









昨天刚吃过饭,看到dify推送1.1.0的升级,我看了下升级日志。
在Dify1.1.0版本中修复了37个bug,新增了13个功能。官方推介的最重要的功能是元数据
元数据是什么?
元数据(Metadata)是“关于数据的数据”,用于描述其他数据的属性、来源、结构、用途等信息。简而言之,它是数据的标签,帮助人们理解和管理数据本身。
例如,在文档管理系统中,元数据可能包括文档名称、作者、创建日期等。通过这些结构化信息,系统能够基于特定条件进行筛选,从而更准确地检索到相关内容。
元数据流程图
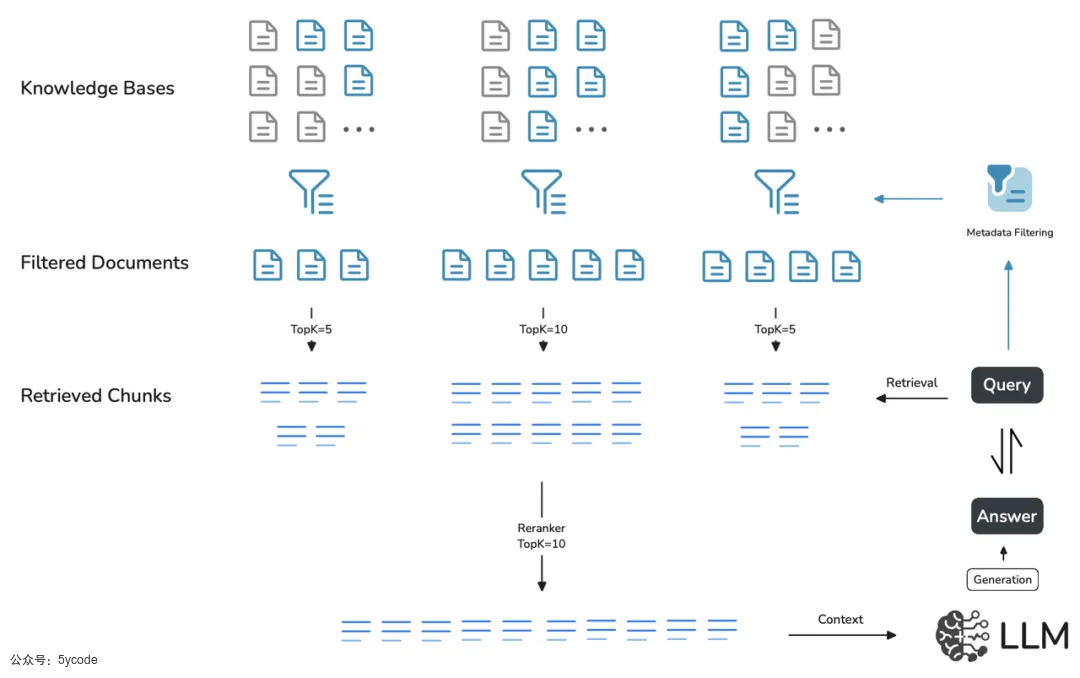
根据描述和流程图示意,我们可以看到。
- 元数据的使用场景是一个知识库下,有多个文档的时候,或者多个知识库下的n个文档
- 可以给文档设置一些关键词,在检索的时候,根据关键词先匹配到对应的文档,然后再在对应的文档里去检索。
- 这些关键词,可以是文件的分类,也可以是文件的隐私级别,自由组织
升级
所有升级先备份数据和 配置文件,以防升级出现问题后用于回滚。我这个是测试演示环境,直接操作了。
