特征表达能力,可以用于后续任务,如降维、特征提取或数据可视化。
解码器(Decoder):解码器负责从编码器获得的低维度表示中重构原始输入数据。它将压缩表示解码成与原始输入具有相同维度的输出。解码器的目标是尽可能准确地重建原始数据,以便最小化重构误差。通过解码器的工作,AutoEncoder可以通过低维表示重新生成与原始数据相似的数据,实现数据的重建或还原。
编码器和解码器的结合使得AutoEncoder能够学习到数据的压缩表示并用于重构,通过这种方式实现了一种自监督学习的方式。在训练过程中,AutoEncoder的目标是最小化重构误差,使得解码器能够尽可能准确地重建原始输入,同时编码器能够学习到数据的有用特征。
再问:这样降维然后又增加维度,不就是等于什么也没做吗?
再答:实际上,AutoEncoder的目标并不仅仅是将数据降维然后再增加维度,而是通过压缩和解压缩过程来学习数据的有用表示。
虽然编码器将数据压缩到较低维度的表示,但这个表示通常不仅仅是原始数据的简单副本。通过限制编码器的容量,AutoEncoder被迫学习到数据的最重要特征,并忽略一些冗余和噪音。因此,编码器产生的低维表示往往是数据的更高级别的抽象。
解码器的作用是将这个抽象的低维表示解压缩回原始数据空间。尽管维度增加,但解码器在这个过程中通过学习从低维表示中恢复原始数据的映射来捕捉数据的结构和模式。解码器的目标是最小化重构误差,以尽量准确地还原原始数据。
因此,AutoEncoder通过编码器和解码器的组合,可以学习到数据的紧凑表示,该表示捕捉了数据中的关键特征。这种低维表示可以用于诸如数据压缩、特征提取、数据可视化和异常检测等任务。虽然编码器和解码器都涉及维度的变化,但它们的目的是通过学习有用的数据表示来提供更高级别的抽象和数据重建,而不仅仅是简单地降低和增加维度。
打印出来了3D的分类图片














 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









