






前言
首先说说transformer的整体架构:一文了解Transformer全貌(图解Transformer) (zhihu.com)
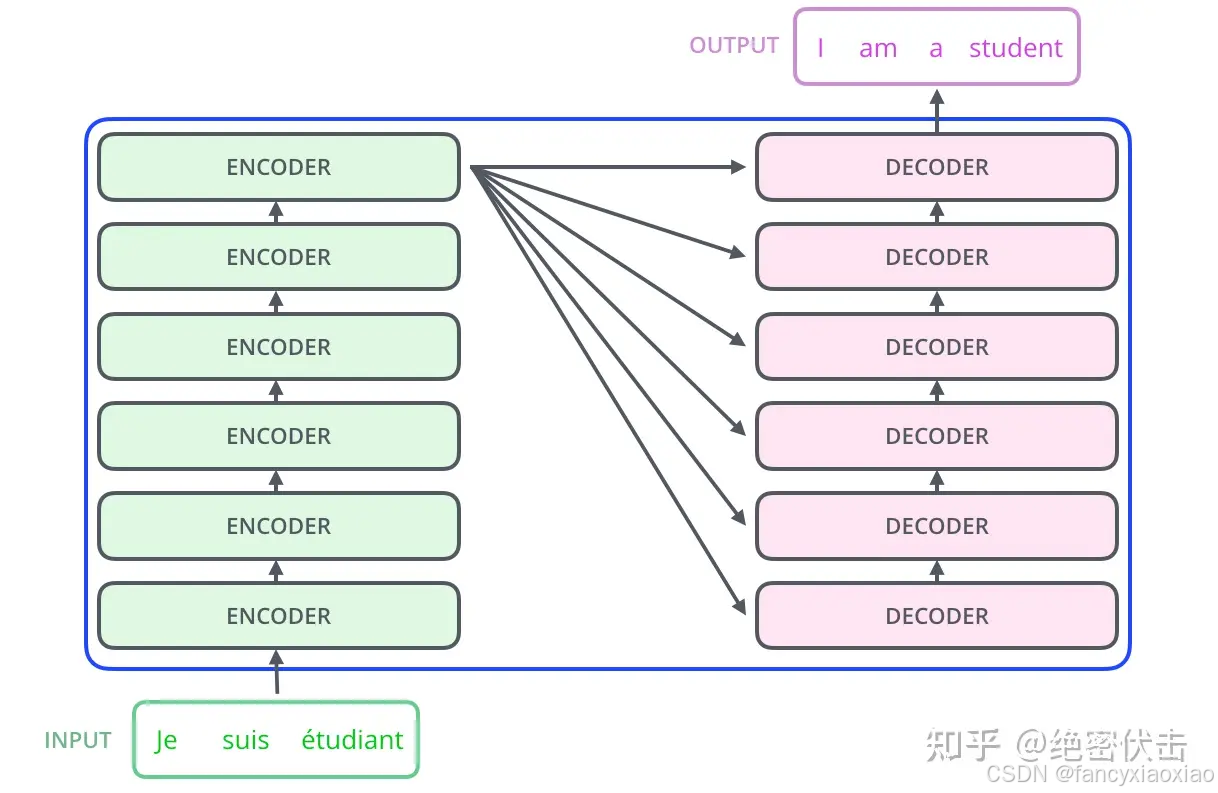
6个encoder和decoder,encoder和decoder的结构: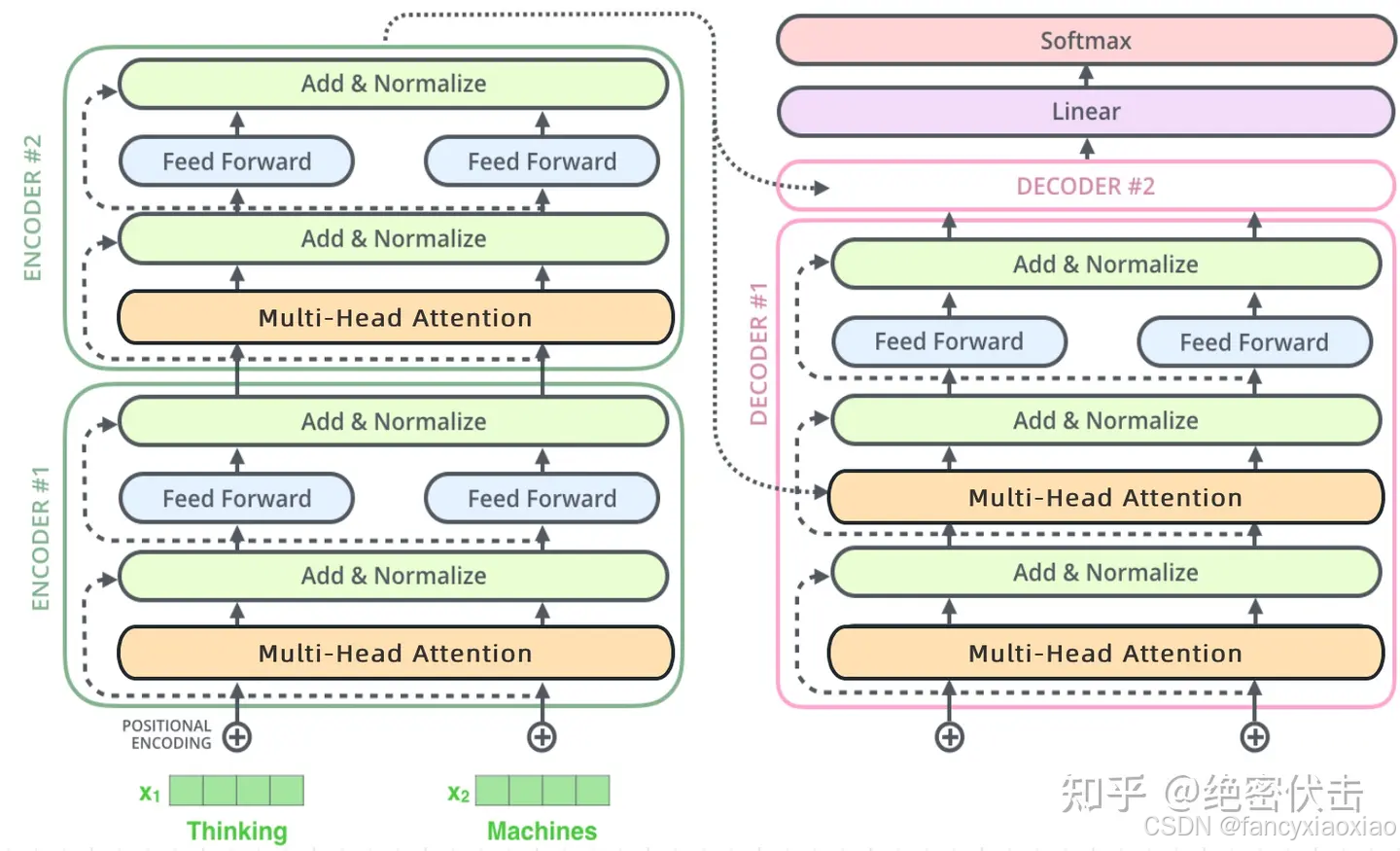
也就对应了那个经典的图:
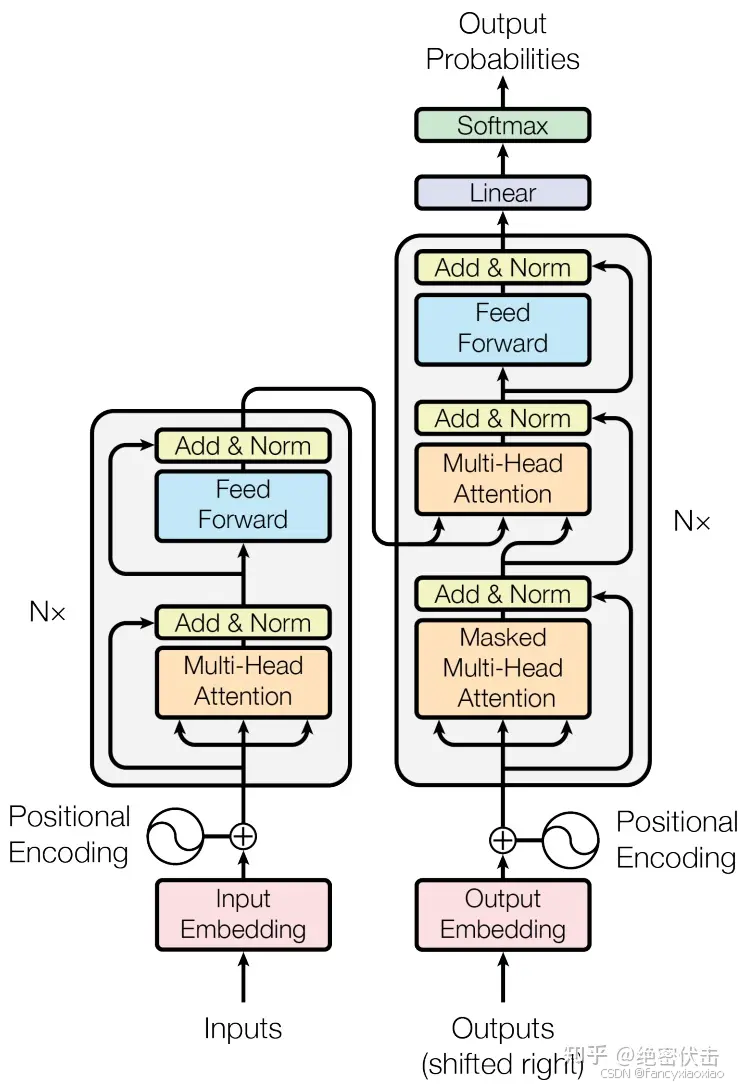
注意力层搭建
按照前面的第二幅图,从最下面的multi-head attention开始。首先大致说一下注意力机制:
自注意力机制允许模型直接计算序列中任意两个元素之间的关系,无论它们之间的距离有多远。这使得模型能够更好地捕捉长距离依赖关系(以前的LSTM和RNN要按照时间步一步步推)
自注意力机制可以同时计算序列中所有元素之间的关系,因此可以完全并行化处理。这使得 Transformer 模型在训练和推理时速度更快,尤其是在 GPU 或 TPU 等硬件上。
自注意力机制,强调自,也就是自身,自身相乘得到每个词之间的相似度
关于QKV的理解,知乎的文章说的很通俗易懂,看前半部分即可(有助于理解“自”的含义):注意力机制到底在做什么,Q/K/V怎么来的?一文读懂Attention注意力机制 (zhihu.com)
注意力机制:
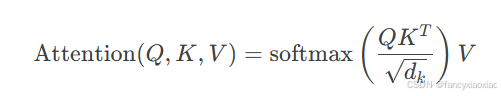
𝑑𝑘 是查询和键的维度
多头注意力机制:在前面的基础上拼接起来即可。
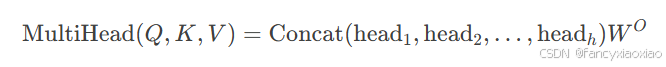
根据注意力机制的公式,有:
#点积注意力机制
class ScaleDotProductAttention(nn.Module):
def __init__(self,d_k):
#调用父类nn.module的初始化方法,两个参数一个当前类一个当前类的实例
#执行父类的初始化再执行子类的初始化
super(ScaleDotProductAttention,self).__init__()
self.d_k=d_k
def forward(self,q,k,v,attention_mask=None):
# q: [batch_size, n_heads, len_q, d_k]
# k: [batch_size, n_heads, len_k, d_k]
# v: [batch_size, n_heads, len_v, d_v]
# attn_mask: [batch_size, n_heads, seq_len, seq_len]
'''matmul可用于批量矩阵乘法,transpose交换维度,实现转置'''
#scores: [batch_size, n_heads, len_q, len_q]
