









这里的代码使用的2025-03-31更新的代码,里面包含了ragflow还未发布的新功能。
想要了解ragflow,表结构永远是绕不过去。我们连上ragflow的数据库,可以看到,创建有18张表。
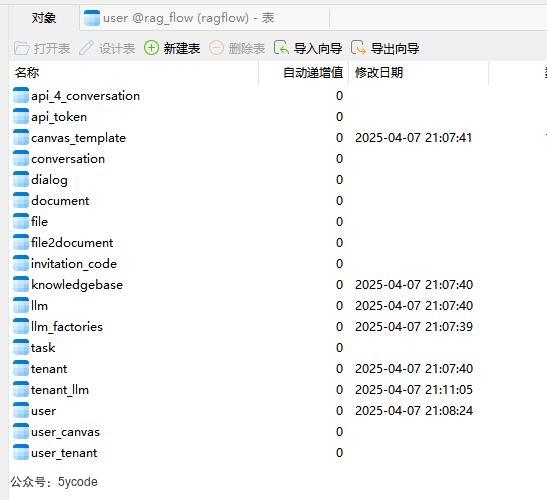
这些表具有什么含义?今天我们结合ragflow的代码、功能、和表来看一看。
在ragflow的代码中api/db/db_models.py,我们先看一下ragflow封装的继承关系。
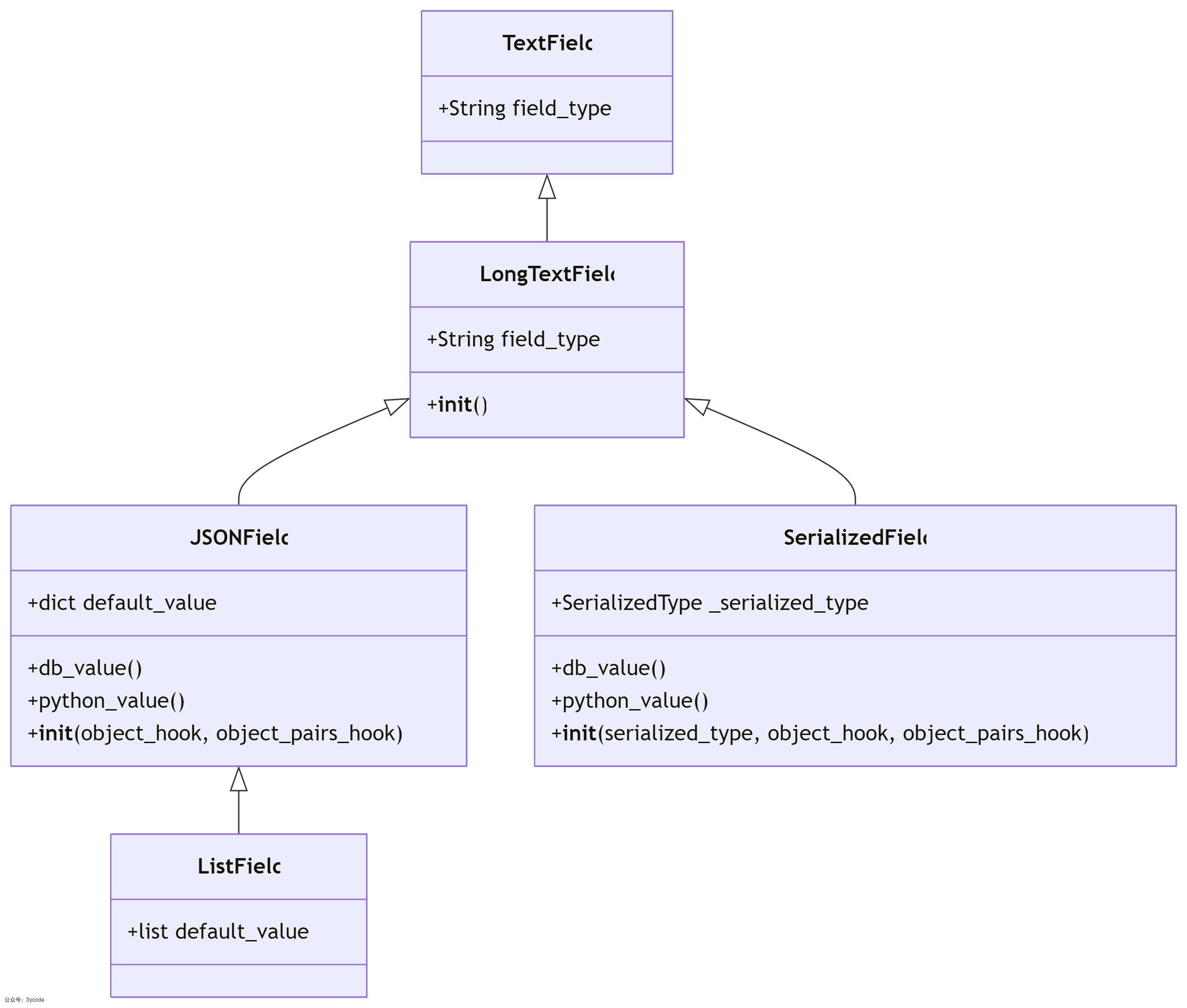
TextField是所有文本字段的基类LongTextField继承自 TextField,添加数据库类型适配能力,解决了数据库的兼容性问题,支持MYSQL和POSTGRES两种数据库JSONField:JSON序列化,结构化配置数据SerializedField:Pickle/JSON可选,复杂对象存储ListField标签/列表数据
ragflow通过BaseModel把数据库的操作基于Peewee ORM进行了封装。
class BaseModel(Model):
# 时间戳字段(存储毫秒级时间戳)
create_time = BigIntegerField(null=True, index=True)
# 日期时间字段(自动转换时间戳为可读格式)
create_date = DateTimeField(null=True, index=True)
update_time = BigIntegerField(null=True, index=True)
update_date = DateTimeField(null=True, index=True)
@classmethod
def query(cls, reverse=None, order_by=None, **kwargs):
@classmethod
def insert(cls, __data=None, **insert):
if isinstance(__data, dict) and __data:
__data[cls._meta.combined["create_time"]] = utils.current_timestamp()
if insert:
insert["create_time"] = utils.current_timestamp()
return super().insert(__data, **insert)
- 通过一些公共字段,自动维护记录的创建/更新时间
- 通过
query对查询进行了扩展 - 这里的代码封装比较健全了,可以直接复用。
class PooledDatabase(Enum):
MYSQL = PooledMySQLDatabase
POSTGRES = PooledPostgresqlDatabase
@singleton
class BaseDataBase:
def __init__(self):
database_config = settings.DATABASE.copy()
db_name = database_config.pop("name")
# 根据配置动态选择数据库驱动
self.database_connection = PooledDatabase[settings.DATABASE_TYPE.upper()].value(db_name, **database_config)
class PostgresDatabaseLock:
class MysqlDatabaseLock:
class DatabaseLock(Enum):
MYSQL = MysqlDatabaseLock
POSTGRES = PostgresDatabaseLock
DB = BaseDataBase().database_connection
DB.lock = DatabaseLock[settings.DATABASE_TYPE.upper()].value
- 这段代码主要是实现了一个支持多数据库的分布式锁,结合连接池和自动重试机制