因为大部分同学都是docker部署,不是用的源码部署。只需要修改docker/docker-compose.yaml文件中的引用版本即可。
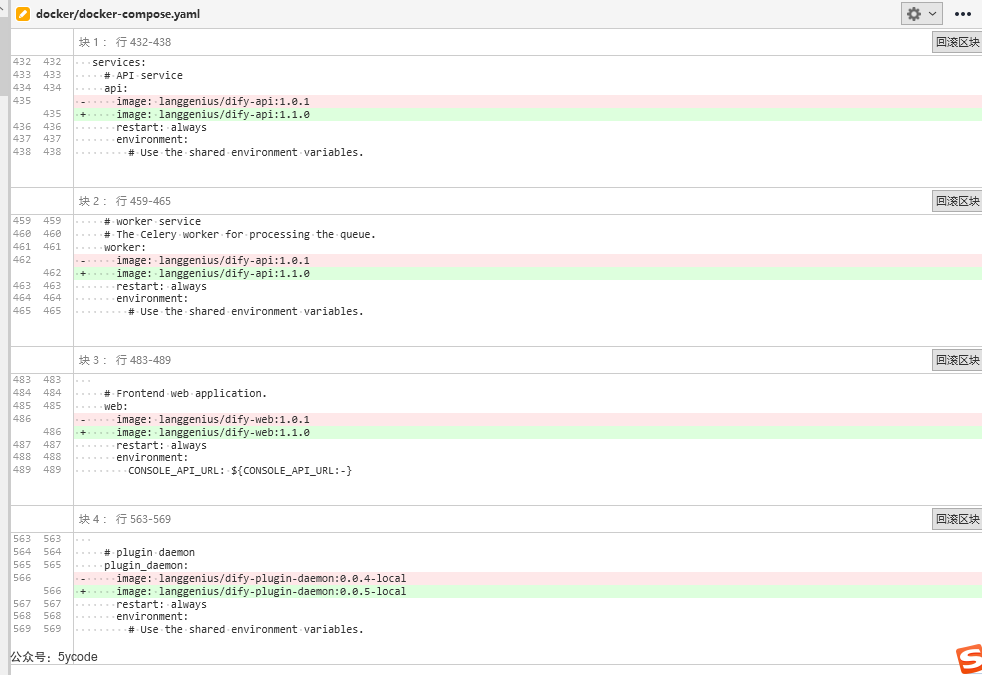
将图中的版本改成对应的位置改成新版本即可。改完以后执行
docker-compose down
docker-compose up -d
模型供应商
在1.1.0中模型的供应商还是从github上拉取。期望官方后续做个国内可以访问的镜像。

本地想要访问,可以把对应的json拿到,然后在本地做一个代理映射。可以解决一部分问题。
元数据的使用
需求
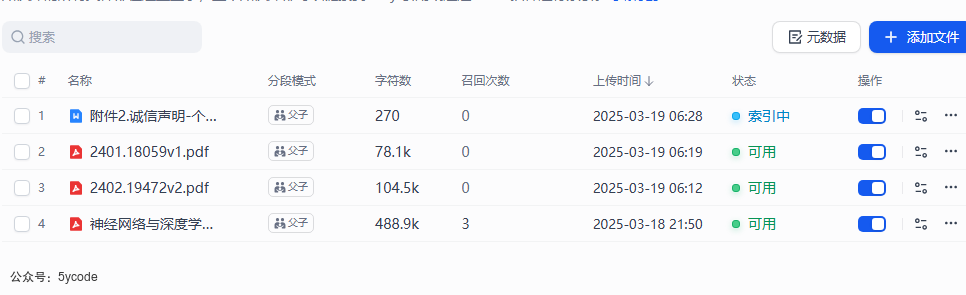
在我的知识库中,有4个文件,有两个文件是论文,一个文件是书籍,一个是比较隐私的文件。我的需求如下:
- 有时候检索的时候,我只想从论文中检索,或者从书籍中检索
- 我的隐私文件只有在特定条件下才能查看
元数据的设置
在知识库的右上角位置