scores=torch.matmul(q,k.transpose(-1,-2))/math.sqrt(self.d_k)
'''掩码的作用!输入序列通常会被填充到相同的长度以便批量处理,引入掩码使它们不参与计算;同时掩码可控制模型可见范围'''
scores=scores.masked_fill(attention_mask==0,-1e9)#把被mask的地方置为无限小,softmax之后基本就是0,也就对q不起作用
attn=nn.functional.softmax(scores,dim=-1)
context=torch.matmul(attn,v)
return context,attn(强调一下掩码的作用),注意一下这里代码其实已经做了多头注意力(matmul批量乘法,多个头一起计算了),后面的多头注意力层搭建严格来讲应该是进一步的完善。
多头注意力层搭建
每个头拼在一起,然后接一个线性层映射
参数d_model说明:在 Transformer 中,d_model 通常是一个固定的值,用于统一所有层的输入和输出维度(这个参数很重要)
输入序列中的每个词(或 token)会被映射为一个 d_model 维的向量;
在多头注意力机制中,d_model 被分割为多个头(n_heads),每个头的维度为 d_k 或 d_v;
(例如,如果 d_model = 512 且 n_heads = 8,则每个头的维度为 d_k = d_v = 64)
Transformer 中的前馈神经网络也使用 d_model 作为输入和输出的维度;
输入为词向量矩阵X,每个词为矩阵中的一行,经过与W进行矩阵乘法,首先生成Q、K和V。比如q1 = X1 * WQ
#多个头揉在一起,n_heads
class MultiHeadAttention(nn.Module):
def __init__(self,d_model,d_k,d_v,n_heads):
super(MultiHeadAttention,self).__init__()
self.d_model=d_model
self.d_k=d_k
self.d_v=d_v
self.n_heads=n_heads
'''可训练的qkv矩阵,详情见知乎说明'''
self.w_q=nn.Linear(d_model,d_k*n_heads,bias=False)
self.w_k=nn.Linear(d_model,d_k*n_heads,bias=False)
self.w_v=nn.Linear(d_model,d_v*n_heads,bias=False)
self.fc=nn.Linear(n_heads*d_v,d_model,bias=False)#映射回输入维度
self.layernorm=nn.LayerNorm(d_model)#层归一化在神经网络中用于稳定和加速训练过程
def forward(self,q,k,v,attention_mask=None):