- 通过
DatabaseLock抽象了数据库锁的,通过DB.lock动态绑定对应数据库类型的视线 PostgresDatabaseLock和MysqlDatabaseLock分别是两种不同数据库的代码实现。
@DB.connection_context()
def init_database_tables(alter_fields=[]):
members = inspect.getmembers(sys.modules[__name__], inspect.isclass)
table_objs = []
create_failed_list = []
for name, obj in members:
if obj != DataBaseModel and issubclass(obj, DataBaseModel):
table_objs.append(obj)
logging.debug(f"start create table {obj.__name__}")
try:
obj.create_table()
logging.debug(f"create table success: {obj.__name__}")
except Exception as e:
logging.exception(e)
create_failed_list.append(obj.__name__)
if create_failed_list:
logging.error(f"create tables failed: {create_failed_list}")
raise Exception(f"create tables failed: {create_failed_list}")
migrate_db()
- 通过上面的这段代码,实现了数据库表的自动创建
sys.modules[__name__]获取当前模块的class对象,- 然后操作所有
DataBaseModel的子类,进行create_table() - 通过
migrate_db添加了一些新字段
class Tenant(DataBaseModel):
id = CharField(max_length=32, primary_key=True)
name = CharField(max_length=100, null=True, help_text="Tenant name", index=True)
public_key = CharField(max_length=255, null=True, index=True)
llm_id = CharField(max_length=128, null=False, help_text="default llm ID", index=True)
embd_id = CharField(max_length=128, null=False, help_text="default embedding model ID", index=True)
asr_id = CharField(max_length=128, null=False, help_text="default ASR model ID", index=True)
img2txt_id = CharField(max_length=128, null=False, help_text="default image to text model ID", index=True)
rerank_id = CharField(max_length=128, null=False, help_text="default rerank model ID", index=True)
tts_id = CharField(max_length=256, null=True, help_text="default tts model ID", index=True)
parser_ids = CharField(max_length=256, null=False, help_text="document processors", index=True)