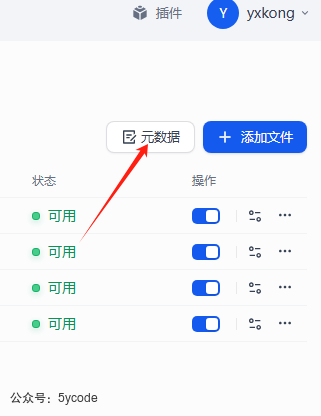
在知识库的右上角有个元数据按钮。点击。
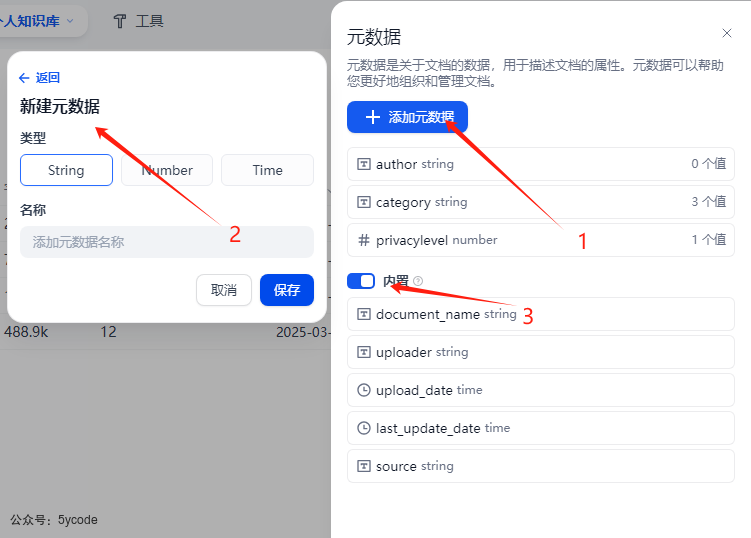
- 通过
1添加元数据 - 新建元数据有三种类型,字符串、数值和时间,大家根据自己的需要建立
- 建议把
3内置的元数据开启
元数据标注
元数据的标注有两种,批量标注和单个标注
批量标注
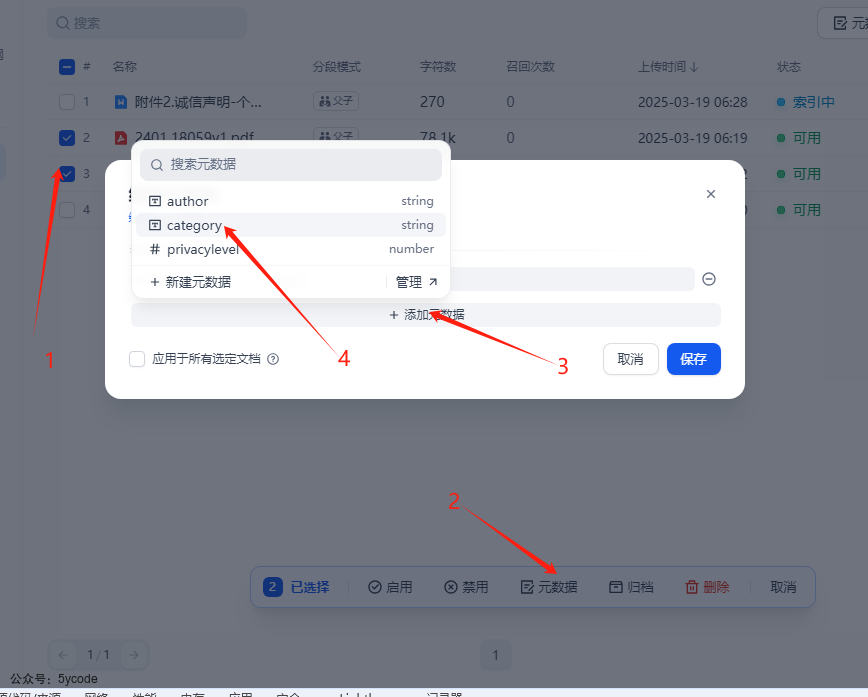
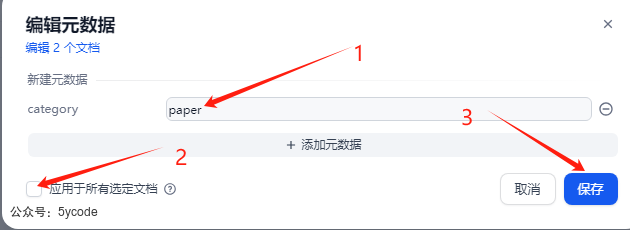
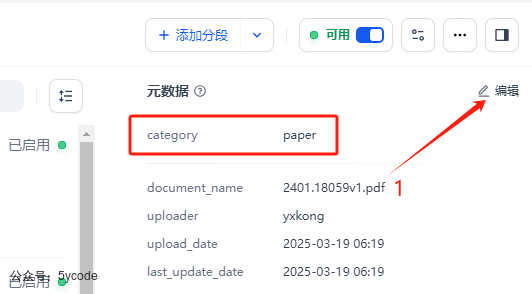
在知识库的文件列表里,我们通过1勾选多个文档,点2位置的元数据,会弹出元数据的设置框,然后点击3添加元数据,通过4选择元数据的标签。
单个标注
我们点击一个知识文档进去
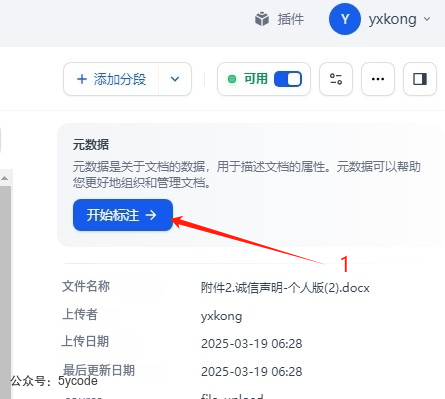
点击右上角的开始标注按钮进行元数据的标注。