# q: [batch_size, seq_len, d_model]
# k: [batch_size, seq_len, d_model]
# v: [batch_size, seq_len, d_model]
# attn_mask: [batch_size, seq_len, seq_len]
residual,batch_size=q,q.size(0) #residual存原始值
'''view调整张量形状'''
#q: [batch_size, n_heads, len_q, d_k]
q=self.w_q(q).view(batch_size,-1,self.n_heads,self.d_k).transpose(1,2)
k=self.w_k(k).view(batch_size,-1,self.n_heads,self.d_k).transpose(1,2)
v=self.w_v(v).view(batch_size,-1,self.n_heads,self.d_v).transpose(1,2)
#attn_mask : [batch_size, n_heads, seq_len, seq_len]
'''unsqueeze加一维,repeat复制多份,使得维度匹配和前面一样'''
attention_mask=attention_mask.unsqueeze(1).repeat(1,self.n_heads,1,1)
#context: [batch_size, n_heads, len_q, d_v]
context,attn=ScaleDotProductAttention(self.d_k)(q,k,v,attention_mask)
#context: [batch_size, len_q, n_heads * d_v]
'''前面n个头同时做,这里出来把他们拼接'''
context=context.transpose(1,2).reshape(batch_size,-1,self.n_heads*self.d_v)
#还原回去
output=self.fc(context)
'''transformer示意图中的——ADD&Norm'''
return self.layernorm(output+residual),attn在多头注意力代码里面:context,attn=ScaleDotProductAttention(self.d_k)(q,k,v,attention_mask)这一句就是调用注意力计算
拿到每个头的context后reshape,把他们拼在一起,接一个全连接层变回去

前馈神经网络层搭建+add&normalize
按照一开始贴的架构图,从下往上,注意力层完了就到了前馈神经层,feed forward。
两次全连接,再次强调d_model统一输入输出维度的作用!