credit = IntegerField(default=512, index=True)
status = CharField(max_length=1, null=True, help_text="is it validate(0: wasted, 1: validate)", default="1", index=True)
class Meta:
db_table = "tenant"
- 通过继承
DataBaseModel定义了表 - 通过
help_text描述了表结构字段 - 通过
db_table定义了表名,典型的ORM框架
不看代码不知道,ragflow的文档都在代码里。
表结构说明
通用字段create_time、create_date、update_time、update_date 就不再往表里添加了。
用户管理模块
user- 核心用户表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| access_token | VARCHAR(255) | 访问令牌 | |
| nickname | VARCHAR(100) | ✔ | 昵称 |
| password | VARCHAR(255) | 密码 | |
| VARCHAR(255) | ✔ | 邮箱 | |
| avatar | TEXT | 头像Base64 | |
| language | VARCHAR(32) | 语言偏好 | |
| color_schema | VARCHAR(32) | 颜色主题 | |
| timezone | VARCHAR(64) | 时区 | |
| last_login_time | DATETIME | 最后登录时间 | |
| is_authenticated | CHAR(1) | ✔ | 认证状态 |
| is_active | CHAR(1) | ✔ | 激活状态 |
| is_anonymous | CHAR(1) | ✔ | 匿名状态 |
| login_channel | VARCHAR(255) | 登录渠道 | |
| status | CHAR(1) | 账户状态 | |
| is_superuser | BOOLEAN | 超级用户 |
- 作用:存储系统所有用户账户信息,包含认证、偏好设置等基础数据
- 核心字段:email(登录账号)、password、access_token
- 业务关系:与user_tenant构成多对多关系,通过tenant关联租户资源
ragflow没有直接维护用户的地方,是以工作空间为核心,一个用户注册以后就是一个独立的工作空间。工作空间就是租户。
tenant- 租户表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| name | VARCHAR(100) | 租户名称 | |
| public_key | VARCHAR(255) | 公钥 | |
| llm_id | VARCHAR(128) | ✔ | 默认LLM ID |
| embd_id | VARCHAR(128) | ✔ | 默认嵌入模型ID |
| asr_id | VARCHAR(128) | ✔ | 默认ASR模型ID |
| img2txt_id | VARCHAR(128) | ✔ | 默认图片转文本ID |
| rerank_id | VARCHAR(128) | ✔ | 默认重排序模型ID |
| tts_id | VARCHAR(256) | 默认TTS模型ID | |
| parser_ids | VARCHAR(256) | ✔ | 文档处理器 |
| credit | INTEGER | 信用额度 | |
| status | CHAR(1) | 状态 |
- 作用:定义独立租户空间,包含租户级AI模型配置和资源配额 ,也就是每个人都可以设定指定的默认模型
- 关键配置:llm_id/embd_id等默认模型配置、parser_ids文档处理器
- 业务特点:每个租户相当于一个独立工作空间,拥有完整的功能体系