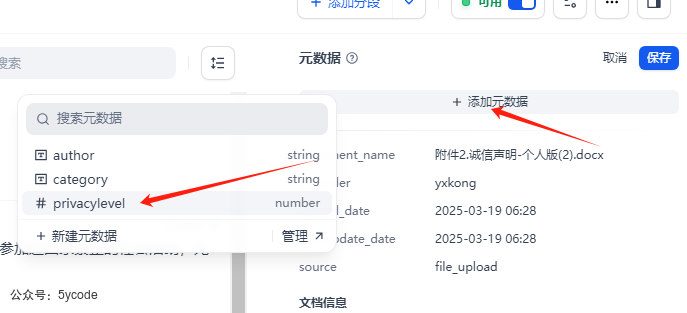
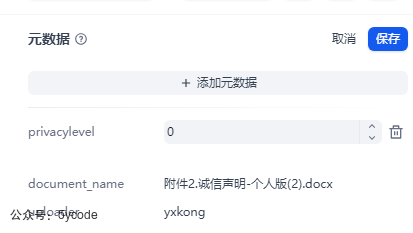
元数据的使用
聊天助手中使用
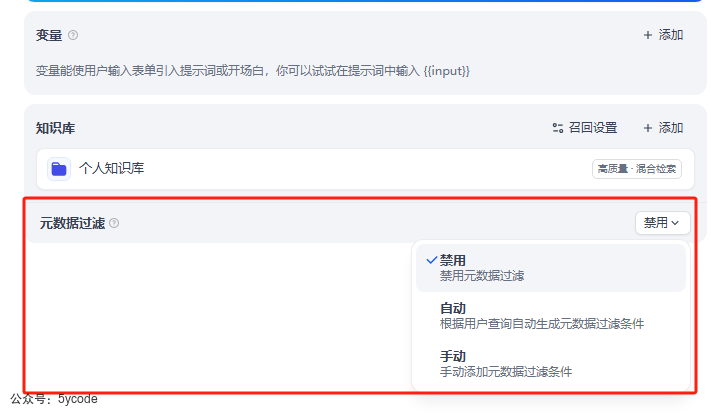
在工作室的聊天助手应用中。添加应用知识库以后,我们可以看到新版本多了一个元数据过滤功能。在聊天助手中,我们选择手动的方式进行元数据过滤。
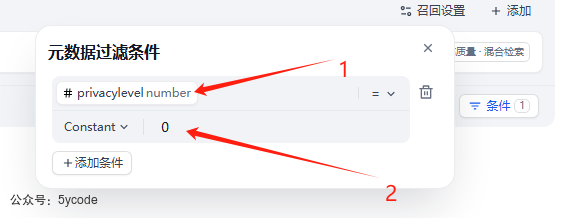
在聊天助手中我们通过常量值来进行限定。
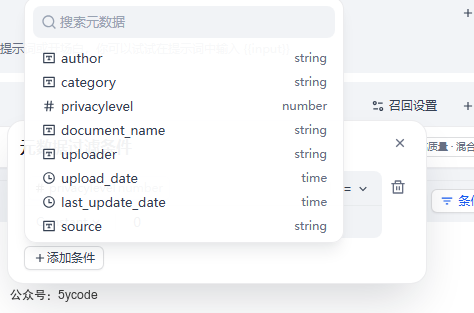
过滤条件可以是自定义,也可以是内置的(需手动开启)。
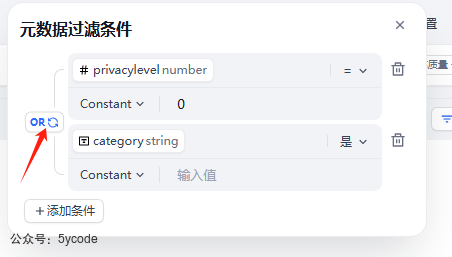
元数据的关系,可以是逻辑与也可以是逻辑或。
在以前的应用中我们可能为了在不同的应用中使用不同隐私级别的知识文档,我们需要建立多个知识库,现在只要建立一个,给文件打上元数据标签即可。