(深思熟虑的设计:统一的维度使得 Transformer 的各个模块(如多头注意力层和前馈神经网络层)可以轻松组合和堆叠,而无需额外的维度调整,简洁高效,同时避免了维度不匹配的问题
#前馈神经网络部分,transformer示意图中的Feed Forward 两个线性全连接层
class PositionwiseFeedForwardNet(nn.Module):
def __init__(self,d_model,d_ff):
super(PositionwiseFeedForwardNet,self).__init__()
self.fc=nn.Sequential(
nn.Linear(d_model,d_ff),
nn.ReLU(),
nn.Linear(d_ff,d_model)
)
'''再次强调层归一化的作用'''
self.layernorm=nn.LayerNorm(d_model)
def forward(self,x):
#x:[batch_size, seq_len, d_model]
residual=x
output=self.fc(x)
#[batch_size, seq_len, d_model]
return self.layernorm(output+residual)注意这里的返回,把架构图中的add&normalize一起做了
解码层搭建
可以从架构图中看到,前面的注意力层和feed层都是decoder encoder的核心组件,有了他们就可以搭建decoder了。
#解码层
class DecoderLayer(nn.Module):
def __init__(self,d_model,d_k,d_v,d_ff,n_heads):
super(DecoderLayer,self).__init__()
'''和前面一样的多头和前馈'''
self.attention=MultiHeadAttention(d_model,d_k,d_v,n_heads)
self.pos_ffn=PositionwiseFeedForwardNet(d_model,d_ff)
def forward(self,inputs,attention_mask):
# inputs: [batch_size, seq_len, d_model]
#outputs: [batch_size, seq_len, d_model]
#attention_mask: [batch_size, seq_len, seq_len]
outputs,self_attn=self.attention(inputs,inputs,inputs,attention_mask)#qkv相同,都是inputs,编码层的输出
outputs=self.pos_ffn(outputs)
return outputs,self_attn这只是解码器的一层,而解码器本身还要处理一下输入——即加上位置编码。
解码器搭建
class PositionalEncoding(nn.Module):
def __init__(self,d_model,max_pos,device):
super(PositionalEncoding,self).__init__()
self.device=device
'''embedding的本质:将离散的索引映射为连续的向量,生成位置编码'''
'''比如:
位置索引 位置编码(向量)
0 [0.1, 0.2, 0.3, 0.4]
1 [0.5, 0.6, 0.7, 0.8]
2 [0.9, 1.0, 1.1, 1.2]
3 [1.3, 1.4, 1.5, 1.6]
4 [1.7, 1.8, 1.9, 2.0]
'''
self.pos_embedding=nn.Embedding(max_pos,d_model)
def forward(self,inputs):
seq_len=inputs.size(1)
#arange:等差数列的一维张量,用于前面位置索引
pos=torch.arange(seq_len,dtype=torch.long,device=self.device)
#[seq_len] -> [batch_size, seq_len]
pos=pos.unsqueeze(0).expand_as(inputs)
return self.pos_embedding(pos)self.pos_embedding=nn.Embedding(max_pos,d_model) max_pos确定嵌入层可以处理的最大位置索引,d_model是嵌入向量的维度
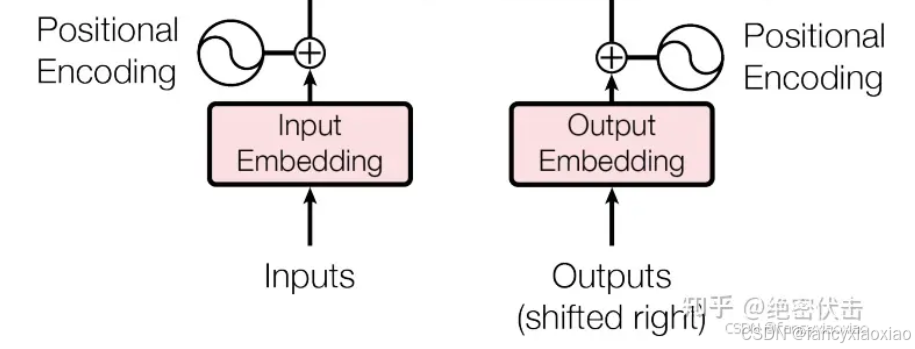
处理输入:把token转为向量,vocab是你的词表,这一坨的处理,对应的是架构图刚开始的部分:
这里的掩码有两部分组成,一部分上三角掩码,一部分是填充的掩码,两个加起来得到最终的掩码。
原始注意力分数矩阵(无掩码):
[[q1k1, q1k2, q1k3, q1k4],
[q2k1, q2k2, q3k3, q3k4],
[q3k1, q3k2, q3k3, q3k4],
[q4k1, q4k2, q4k3, q4k4]]
上三角掩码器:
[[0, 1, 1, 1],
[0, 0, 1, 1],
[0, 0, 0, 1],
[0, 0, 0, 0]]
应用掩码后的分数矩阵:
[[q1k1, -inf, -inf, -inf],
[q2k1, q2k2, -inf, -inf],
[q3k1, q3k2, q3k3, -inf],
[q4k1, q4k2, q4k3, q4k4]]modulelist调用各个层
'''对于Transformer Decoder结构,模型在解码时应该是自回归的,每次都是基于之前的信息预测下一个Token,这意味着在生成序列的第 i 个元素时,模型只能看到位置 i 之前的信息。因此在训练时需要进行遮盖,防止模型看到未来的信息,遮盖的操作也非常简单,可以构建一个上三角掩码器。'''
class Decoder(nn.Module):
def __init__(self, d_model, n_heads, d_ff, d_k, d_v, vocab_size, max_pos, n_layers, device):
super(Decoder, self).__init__()
self.device = device
# 将Token转为向量
self.embedding = nn.Embedding(vocab_size, d_model)
# 位置编码
self.pos_encoding = PositionalEncoding(d_model, max_pos, device)
self.layers = nn.ModuleList([DecoderLayer(d_model, n_heads, d_ff, d_k, d_v) for _ in range(n_layers)])
def forward(self, inputs, attention_mask):
##
# inputs: [batch_size, seq_len]
##
# [batch_size, seq_len, d_model]
outputs = self.embedding(inputs) + self.pos_encoding(inputs)