user_tenant- 用户租户关联表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| user_id | CHAR(32) | ✔ | 用户ID |
| tenant_id | CHAR(32) | ✔ | 租户ID |
| role | VARCHAR(32) | ✔ | 用户角色 |
| invited_by | CHAR(32) | ✔ | 邀请人 |
| status | CHAR(1) | 状态 |
- 作用:记录用户在不同租户中的成员关系和角色权限
- 典型场景:一个用户可属于多个租户,在不同租户中担任不同角色(如管理员/成员)
通过此表就是团队。
invitation_code- 邀请码表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| code | VARCHAR(32) | ✔ | 邀请码 |
| visit_time | DATETIME | 访问时间 | |
| user_id | CHAR(32) | 使用用户 | |
| tenant_id | CHAR(32) | 关联租户 | |
| status | CHAR(1) | 状态 |
- 作用:管理租户邀请系统,控制用户加入租户的权限
- 生命周期:创建→被使用→状态变更为已使用(1→0)
模型管理模块
llm_factories - AI厂商表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| name | VARCHAR(128) | ✔ | 主键/厂商名称 |
| logo | TEXT | Logo Base64 | |
| tags | VARCHAR(255) | ✔ | 标签分类 |
| status | CHAR(1) | 状态 |
- 作用:维护支持的AI服务厂商元数据(如OpenAI/Anthropic)
- 核心功能:厂商logo展示、服务类型标记(tags字段)
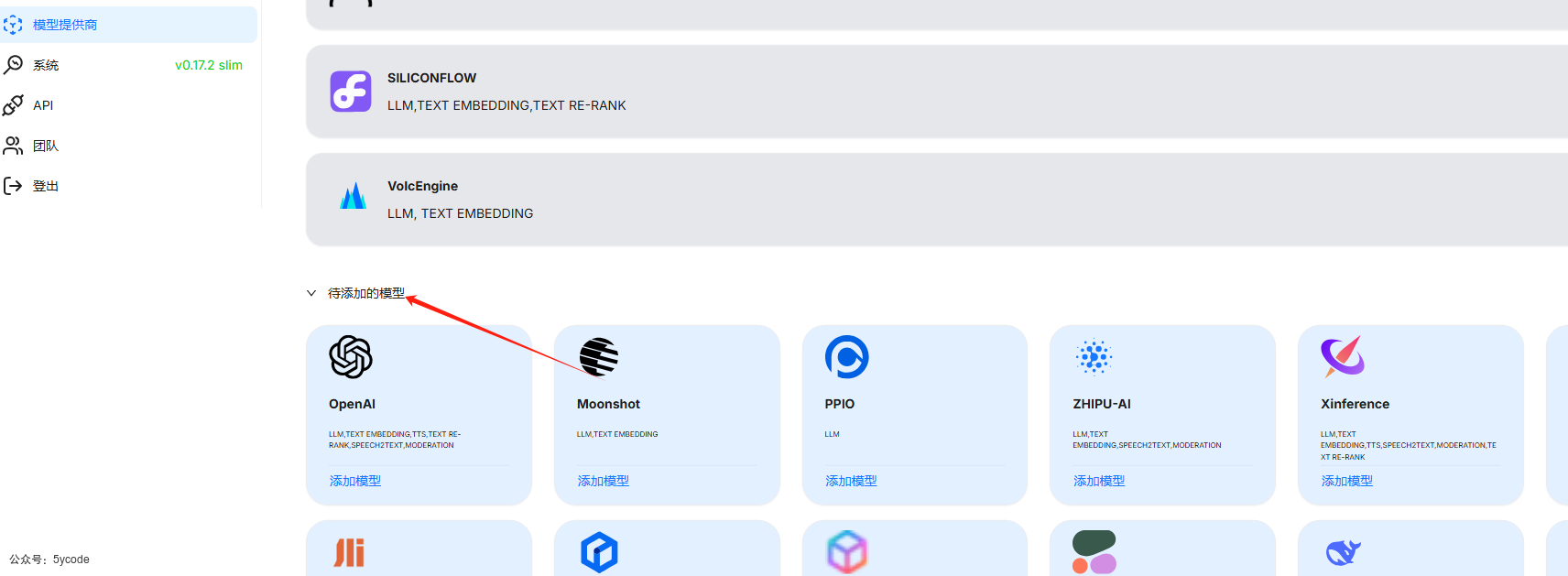
这里的模型供应商
llm- 模型表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| llm_name | VARCHAR(128) | ✔ | 模型名称 |
| model_type | VARCHAR(128) | ✔ | 模型类型 |
| fid | VARCHAR(128) | ✔ | 厂商ID |
| max_tokens | INTEGER | 最大token数 | |
| tags | VARCHAR(255) | ✔ | 标签 |
| is_tools | BOOLEAN | ✔ | 支持工具 |
| status | CHAR(1) | 状态 |
- 作用:全局模型注册中心,记录所有可用AI模型
- 关键属性:model_type区分LLM/Embedding等类型,max_tokens限制
这个就是我们添加厂商以后能看到一堆模型
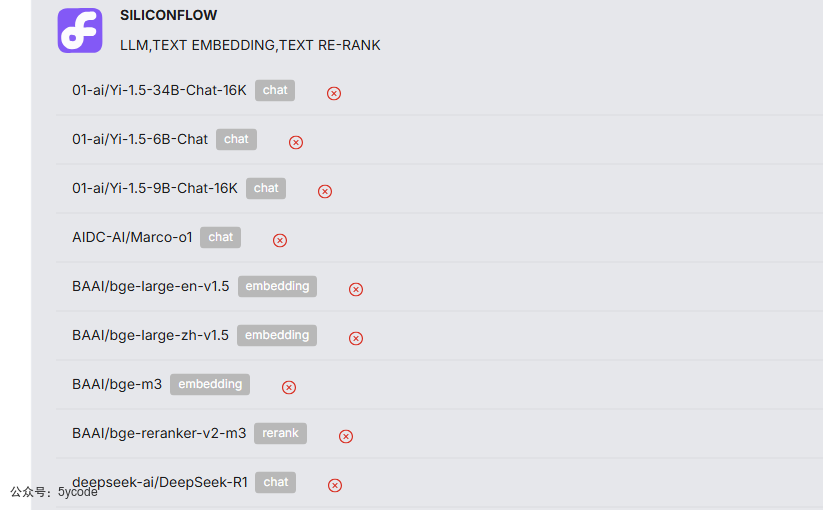
tenant_llm-租户模型配置表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| tenant_id | CHAR(32) | ✔ | 租户ID |
| llm_factory | VARCHAR(128) | ✔ | 厂商名称 |
| model_type | VARCHAR(128) | 模型类型 | |
| llm_name | VARCHAR(128) | 模型名称 | |
| api_key | VARCHAR(2048) | API密钥 | |
| api_base | VARCHAR(255) | API地址 | |
| max_tokens | INTEGER | 最大token数 | |
| used_tokens | INTEGER | 已用token数 |
- 作用:租户级模型权限和配额管理
- 核心功能:存储api_key等敏感配置,跟踪token使用量
- 业务规则:同一租户可配置多个厂商的多个模型

