







DataFrame
DataFrame 是 Pandas 中最为常见、最重要且使用频率最高的数据结构。DataFrame 和平常的电子表格或 SQL 表结构相似。你可以把 DataFrame 看成是 Series 的扩展类型,它仿佛是由多个 Series 拼合而成。它和 Series 的直观区别在于,数据不但具有行索引,且具有列索引。
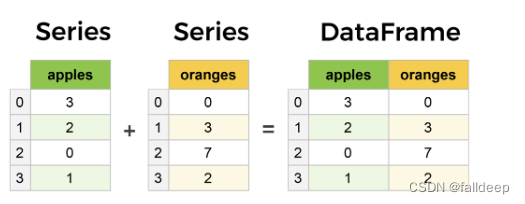
DataFrame 基本结构如下:
pandas.DataFrame(data=None, index=None, columns=None)区别于 Series,其增加了 columns 列索引。DataFrame 可以由以下多个类型的数据构建:
- 一维数组、列表、字典或者 Series 字典。
- 二维或者结构化的
numpy.ndarray。 - 一个 Series 或者另一个 DataFrame。
数据读取
我们想要使用 Pandas 来分析数据,那么首先需要读取数据。大多数情况下,数据都来源于外部的数据文件或者数据库。Pandas 提供了一系列的方法来读取外部数据,非常全面。下面,我们以最常用的 CSV 数据文件为例进行介绍。
读取数据 CSV 文件的方法是 pandas.read_csv(),你可以直接传入一个相对路径,或者是网络 URL。
df = pd.read_csv("https://labfile.oss.aliyuncs.com/courses/906/los_census.csv")
df基本操作
DataFrame 结构大致由 3 部分组成,它们分别是列名称、索引和数据。
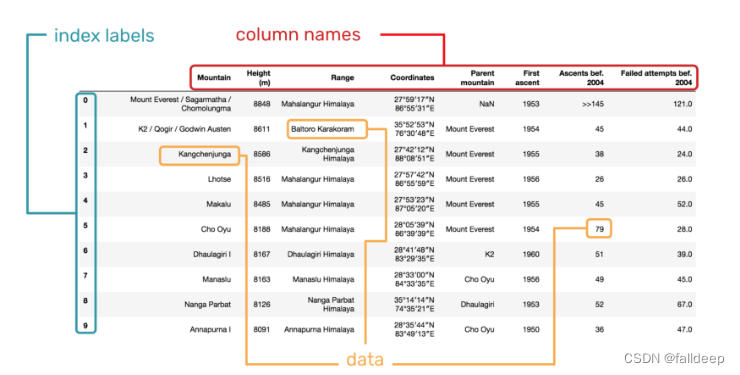
有些时候,我们读取的文件很大。如果全部输出预览这些文件,既不美观,又很耗时。还好,Pandas 提供了 head() 和 tail() 方法,它可以帮助我们只预览一小块数据。
df.head() # 默认显示前 5 条df.tail(7) # 指定显示后 7 条Pandas 还提供了统计和描述性方法,方便你从宏观的角度去了解数据集。describe() 相当于对数据集进行概览,会输出该数据集每一列数据的计数、最大值、最小值等。
df.describe()DataFrame转换为numpy
df.values
numpy转换为DataFrame
pd.DataFrame(np.random.randint(5, size=(5,)))数据选择
df.columns # 查看列名
df.shape #查看形状
df.shape[0] #行数
df.shape[1] #列数.iloc方法选择,基于数字索引对数据集进行选择
该方法可以接受的类型有:
- 整数。例如:
5 - 整数构成的列表或数组。例如:
[1, 2, 3] - 布尔数组。
- 可返回索引值的函数或参数。
首先,我们可以选择前 3 行数据。这和 Python 或者 NumPy 里面的切片很相似。
df.iloc[:3]那么选择多行,是不是 df.iloc[1, 3, 5] 这样呢?
答案是错误的。df.iloc[] 的 [[行],[列]] 里面可以同时接受行和列的位置,如果你直接键入 df.iloc[1, 3, 5] 就会报错。
所以,很简单。如果你想要选择 2,4,6 行,可以这样做。
df.iloc[[1, 3, 5]]选择行学会以后,选择列就应该能想到怎么办了。例如,我们要选择第 2-4 列。
df.iloc[:, 1:4]这里选择 2-4 列,输入的却是 1:4。这和 Python 或者 NumPy 里面的切片操作非常相似。既然我们能定位行和列,那么只需要组合起来,我们就可以选择数据集中的任何数据了。
.loc方式选取,利用标签名
除了根据数字索引选择,还可以直接根据标签对应的名称选择。这里用到的方法和上面的 iloc 很相似,少了个 i 为 df.loc[]。
df.loc[] 可以接受的类型有:
- 单个标签。例如:
2或'a',这里的2指的是标签而不是索引位置。 - 列表或数组包含的标签。例如:
['A', 'B', 'C']。 - 切片对象。例如:
'A':'E',注意这里和上面切片的不同之处,首尾都包含在内。 - 布尔数组。
- 可返回标签的函数或参数。
下面,我们来演示 df.loc[] 的用法。先选择前 3 行:
df.loc[0:2]再选择 1,3,5 行:
df.loc[[0, 2, 4]]然后,选择 2-4 列:
df.loc[:, 'Total Population':'Total Males']最后,选择 1,3 行和 Median Age 后面的列:
df.loc[[0, 2], 'Median Age':]数据删减
虽然我们可以通过数据选择方法从一个完整的数据集中拿到我们需要的数据,但有的时候直接删除不需要的数据更加简单直接。Pandas 中,以 .drop 开头的方法都与数据删减有关。
DataFrame.drop 可以直接去掉数据集中指定的列和行。一般在使用时,我们指定 labels 标签参数,然后再通过 axis 指定按列或按行删除即可。当然,你也可以通过索引参数删除数据,具体查看官方文档。
df.drop(labels=['Median Age', 'Total Males'], axis=1)DataFrame.drop_duplicates 则通常用于数据去重,即剔除数据集中的重复值。使用方法非常简单,指定去除重复值规则,以及 axis 按列还是按行去除即可。
df.drop_duplicates(keep = 'first' inplace = 'True')除此之外,另一个用于数据删减的方法 DataFrame.dropna 也十分常用,其主要的用途是删除缺少值,即数据集中空缺的数据列或行。
df.dropna()














 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