# 上三角掩码,防止看到未来的信息, [batch_size, seq_len, seq_len]
subsequence_mask = self.get_attn_subsequence_mask(inputs, self.device)
if attention_mask is not None:
# pad掩码 [batch_size, seq_len, seq_len]
attention_mask = self.get_attn_pad_mask(attention_mask)
# [batch_size, seq_len, seq_len]
attention_mask = torch.gt((attention_mask + subsequence_mask), 0)
else:
attention_mask = subsequence_mask.bool()
# 计算每一层的结果
self_attns = []
for layer in self.layers:
# outputs: [batch_size, seq_len, d_model],
# self_attn: [batch_size, n_heads, seq_len, seq_len],
outputs, self_attn = layer(outputs, attention_mask)
self_attns.append(self_attn)
return outputs, self_attns
def get_attn_subsequence_mask(self,seq,device):
#生成上三角掩码
## 注意力分数的大小是 [batch_size, n_heads, len_seq, len_seq]
#所以这里要生成 [batch_size, len_seq, len_seq] 大小
attn_shape=[seq.size(0),seq.size(1),seq.size(1)]
#triu获得矩阵上三角部分
subsequence_mask=np.triu(np.ones(attn_shape),k=1).astype(np.uint8)
subsequence_mask = torch.tensor(subsequence_mask, dtype=torch.bool).to(device)
return subsequence_mask
def get_attn_pad_mask(self,attention_mask):
#attention_mask 的掩码大小调整,要转换成 [batch_size, len_seq, len_seq] 大小,方便和注意力分数计算
batch_size,len_seq=attention_mask.size()
#eq返回布尔张量,逐元素比较,=0返回True
attention_mask=attention_mask.data.eq(0).unsqueeze(1)
#[batch_size, len_seq, len_seq]大小
return attention_mask.expand(batch_size,len_seq,len_seq)GPTmodel搭建
编码器负责将输入序列(如句子)转换为一系列隐藏表示,而解码器则根据这些隐藏表示生成输出序列
GPT模型只使用解码器,因为它是一个自回归模型,通过前面的词来预测下一个词。它不需要编码器来处理输入序列,因为它生成文本时是逐步进行的,每一步都依赖于之前生成的词。
(这也就是为什么前面只贴了解码器,对输入序列的处理不需要encoder,只用embedding就可以)
再次强调:
在自回归生成任务中(如文本生成、语言模型等),模型只需要解码器来生成序列。解码器通过自注意力机制和前馈神经网络逐步生成输出序列。
编码器通常用于处理输入序列(如翻译任务中的源语言句子),但在纯生成任务中,输入序列可能不存在,或者输入序列本身就是模型生成的上下文。
'''上面构建好解码器之后,就可以得到处理后的特征,下面还需要将特征转为词表大小的概率分布,才能实现对下一个Token的预测。'''
class GPTModel(nn.Module):
def __init__(self,d_model,n_heads,d_ff,d_k,d_v,vocab_size,max_pos,n_layers,device):
super(GPTModel,self).__init__()
#解码器
self.decoder=Decoder(d_model,n_heads,d_ff,d_k,d_v,vocab_size,max_pos,n_layers,device)
#映射为词表大小
self.projection=nn.Linear(d_model,vocab_size)
def forward(self,inputs,attention_mask=None):
outputs,self_attns=self.decoder(inputs,attention_mask)
#这是模型对每个位置的预测得分:[batch_size, seq_len, vocab_size]
logits=self.projection(outputs)
#展开为[batch_size*seq_len, vocab_size]
return logits.view(-1,logits.size(-1)),self_attns输入序列经过解码器拿到处理后的信息,再把它反向映射回词表。(词表构建在下文)
模型全部构建完成,可以打印看下总参数量:
import torch
from model import GPTModel
def main():
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#模型参数
model_params={
"d_model":768,#嵌入层大小
"d_ff":2048,#FFN层大小
"d_k":64,#k的大小
"d_v":64,
"n_layers":6,#解码层数量
"n_heads":8,
"max_pos":1800,#位置编码的长度
"device":device,
"vocab_size":48256#词表大小
}
'''经典传参方式!字典解包传播'''
model=GPTModel(**model_params)
#p.numel() 计算每个参数的元素数量
total_params=sum(p.numel() for p in model.parameters())
print(model)
print(f"Total number of parameters: {total_params}")
if __name__=="__main__":
main()
'''
GPTModel(
(decoder): Decoder(
(embedding): Embedding(1800, 768)
(pos_encoding): PositionalEncoding(
(pos_embedding): Embedding(48256, 768)
)
(layers): ModuleList(
(0-5): 6 x DecoderLayer(