tenant_langfuse - 观测平台配置
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| tenant_id | CHAR(32) | ✔ | 主键/租户ID |
| secret_key | VARCHAR(2048) | ✔ | 密钥 |
| public_key | VARCHAR(2048) | ✔ | 公钥 |
| host | VARCHAR(128) | ✔ | 主机地址 |
- 作用:存储租户的Langfuse观测平台集成配置
- 典型用途:对话记录追踪和AI性能监控
知识库模块
knowledgebase- 知识库表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| avatar | TEXT | 头像Base64 | |
| tenant_id | CHAR(32) | ✔ | 租户ID |
| name | VARCHAR(128) | ✔ | 知识库名称 |
| language | VARCHAR(32) | 语言 | |
| description | TEXT | 描述 | |
| embd_id | VARCHAR(128) | ✔ | 嵌入模型ID |
| permission | VARCHAR(16) | ✔ | 权限范围 |
| created_by | CHAR(32) | ✔ | 创建人 |
| doc_num | INTEGER | 文档数 | |
| token_num | INTEGER | Token数 | |
| chunk_num | INTEGER | 分块数 | |
| similarity_threshold | FLOAT | 相似度阈值 | |
| vector_similarity_weight | FLOAT | 向量权重 | |
| parser_id | VARCHAR(32) | ✔ | 解析器ID |
| parser_config | JSON | ✔ | 解析配置 |
| pagerank | INTEGER | 页面排名 | |
| status | CHAR(1) | 状态 |
- 作用:定义结构化知识存储单元,包含处理规则
- 核心配置:embd_id指定嵌入模型、similarity_threshold相似度阈值
- 数据统计:实时维护doc_num/token_num等量化指标
document- 文档表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| thumbnail | TEXT | 缩略图Base64 | |
| kb_id | VARCHAR(256) | ✔ | 知识库ID |
| parser_id | VARCHAR(32) | ✔ | 解析器ID |
| parser_config | JSON | ✔ | 解析配置 |
| source_type | VARCHAR(128) | ✔ | 来源类型 |
| type | VARCHAR(32) | ✔ | 文件类型 |
| created_by | CHAR(32) | ✔ | 创建人 |
| name | VARCHAR(255) | 文件名 | |
| location | VARCHAR(255) | 存储位置 | |
| size | INTEGER | 文件大小 | |
| token_num | INTEGER | Token数 | |
| chunk_num | INTEGER | 分块数 | |
| progress | FLOAT | 处理进度 | |
| progress_msg | TEXT | 进度消息 | |
| process_begin_at | DATETIME | 开始时间 | |
| process_duation | FLOAT | 处理时长 | |
| meta_fields | JSON | 元数据 | |
| run | CHAR(1) | 运行状态 | |
| status | CHAR(1) | 状态 | |
