



 本文介绍了Spark中RDD的创建方法,包括从集合创建、加载文件以及通过转换形成新的RDD。详细讨论了RDD的转换算子,如map、filter和mapValues,并阐述了RDD的动作算子,强调了动作算子在RDD计算中的角色。此外,文章还深入探讨了RDD的依赖关系,特别是窄依赖和宽依赖的概念,以及它们在容错和计算效率上的差异。
本文介绍了Spark中RDD的创建方法,包括从集合创建、加载文件以及通过转换形成新的RDD。详细讨论了RDD的转换算子,如map、filter和mapValues,并阐述了RDD的动作算子,强调了动作算子在RDD计算中的角色。此外,文章还深入探讨了RDD的依赖关系,特别是窄依赖和宽依赖的概念,以及它们在容错和计算效率上的差异。
有3种方式可以创建RDD。分别如下介绍:
1、由集合创建RDD
Spark会将集合中的数据拷贝到集群上去,形成一个分布式的数据集合,也就是一个RDD;相当于集合中的一部分数据会到一个节点上,而另一部分数据会到其他节点上;然后就可以用并行的方式来操作这个分布式数据集合。
val rdd = sc.parallelize(List(1,2,3,4,5,6)
rdd.count
val rdd = sc.parallelize(List(1,2,3,4,5,6),3)
rdd.count上面两种写法结果是一样的,只是分区数不一样。通过WebUI可以发现它们的任务数量不一样。从RDD的特性来看,有多少个分区就有多少个任务,它们之间是一 一对应的。
2、加载文件成RDD
通过调用SparkContext的textFile()方法,可以读取本地文件或HDFS文件创建RDD,文件中的每一行就是RDD中的一个元素。
# 准备处理的数据:hello.txt
hello world hello
hello welcome world
#Spark处理本地文件
val distFile = sc.textFile("file:///root/hello.txt")
#Spark处理HDFS上的文件
cd ~/data
hadoop fs -put hello.txt / #上传本地文件到HDFS
val disFile = sc.textFile("hdfs://192.168.48.141:8020/hello.txt")
disFile.count
注意事项:
(1)如果是在本地测试本地文件,有一份文件即可;如果是在Spark集群上测试本地文件,需要将文件拷贝到所有Worker Node上。因为Spark是分布式执行的,任务会被分配到不同的节点上去执行。
(2)Spark的textFile()方法支持针对目录、压缩文件以及通配符进行RDD创建。
————————————————
textFile("/my/directory")
textFile("/my/directory/*.txt")(3)Spark默认会为HDFS文件的每一个数据块创建一个分区,但是也可以通过textFile()的第二个参数手动设置分区数量,只能比数据块数量多,不能比数据块数量少。
3、通过RDD的转换形成新的RDD
具体如下面(RDD的转换算子)的描述。
RDD的转换算子
1、RDD转换概述
RDD中的所有转换都不会直接计算结果。相反地,它们只是记录了作用于RDD上的操作。只有在遇到一个动作(Action)时才会进行计算。如图:
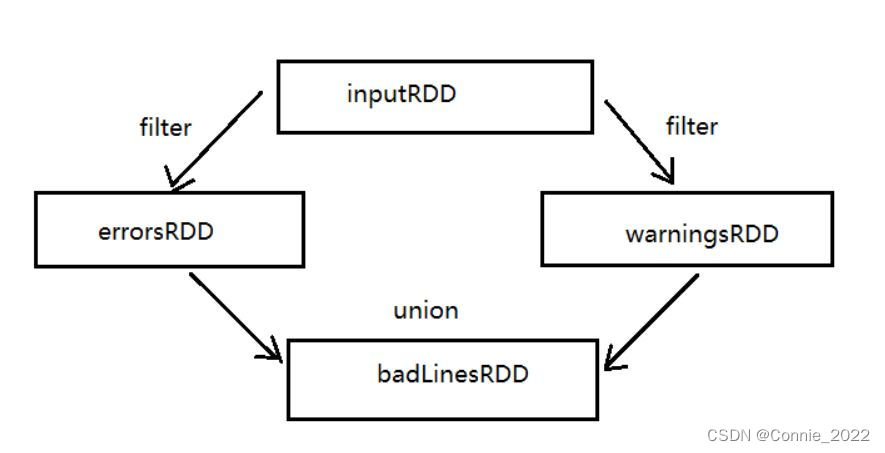
2、常用的RDD转换算子
如表所示:
| 算子 | 描述 | |
| map(func) | 对调用map的RDD数据集中的每个元素都使用func,然后返回一个新的RDD,这个返回的数据集是分布式的数据集 | |
| filter(func) | 对调用filter的RDD数据集中的每个元素都使用func,然后返回一个包含使func为true的元素构成的RDD | |
| flatMap(func) | 和map差不多,但是flatMap生成的是多个结果 | |
| mapPartitions(func) | 和map很像,但是map是针对每个元素,而这个是针对每个分区 | |
| 抽样 | |
| union(otherDataset) | 返回一个新的数据集,包含源数据集和给定数据集的元素的集合 | |
| distinct([numTasks]) | 返回一个新的数据集,这个数据集含有的是源数据集中不重复的元素 | |
| groupByKey(numTasks) | 返回(K,Seq[V]),也就是Hadoop中reduce函数接收的key-value的列表 | |
| reduceByKey(func,[numTasks]) | 用一个给定的reduce函数再作用于groupByKey产生的(K,Seq[V]),比如求和、求平均数 | |
| sortByKey([ascending],[numTasks]) | 按照key来排序,ascending是boolean类型,指定是升序或降序 | |
| join(otherDataset,[numTasks]) | 当有两个KV对的数据集(K,V)和(K,W),返回的是(K,(V,W))的数据集,numTasks为并发的任务数 | |
| cogroup(otherDataset,[numTasks]) | 当有两个KV对的数据集(K,V)和(K,W),返回的是(K,Seq[V],Seq[W])的数据集,numTasks为并发的任务数 | |
| cartesian(otherDataset) | 笛卡尔积就是m*n |
(1)map算子
# 把原RDD中每个元素都乘以2 来产生一个新的RDD
val a = sc.parallelize(1 to 9)
val b = a.map(x=>x*2)
a.collect
b.collect
# map也可以把Key变成Key-Value对
val a = sc.parallelize(List("aa","bb","cc"))
val b = a.map(x=>(x,1))
b.collect
(2)filter算子
val a = sc.parallelize(1 to 10)
a.filter(_%2==0).collect
a.filter(_<4).collect
# map综合filter编程:链式编程的使用
val rdd = sc.parallelize(List(1,2,3,4,5))
val mapRdd = rdd.map(2*_)
mapRdd.collect
val filterRdd = mapRdd.filter(_>5)
filterRdd.collect
(3)mapValues算子
原RDD中的Key保持不变,与新的Value一起组成新的RDD中的元素。因此,该算子只适用于元素为键值对的RDD。