(attention): MultiHeadAttention(
(w_q): Linear(in_features=768, out_features=512, bias=False)
(w_k): Linear(in_features=768, out_features=512, bias=False)
(w_v): Linear(in_features=768, out_features=131072, bias=False)
(fc): Linear(in_features=131072, out_features=768, bias=False)
(layernorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(pos_ffn): PositionwiseFeedForwardNet(
(fc): Sequential(
(0): Linear(in_features=768, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=768, bias=True)
)
(layernorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
)
)
(projection): Linear(in_features=768, out_features=48256, bias=True)
)
Total number of parameters: 1288843264
'''词表构建
数据集使用对话-百科(中文)训练集,有 274148 条问答对信息,涵盖了 美食、城市、企业家、汽车、明星八卦、生活常识、日常对话 等信息。
数据集下载地址:
数据格式:
{"question": "你好,最近怎么样?", "answer": "你好!我最近还不错,谢谢。"}
{"question": "今天天气如何?", "answer": "今天的天气很晴朗。"}
{"question": "你喜欢旅行吗?", "answer": "是的,我非常喜欢旅行。"}
{"question": "你最喜欢的食物是什么?", "answer": "我最喜欢的食物是寿司。"}
{"question": "你有什么兴趣爱好?", "answer": "我喜欢阅读和运动。"}
{"question": "你最喜欢的电影是什么?", "answer": "我最喜欢的电影是《肖申克的救赎》。"}
{"question": "你喜欢听音乐吗?", "answer": "是的,我喜欢听流行音乐。"}
{"question": "你最喜欢的季节是哪个?", "answer": "我最喜欢的季节是夏天。"}
{"question": "你有什么宠物吗?", "answer": "是的,我有一只猫。"}token:指的是将文本分割成的最小单位,可以是单词、子词或字符等,是模型处理文本的基本单元。
在 NLP 中,文本通常会被分解成一系列 Token,然后这些 Token 会被映射为数值(如索引或向量),以便模型能够处理。
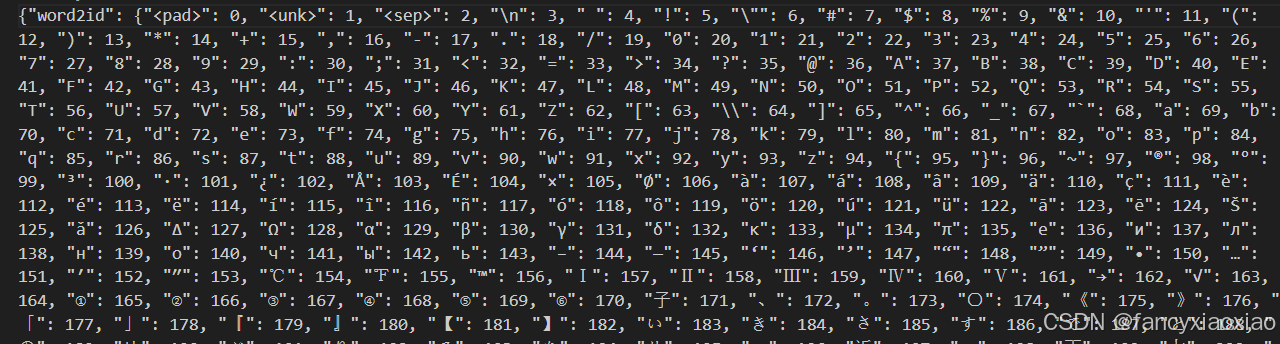
这里将一个字作为一个token,理论上词表可以直接在网上找。词表需要拼接三个特殊Token,用于表示特殊意义: pad 占位、unk 未知、sep 结束
'''构建词表,这里我将一个字作为一个词,也可以优化通过分词器分词后的词构建词表,需要注意的时,词表需要拼接三个特殊Token,用于表示特殊意义: pad 占位、unk 未知、sep 结束'''
import json
def build_vocab(file_path):
texts=[]
with open(file_path, 'r', encoding='utf-8') as r:
for line in r:
if not line:#跳过空行
continue
try:
line=json.loads(line)#每一行解析为json对象,即python字典
except:
print(f"json解析失败:{line}")
exit()
question=line['question']
answer=line['answer']
texts.append(question)
texts.append(answer)
#拆分token
words=set()#确保不重复
for t in texts:
if not t:
continue
for word in t.strip():#去除字符串 开头和结尾 的空白字符
words.add(word)
words=list(words)
words.sort()
word2id={"<pad>":0,"<unk>":1,"<sep>":2}
#构建词表
word2id.update({word:i+len(word2id) for i,word in enumerate(words)})#从2开始往后添加
id2word=list(word2id.keys())
vocab={"word2id":word2id,"id2word":id2word}#双向映射便于查找
vocab=json.dumps(vocab,ensure_ascii=False)#序列化为json字符串
with open("data/vocab.json","w",encoding="utf-8") as w:
w.write(vocab)
print("词表构建完成,共{}个词".format(len(word2id)))
if __name__=="__main__":
file_path="data/rawtrain.jsonl"
build_vocab(file_path)
核心:每个字对应一个数字编码(按出现顺序递增,012是特殊字符),注意双向映射的构建
(这里rawtrain是从前面魔塔社区下下来的数据)
tokenizer搭建
在自回归模型中,Tokenizer 的主要任务是将输入文本转换为 Token 序列,并将 Token 序列映射为模型输入所需的数值形式
经典的桥梁!文本->token->数值
核心:text和text1分别对应question和answer,他们的词在双向映射中找,找到构成一个列表
Tokenizer 会生成注意力掩码,用于指示哪些 Token 是真实的,哪些是填充的。
是的没错,处理输入序列的encoder其实在这。
import json
class Tokenizer():
def __init__(self, vocab_path):
with open(vocab_path, "r", encoding="utf-8") as r:
vocab = r.read()
if not vocab:
raise Exception("词表读取为空!")
vocab = json.loads(vocab)
self.word2id = vocab["word2id"]
self.id2word = vocab["id2word"]
self.pad_token = self.word2id["<pad>"]
self.unk_token = self.word2id["<unk>"]