- 作用:存储用户上传的原始文档及处理状态
- 处理流水线:通过parser_id指定解析器,progress字段跟踪处理进度
- 扩展能力:meta_fields支持自定义元数据存储

文件管理模块
file- 文件存储表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| parent_id | CHAR(32) | ✔ | 父目录ID |
| tenant_id | CHAR(32) | ✔ | 租户ID |
| created_by | CHAR(32) | ✔ | 创建人 |
| name | VARCHAR(255) | ✔ | 文件名 |
| location | VARCHAR(255) | 存储位置 | |
| size | INTEGER | 文件大小 | |
| type | VARCHAR(32) | ✔ | 文件类型 |
| source_type | VARCHAR(128) | ✔ | 来源类型 |
- 作用:统一文件管理系统,支持文件夹结构(parent_id)
- 设计特点:与document解耦,通过file2document关联
file2document- 文件-文档关联表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| file_id | CHAR(32) | 文件ID | |
| document_id | CHAR(32) | 文档ID |
- 作用:维护原始文件与文档的映射关系
任务处理模块
task-后台任务表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| doc_id | CHAR(32) | ✔ | 文档ID |
| from_page | INTEGER | 起始页 | |
| to_page | INTEGER | 结束页 | |
| task_type | VARCHAR(32) | ✔ | 任务类型 |
| priority | INTEGER | 优先级 | |
| begin_at | DATETIME | 开始时间 | |
| process_duation | FLOAT | 处理时长 | |
| progress | FLOAT | 进度 | |
| progress_msg | TEXT | 进度消息 | |
| retry_count | INTEGER | 重试次数 | |
| digest | TEXT | 摘要 | |
| chunk_ids | LONGTEXT | 分块ID集合 |
- 作用:异步任务调度系统,处理文档解析等耗时操作
- 监控指标:progress进度、retry_count重试机制
对话系统模块
dialog- 对话应用表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| tenant_id | CHAR(32) | ✔ | 租户ID |
| name | VARCHAR(255) | 对话名称 | |
| description | TEXT | 描述 | |
| icon | TEXT | 图标Base64 | |
| language | VARCHAR(32) | 语言 | |
| llm_id | VARCHAR(128) | ✔ | LLM ID |
| llm_setting | JSON | ✔ | LLM参数 |
| prompt_type | VARCHAR(16) | ✔ | 提示类型 |
| prompt_config | JSON | ✔ | 提示配置 |
| similarity_threshold | FLOAT | 相似度阈值 | |
| vector_similarity_weight | FLOAT | 向量权重 | |
| top_n | INTEGER | 返回数量 | |
| top_k | INTEGER | 检索数量 | |
| do_refer | CHAR(1) | ✔ | 引用开关 |
| rerank_id | VARCHAR(128) | ✔ | 重排序模型 |