val a = sc.parallelize(List("aa","bb","cc"))
val b = a.map(x=>(x.length,x))
b.mapValues("x"+_+"x").collectRDD的动作算子
1、RDD动作概述
本质上是在动作算子中通过SparkContext执行提交作业的runJob操作,触发了RDD DAG的执行。
2、常用的RDD动作算子
RDD中所有动作都是急迫型的,也就是遇到动作(Action)就是立刻计算。常用动作算子如下表:
| 算子 | 描述 |
| reduce(func) | 聚集,传入的函数是两个参数输入返回一个值,这个函数必须是满足交换律和结合律的 |
| collect() | 一般在过滤或者处理足够小的结果的时候,再用collect封装返回一个数组 |
| count() | 返回的是数据集中的元素的个数 |
| first() | 返回的是数据集的第一个元素 |
| take(n) | 返回前n个元素 |
| countByKey() | 返回的是key对应的个数的一个map,作用于一个RDD |
| foreach(func) | 对数据集中的每个元素都使用func |
| taskSample(withReplacement,num,seed) | 抽样返回一个数据集中的num个元素,seed是随机种子 |
| saveAsTextFile(path) | 把数据集写到一个文本文件、HDFS,或者HDFS支持的文件系统中。Spark把每条记录都转换为一行记录,然后写到文件中 |
| saveAsSequenceFile(path) | 只能用在key-value对上,然后生成SequenceFile写到本地或者Hadoop文件系统中 |
# collect
val a = sc.parallelize(1 to 9,3)
val b = a.map(x=>x*2)
a.collect
# count
val a = sc.parallelize(List("aa","bb","cc"))
a.count
# reduce
val a = sc.parallelize(1 to 100)
a.reduce((x,y)=>x+y))
a.reduce(_+_) //5050
val b = sc.parallelize(Array(("A",0),("A",2),("B",1),("B",2),("C",1)))
b.reduce((x,y)=>{(x._1+y._1,x._2+y._2)}) //(AABBC,6)
# first
val a = sc.parallelize(List("aa","bb","cc"))
a.firest //aa
# take
sc.parallelize(List("aa","bb","cc")).take(2) //Array(aa,bb)
sc.parallelize(1 to 10).take(3) //Array(1,2,3)
# lookup
# 用于(K,V)类型的RDD,指定K值,返回RDD中该K对应的所有V值。
val rdd = sc.parallelize(List(('a',1),('a',2),('b',3),('b',4)))
rdd.lookup('a') //WrappedArray(1,2)
# 最值(max,min)
val y = sc.parallelize(10 to 30)