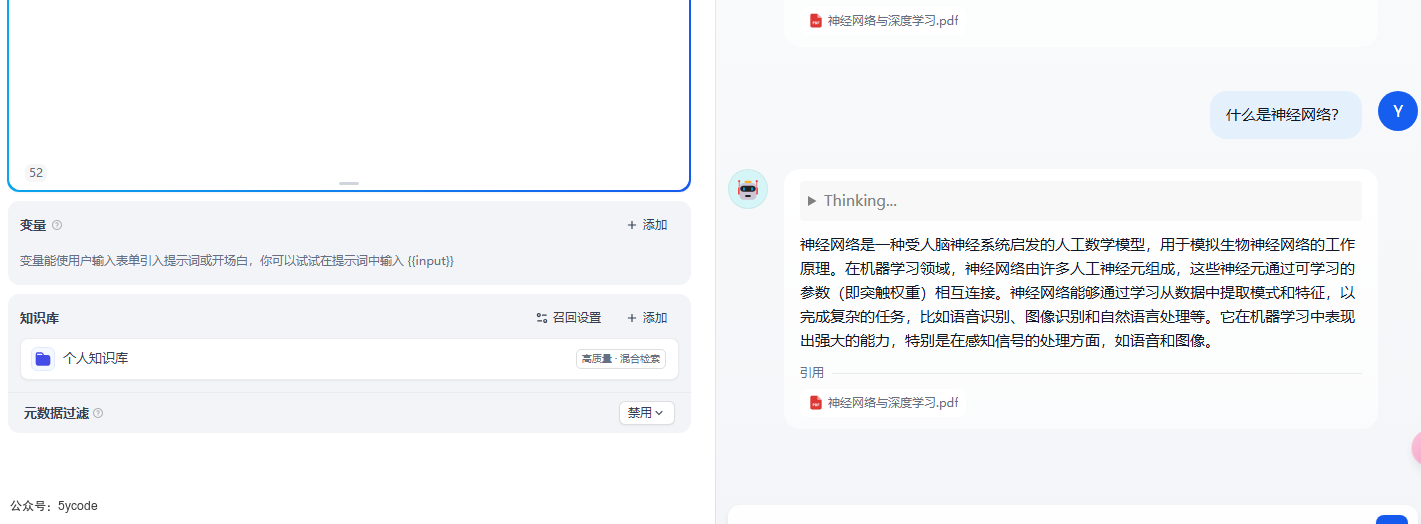
禁用的情况,可以从所有的文档里检索知识。
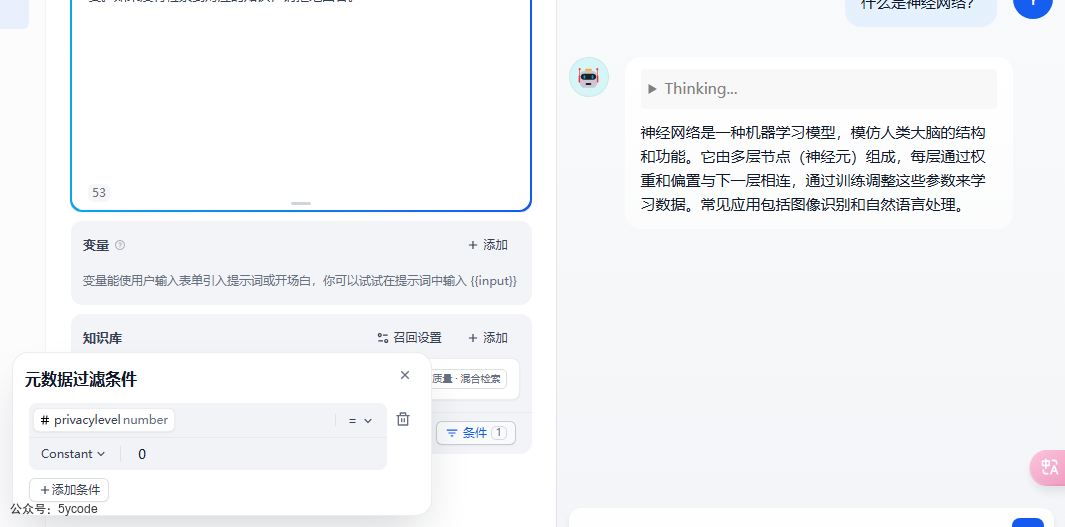
当我开启元数据过滤,并指定隐私级别为0的时候,已经没有再检索到内容了。
工作流中使用
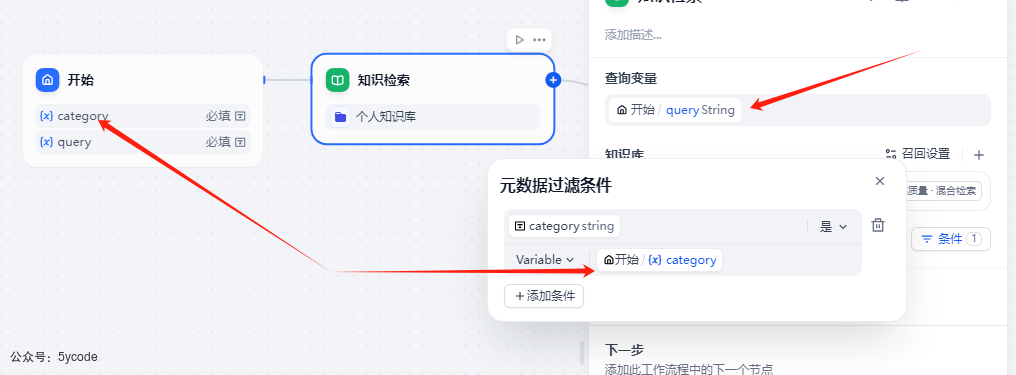
在工作流中,我们可以定义一个变量,作为检索分类条件,进行检索。
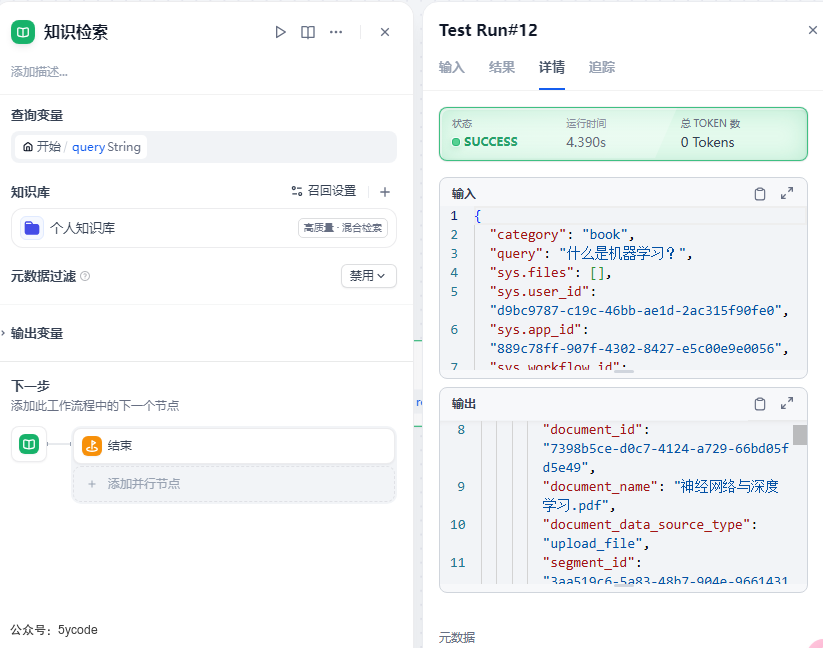
在不设置元数据过滤的时候,我们能查找到。
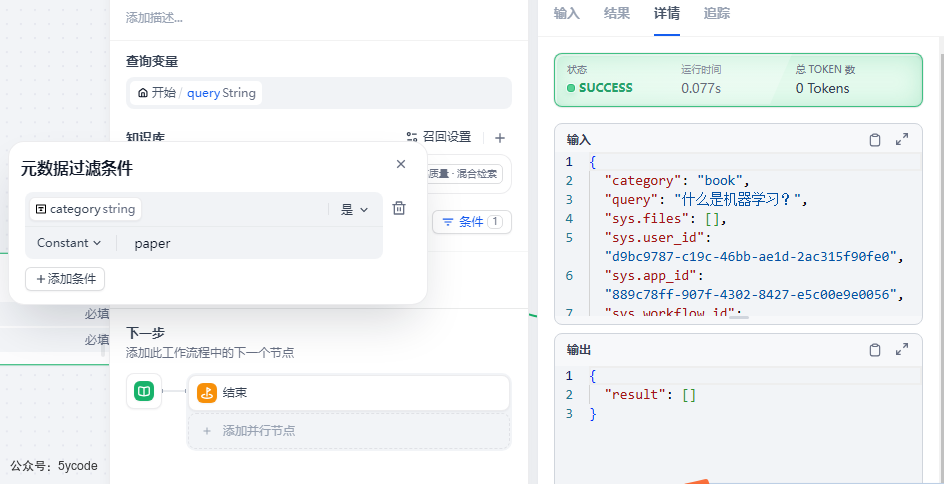
通过手动,指定分类常量为paper查找不到了。
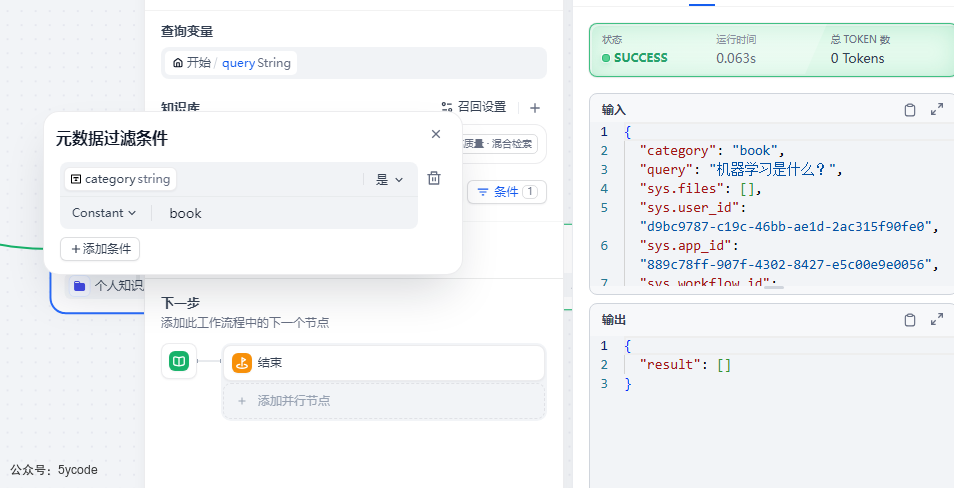
然后指定book,还是没找到?what?有bug?
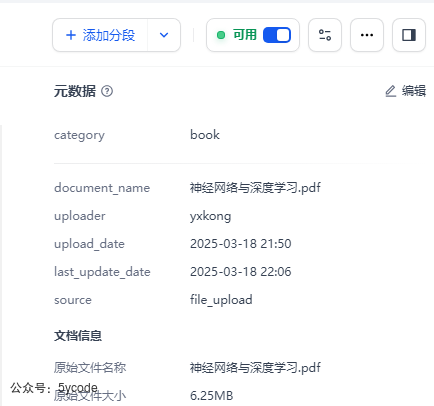
看了下元数据,没有问题。