self.sep_token = self.word2id["<sep>"]
def encode(self, text, text1=None, max_length=128, pad_to_max_length=False):
tokens = [self.word2id[word] if word in self.word2id else self.unk_token for word in text]
tokens.append(self.sep_token)
if text1:
tokens.extend([self.word2id[word] if word in self.word2id else self.unk_token for word in text1])
tokens.append(self.sep_token)
att_mask = [1] * len(tokens)
if pad_to_max_length:
if len(tokens) > max_length:
tokens = tokens[0:max_length]
att_mask = att_mask[0:max_length]
elif len(tokens) < max_length:
tokens.extend([self.pad_token] * (max_length - len(tokens)))
att_mask.extend([0] * (max_length - len(att_mask)))
return tokens, att_mask
def decode(self, token):
if type(token) is tuple or type(token) is list:
return [self.id2word[n] for n in token]
else:
return self.id2word[token]
def get_vocab_size(self):
return len(self.id2word)max_length长度怎么确定的128?——见后面
数据集划分
训练集取魔塔社区下下来数据的前一万条(总共27万条,也可以多取点,训练时间可能会延长很多),验证取一千条
import os.path
#数据集分割为训练集和验证集
def seplit_dataset(file_path,output_path):
if not os.path.exists(output_path):
os.mkdir(output_path)
datas=[]
with open(file_path,'r',encoding='utf-8') as f:
for line in f:
if not line or line=='':
continue
datas.append(line)
train = datas[0:10000]
val=datas[10000:11000]
with open(os.path.join(output_path,'train.jsonl'),'w',encoding='utf-8') as f:
for line in train:
f.write(line)
f.flush()#确保每一条数据都被及时写入到磁盘
with open(os.path.join(output_path,'val.jsonl'),'w',encoding='utf-8') as f:
for line in val:
f.write(line)
f.flush()
print("train count: ",len(train))
print("val count: ",len(val))
if __name__ == '__main__':
file_path="data/rawtrain.jsonl"
seplit_dataset(file_path,output_path='data')确定max_length:
import json
from tokenizer import Tokenizer
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#中文文本黑体显示
def get_num_tokens(file_path,tokenizer):
input_num_tokens = []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
line=json.loads(line)
question=line['question']
answer=line['answer']
tokens,att_mask=tokenizer.encode(question,answer)
input_num_tokens.append(len(tokens))
return input_num_tokens
#统计 num_tokens 列表中数值落在不同区间内的数量
def count_intervals(num_tokens,interval):
max_value=max(num_tokens)
intervals_count={}
for lower_bound in range(0,max_value+1,interval):
upper_bound=lower_bound+interval
count=len([num for num in num_tokens if num>=lower_bound and num<upper_bound])
intervals_count[f"{lower_bound}--{upper_bound}"]=count
return intervals_count
def main():
train_data_path='data/train.jsonl'
tokenizer=Tokenizer("data/vocab.json")
input_num_tokens=get_num_tokens(train_data_path,tokenizer)
intervals_count=count_intervals(input_num_tokens,20)
print(intervals_count)
x=[k for k in intervals_count.keys()]
y=[v for v in intervals_count.values()]
plt.figure(figsize=(11,8))#创建画布
bars=plt.bar(x,y)#绘制柱状图,返回每个柱的对象
plt.title('训练集token的分布情况')
plt.ylabel('数量')
plt.xticks(rotation=45)
for bar in bars:
yval=bar.get_height()
#plt.text():在每个柱的顶部中心位置显示其数值。x坐标,y坐标,显示的内容,位置
plt.text(bar.get_x()+bar.get_width()/2,yval,int(yval),ha='center')
plt.show()
if __name__ == '__main__':
main()
看一下每条数据大概占多少token,大多都在120以内,所以这里取128.