y.max //30
y.min //10
# 保存RDD数据到文件系统
val rdd = sc.parallelize(1 to 10,2)
rdd.saveAsTextFile("hdfs://192.168.48.141:8020/data/rddsave/")
RDD的依赖关系
1、遗传
RDD最重要的特性之一就是遗传。
遗传信息一直增长,直到遇到动作,才会把前面累积的所有转换一次性执行。每个RDD是知道自己是从哪个父RDD演化而来的,这是Spark容错的核心。如果某个RDD丢失了,则可以通过遗传信息从父RDD快速并行计算得出。
2、依赖
在Spark中,每一个RDD是数据集在某一状态下的表现形式,比如说:map、filter、group by等都算一次操作,这个状态有可能是从前一状态转换而来的。因此换句话说,一个RDD可能与之前的很多RDD有依赖关系。
根据依赖关系不同,可以分为:宽依赖和窄依赖。
如下图(RDD依赖关系图):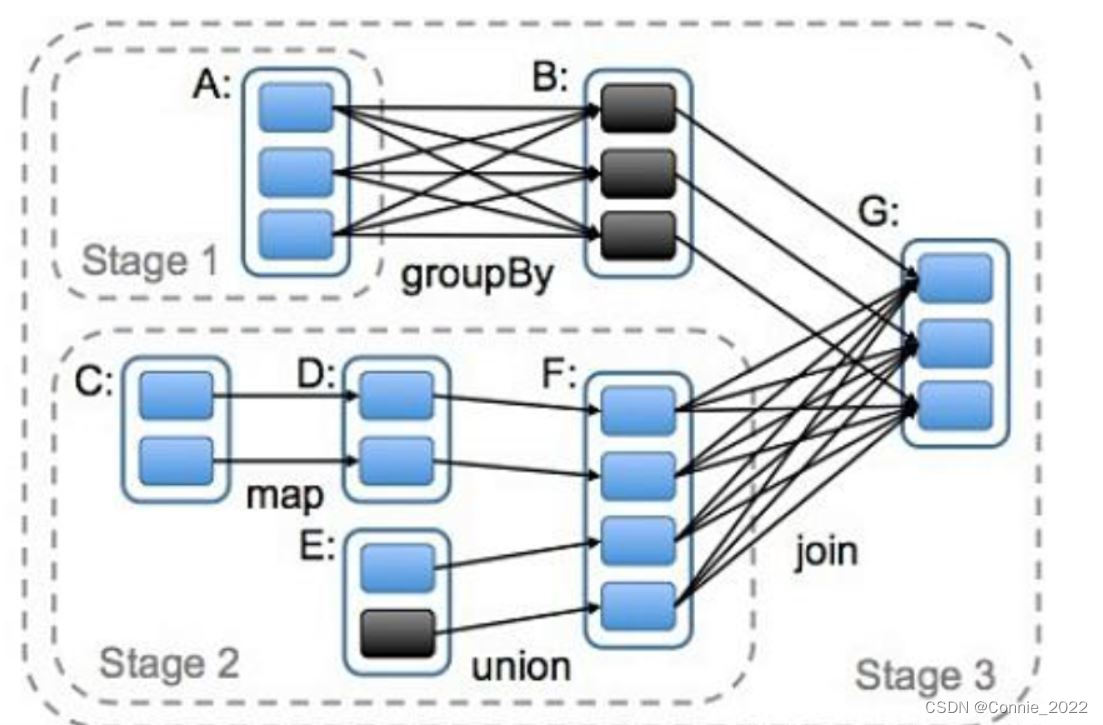
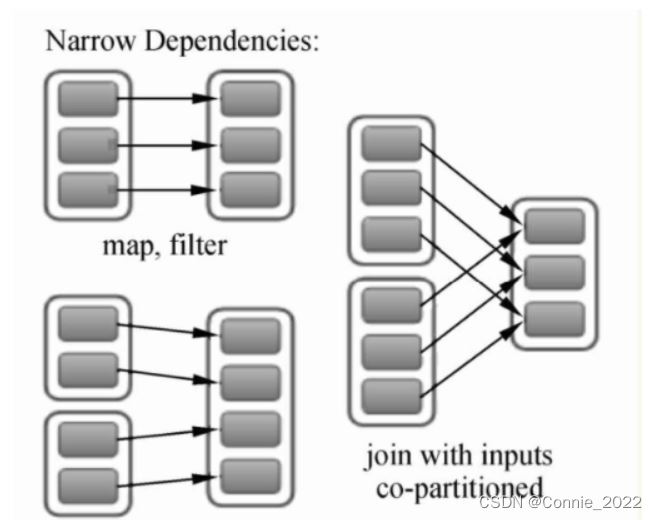
3、窄依赖
定义:一个父RDD的分区至多被子RDD的某个分区使用一次,如下图。
容错:某个分区出故障了,可以快速将丢失的分区并行计算出来。窄依赖可以在单节点上完成运算,非常高效。容错和计算速度都比宽依赖好。
4、宽依赖
定义:一ge父RDD的分区会被子RDD的分区使用多次。即只能前面的算好后才能进行后续的计算,只有等到父分区的所有数据都传输到各个节点后才能计算(经典的MapReduce场景),如下图。
容错:某个分区出故障了,要计算前面所有的父分区,代价会很大。Spark可以把宽依赖的结果集通过StorageLevel设置将数据持久化寸到磁盘、内存或者内存和磁盘中,但分区出故障后直接从持久化(磁盘或者内存)存储中读取即可。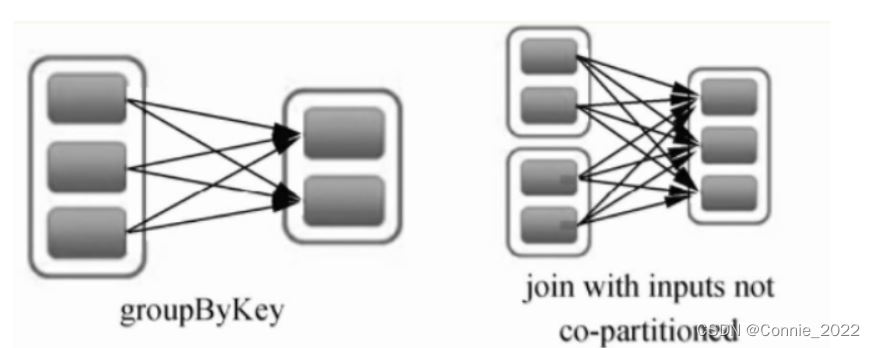
5、宽依赖和窄依赖的对比
相比于宽依赖,窄依赖对优化更有利,主要基于以下两点:
(1)宽依赖往往对应着shuffle操作,需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内完成转换。
(2)当RDD分区丢失时(某个节点故障),Spark会对数据进行重新计算。
对于窄依赖,由于父RDD的一个分区只对应一个子RDD,这样只需要重新计算和子RDD分区对应的父RDD分区即可,所以这个重新计算对数据的利用率是100%。
对于宽依赖,重算的父RDD分区对应多个子RDD分区,这样实际上父RDD中只有一部分数据是被用于恢复这个丢失的子RDD分区的,另一部分数据对应子RDD的其他未丢失分区,这就造成了多余的计算。一般情况下,宽依赖中的子RDD分区通常来自于多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。
如下图,b1分区丢失,则需要重新计算a1、a2和a3,这就产生了冗余计算(a1,a2,a3中对应b2的数据)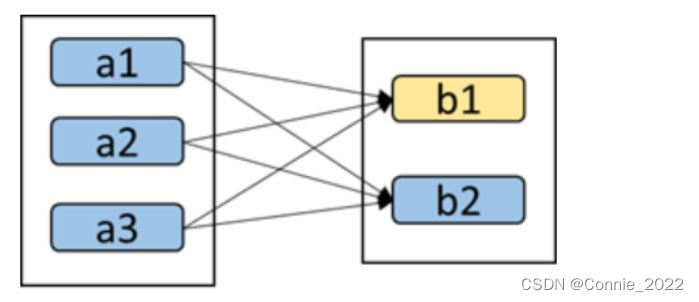

















 2567
2567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