| kb_ids | JSON | ✔ | 知识库集合 |
| status | CHAR(1) | 状态 |
- 作用:定义可发布的对话机器人配置
- 核心配置:llm_setting参数模板、prompt_config提示工程
- 知识集成:通过kb_ids绑定多个知识库
conversation- 会话记录表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| dialog_id | CHAR(32) | ✔ | 对话ID |
| name | VARCHAR(255) | 会话名称 | |
| message | JSON | 消息内容 | |
| reference | JSON | 引用内容 | |
| user_id | VARCHAR(255) | 用户ID |
- 作用:存储用户对话历史上下文
- 数据结构:message以JSON保存完整对话树,reference记录引用来源
这块还没有实现
api_token-API凭证表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| tenant_id | CHAR(32) | ✔ | 租户ID |
| token | VARCHAR(255) | ✔ | API令牌 |
| dialog_id | CHAR(32) | 对话ID | |
| source | VARCHAR(16) | 来源 | |
| beta | VARCHAR(255) | 测试标记 | |
- 作用:管理第三方接入的认证令牌
- 安全控制:复合主键确保租户下token唯一性
api_4_conversation- API会话日志
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| dialog_id | CHAR(32) | ✔ | 对话ID |
| user_id | VARCHAR(255) | ✔ | 用户ID |
| message | JSON | 消息内容 | |
| reference | JSON | 引用内容 | |
| tokens | INTEGER | Token消耗 | |
| source | VARCHAR(16) | 来源 | |
| dsl | JSON | DSL脚本 | |
| duration | FLOAT | 持续时间 | |
| round | INTEGER | 对话轮次 | |
| thumb_up | INTEGER | 点赞数 |
- 作用:记录通过API发起的对话完整轨迹
- 分析指标:tokens消耗统计、duration响应时长
画布模块
user_canvas- 用户画布表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| avatar | TEXT | 头像Base64 | |
| user_id | VARCHAR(255) | ✔ | 用户ID |
| title | VARCHAR(255) | 画布标题 | |
| permission | VARCHAR(16) | ✔ | 权限范围 |
| description | TEXT | 描述 | |
| canvas_type | VARCHAR(32) | 画布类型 | |
| dsl | JSON | DSL配置 |
- 作用:保存用户创建的AI工作流配置
- 核心能力:dsl字段存储可视化编排逻辑,permission控制协作权限
canvas_template- 画布模板表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| avatar | TEXT | 头像Base64 | |
| title | VARCHAR(255) | 模板标题 | |
| description | TEXT | 描述 | |
| canvas_type | VARCHAR(32) | 画布类型 | |
| dsl | JSON | DSL配置 |
- 作用:提供预置的可复用工作流模板