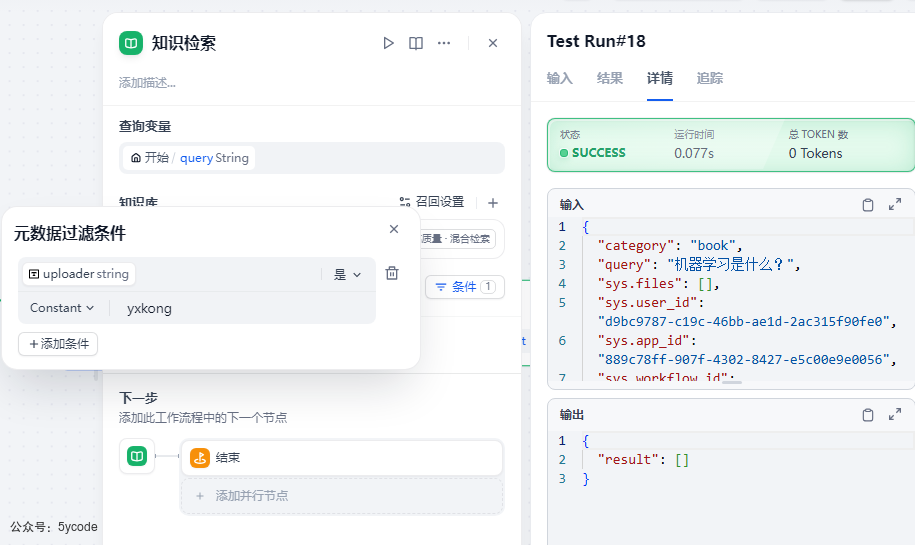 改成内置的分类,还是查找不到。bug。。。。
改成内置的分类,还是查找不到。bug。。。。
bug汇总
- 元数据查询,在工作流中的知识库中不生效
- 更新以后模型失效,有的好,有的不行,
- 有人反馈通义和openai的有的加载不了
- 无法添加ollama的embeding模型
- 网页卡顿,加载很慢(可能是没有梯子)
插件离线安装
插件离线安装
访问dify插件市场
https://marketplace.dify.ai/
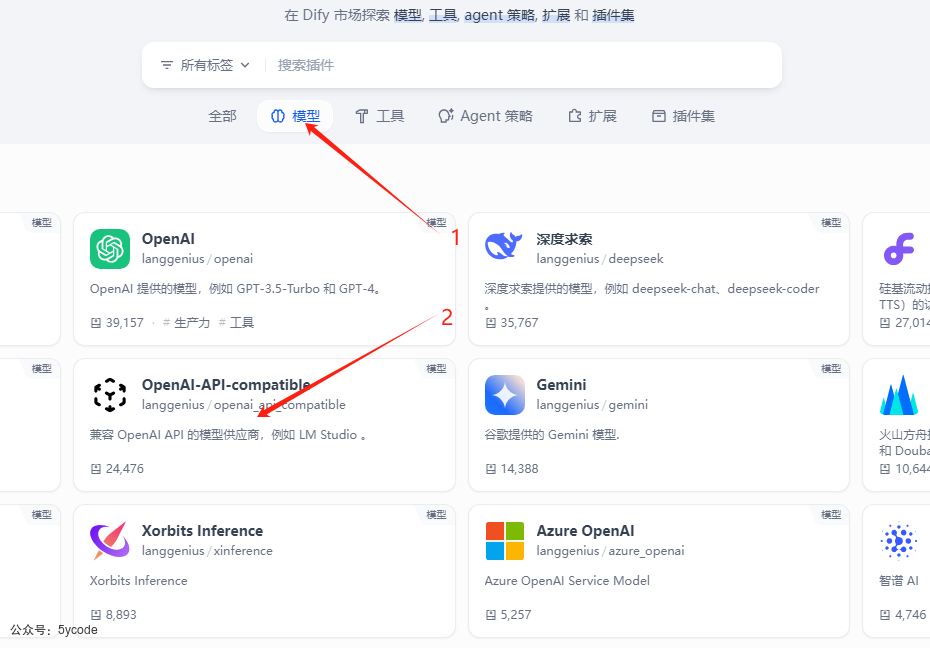
根据导航1对应的分类,找到对应的插件,点击
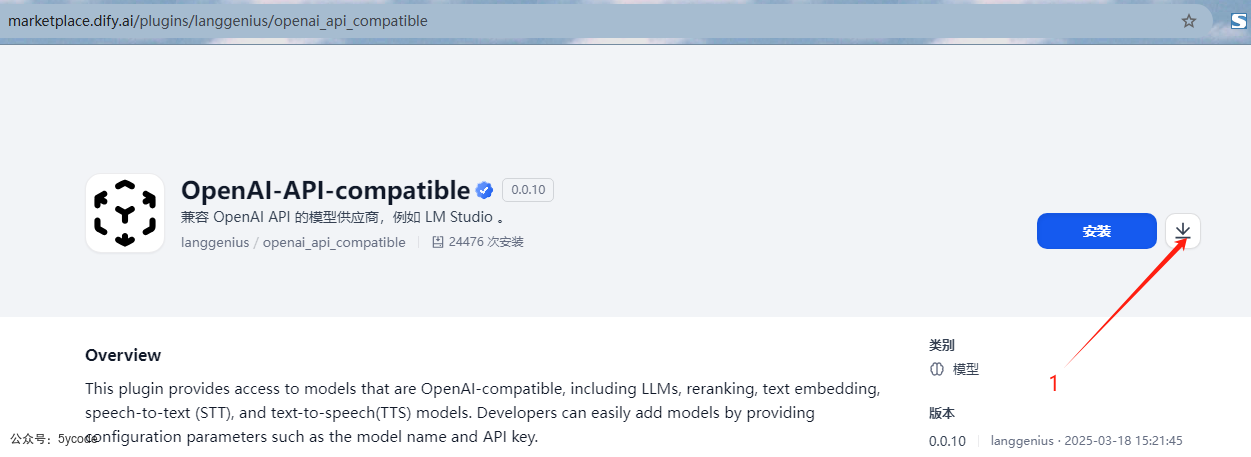
点击如图所示的下载。
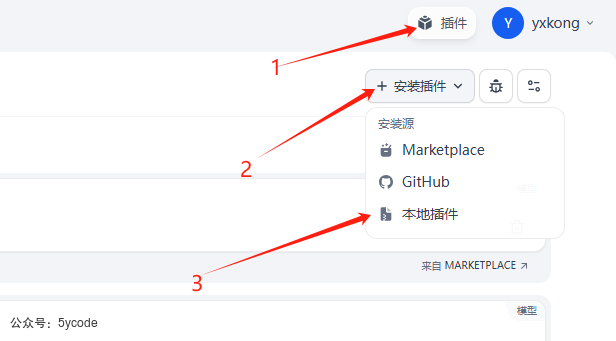
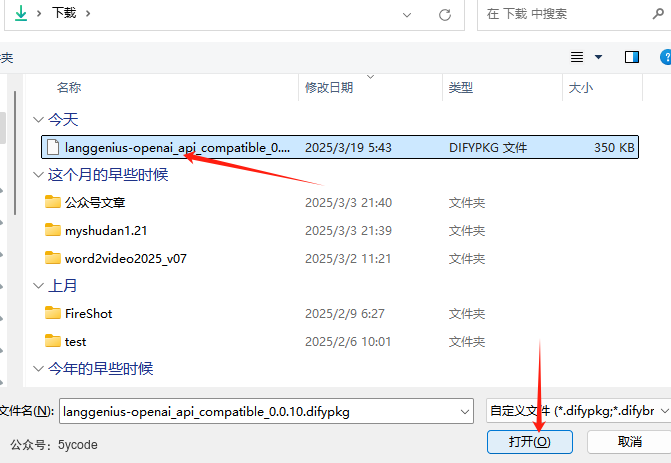
然后得等一会,插件的安装比较慢,一般30秒左右吧。