user_canvas_version -画布版本表
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
| id | CHAR(32) | ✔ | 主键 |
| user_canvas_id | VARCHAR(255) | ✔ | 画布ID |
| title | VARCHAR(255) | 版本标题 | |
| description | TEXT | 描述 | |
| dsl | JSON | DSL配置 |
- 作用:实现画布修改历史追踪
- 版本管理:每次修改生成新版本记录,支持回滚
ER模型关系
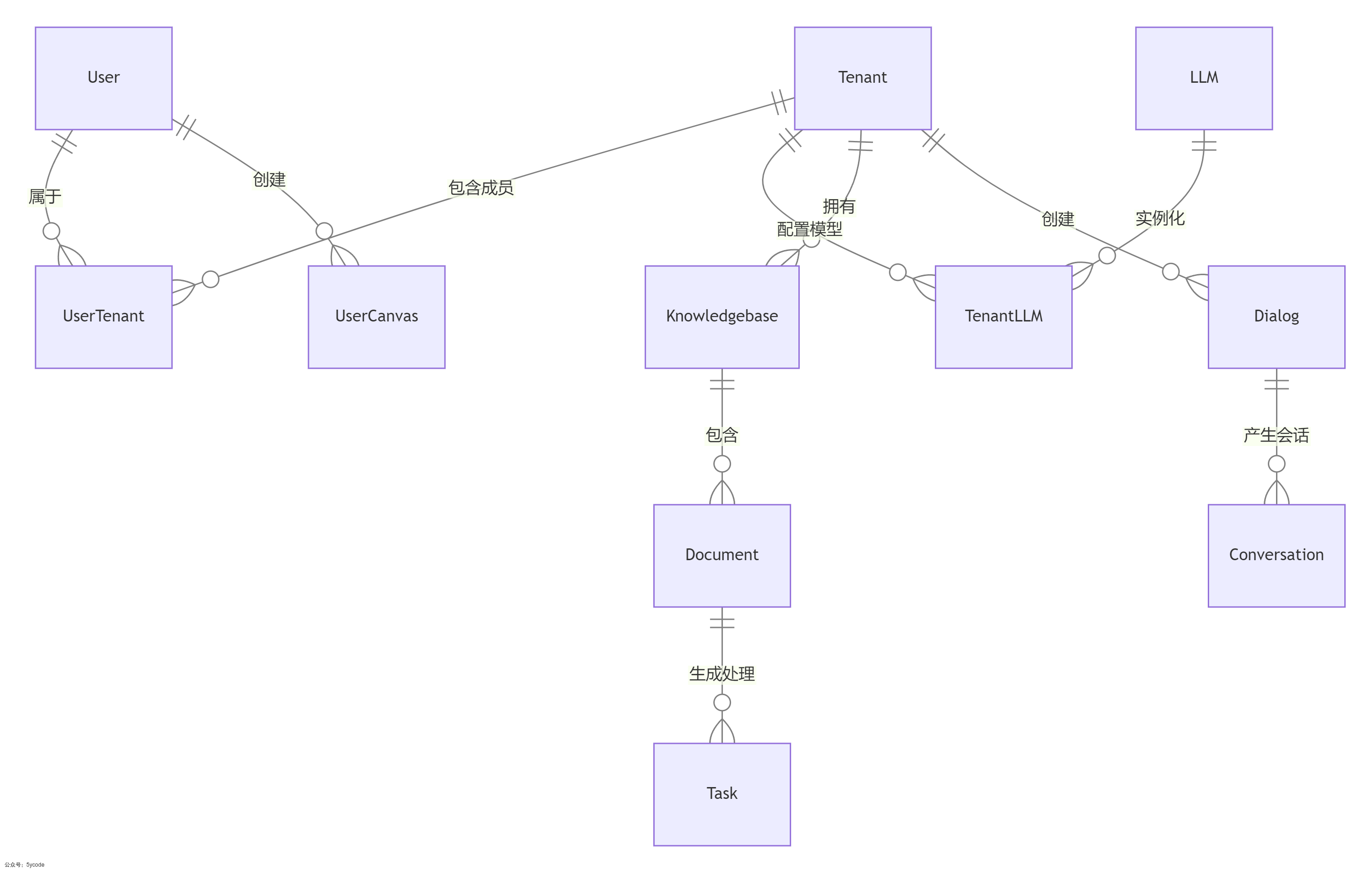
- 我们通过ER模型可以看到Ragflow以租户为核心
- 围绕租户有模型、知识库、和用户
后记
通过ragflow的表结构我们可以看到ragflow的一些后续的规划,有些功能还没有实现。
相关资料
deepseek相关资料
https://pan.quark.cn/s/faa9d30fc2bd
https://pan.baidu.com/s/10vnv9jJJCG-KKY8f_e-wLw?pwd=jxxv
群友分享的一些dify工作流
https://pan.baidu.com/s/1aNne8dLz6YxoKhCwJclV5g?pwd=p4xc
https://pan.quark.cn/s/243a0de062e5
系列文档:
DeepSeek本地部署相关
DeepSeek个人应用
不要浪费deepseek的算力了,DeepSeek提示词库指南
服务器繁忙,电脑配置太低,别急deepseek满血版来了
DeepSeek+本地知识库:真的太香了(修订版)
DeepSeek+本地知识库:真是太香了(企业方案)
deepseek一键生成小红书爆款内容,排版下载全自动!睡后收入不是梦
最轻量级的deepseek应用,支持联网和知识库
当我把公众号作为知识库塞进了智能体后
个人神级知识库DeepSeek+ima 个人学习神器
dify相关
DeepSeek+dify 本地知识库:真的太香了
Deepseek+Dify本地知识库相关问题汇总
dify的sandbox机制,安全隔离限制
DeepSeek+dify 本地知识库:高级应用Agent+工作流
DeepSeek+dify知识库,查询数据库的两种方式(api+直连)
DeepSeek+dify 工作流应用,自然语言查询数据库信息并展示
聊聊dify权限验证的三种方案及实现
dify1.0.0版本升级及新功能预览
Dify 1.1.0史诗级更新!新增"灵魂功能"元数据,实测竟藏致命Bug?手把手教你避坑
【避坑血泪史】80次调试!我用Dify爬虫搭建个人知识库全记录
ragflow相关
DeepSeek+ragflow构建企业知识库:突然觉的dify不香了(1)
DeepSeek+ragflow构建企业知识库之工作流,突然觉的dify又香了
DeepSeek+ragflow构建企业知识库:高级应用篇,越折腾越觉得ragflow好玩
RAGFlow爬虫组件使用及ragflow vs dify 组件设计对比
从8550秒到608秒!RAGFlow最新版本让知识图谱生成效率狂飙,终于不用通宵等结果了
以为发现的ragflow的宝藏接口,其实是一个天坑、Chrome/Selenium版本地狱
NLTK三重降噪内幕!RAGFlow检索强悍竟是靠这三板斧
扣子(coze)
AI开发新选择:扣子平台功能详解与智能体拆解
AI开发新选择:扣子平台工作流基础节点介绍
模型微调相关
📢【三连好运 福利拉满】📢
🌟 若本日推送有收获:
👍 点赞 → 小手一抖,bug没有
📌 在看 → 一点扩散,知识璀璨
📥 收藏 → 代码永驻,防止迷路
📤 分享 → 传递战友,功德+999
🔔 关注 → 关注5ycode,追更不迷路,干货永同步
💬 若有槽点想输出:
👉 评论区已铺好红毯,等你来战!


















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