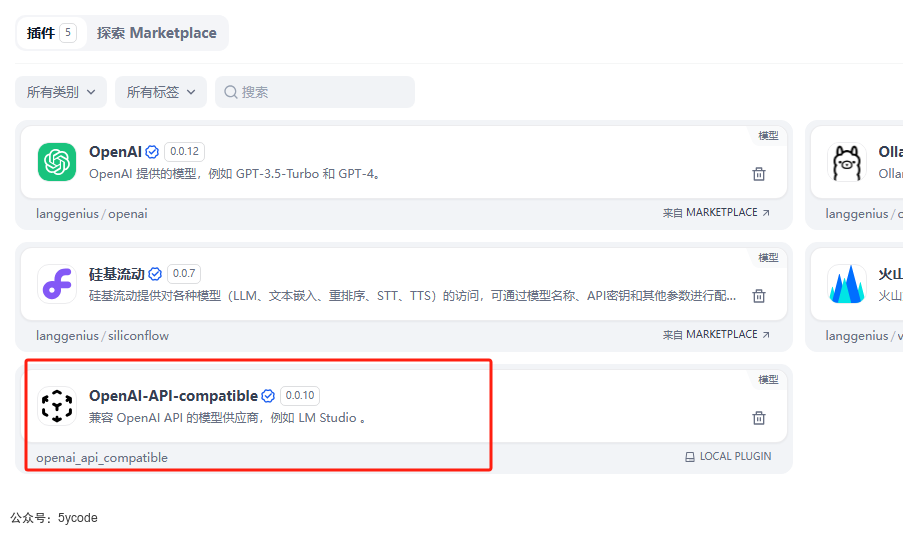
后记
整体测试过程中,在聊天框内,没有问题,在工作流中无论怎么测试,都没有生效。又要疯狂更新了。

其实在ragflow中也有,不过ragflow的元数据显示不可搜索,dify都出了,ragflow还会远吗?估计这个是某个企业定制的功能。
相关资料
deepseek相关资料,包含内容如下
https://pan.quark.cn/s/faa9d30fc2bd
https://pan.baidu.com/s/10vnv9jJJCG-KKY8f_e-wLw?pwd=jxxv
系列文档:
DeepSeek本地部署相关
DeepSeek个人应用
不要浪费deepseek的算力了,DeepSeek提示词库指南
deepseek一键生成小红书爆款内容,排版下载全自动!睡后收入不是梦
dify相关
DeepSeek+dify 本地知识库:高级应用Agent+工作流
DeepSeek+dify知识库,查询数据库的两种方式(api+直连)
DeepSeek+dify 工作流应用,自然语言查询数据库信息并展示
ragflow相关
DeepSeek+ragflow构建企业知识库:突然觉的dify不香了(1)
DeepSeek+ragflow构建企业知识库之工作流,突然觉的dify又香了
DeepSeek+ragflow构建企业知识库:高级应用篇,越折腾越觉得ragflow好玩
RAGFlow爬虫组件使用及ragflow vs dify 组件设计对比
从8550秒到608秒!RAGFlow最新版本让知识图谱生成效率狂飙,终于不用通宵等结果了
模型微调相关
📢【三连好运 福利拉满】📢
🌟 若本日推送有收获:
👍 点赞 → 小手一抖,bug没有
📌 在看 → 一点扩散,知识璀璨
📥 收藏 → 代码永驻,防止迷路
📤 分享 → 传递战友,功德+999
🔔 关注 → 关注5ycode,追更不迷路,干货永同步
💬 若有槽点想输出:
👉 评论区已铺好红毯,等你来战!


















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