模型训练
准备数据集:question和answer每一对放在字典里,preprocess预处理,注意错位预测的感觉
#用于创建训练模型需要的数据集
from torch.utils.data import Dataset
import torch
import json
import numpy as np
class QADataset(Dataset):
def __init__(self, data_path, tokenizer,max_length)->None:#箭头用于函数的类型注解,表示函数返回类型
super().__init__()
self.tokenizer = tokenizer
self.max_length = max_length
self.data=[]
if data_path:
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
if not line or line=="":
continue
json_line = json.loads(line)
question = json_line['question']
answer = json_line['answer']
#每一个问题和回答对都处理为一个字典
self.data.append(
{"question": question, "answer": answer}
)
print("data load , size: ",len(self.data))
#用于将输入的 question 和 answer 文本预处理为模型可以接受的输入格式
def preprocess(self,question,answer):
#拿到token ID 序列和注意力掩码
encode,att_mask = self.tokenizer.encode(question,answer,max_length=self.max_length,pad_to_max_length=True)
'''
input_ids:去掉最后一个 token 的 token ID 序列,作为模型的输入。
att_mask:去掉最后一个 token 的注意力掩码,与 input_ids 对应。
labels:去掉第一个 token 的 token ID 序列,作为模型的标签(目标输出)
为什么这么做?——自回归模型
input_ids 去掉最后一个 token:是因为模型的输入序列是用来预测下一个 token,而不包括预测的最后一个 token。
labels 去掉第一个 token:是因为目标输出是模型需要预测的下一个 token,因此目标序列应该从第一个 token 的下一个开始。
错位的感觉
'''
input_ids = encode[:-1]
att_mask=att_mask[:-1]
labels = encode[1:]
return input_ids,att_mask,labels
def __getitem__(self, index):
item_data=self.data[index]
input_ids,att_mask,labels=self.preprocess(**item_data)
return {
"input_ids": torch.LongTensor(np.array(input_ids)),
"attention_mask": torch.LongTensor(np.array(att_mask)),
"labels": torch.LongTensor(np.array(labels))
}
def __len__(self):
return len(self.data)
-
实现
__getitem__和__len__方法,使数据集可以被 PyTorch 的DataLoader使用。
训练过程:
数据集QAdataset构建的input_ids attention_mask那些在这里使用,拿到之后一样的optimizer.zero_grad() 计算loss,反向传播,optimizer.step
在训练深度学习模型时,梯度可能会变得非常大(尤其是当模型很深或学习率很高时),这种现象被称为 梯度爆炸(Gradient Explosion)。梯度爆炸会导致模型参数更新不稳定,甚至导致训练失败。
梯度裁剪通过限制梯度的范数(即梯度的大小)来缓解梯度爆炸问题,从而稳定训练过程
最后注意一下正常的保存模型即可
import torch
from torch.utils.data import DataLoader
from tokenizer import Tokenizer
from model import GPTModel
from dataset import QADataset
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
import os,time,json,sys
def train_model(model,train_loader,val_loader,optimizer,criterion,device,num_epochs,model_output_dir,writer):
batch_step=0
best_val_loss=float('inf')
for epoch in range(num_epochs):
time1=time.time()
model.train()
#tqdm在循环中显示进度条,desc设置显示的文字
for index,data in enumerate(tqdm(train_loader,file=sys.stdout,desc="train epoch: "+str(epoch))):
inputs_ids=data['input_ids'].to(device,dtype=torch.long)
attention_mask=data['attention_mask'].to(device,dtype=torch.long)
labels=data['labels'].to(device,dtype=torch.long)
optimizer.zero_grad()
outputs,dec_self_attns=model(inputs_ids,attention_mask)
loss=criterion(outputs,labels.view(-1))
loss.backward()
#梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(),1)
optimizer.step()
writer.add_scalar("loss/train",loss.item(),batch_step)
batch_step+=1
if index%100==0 or index==len(train_loader)-1:
time2=time.time()
tqdm.write(
f"{index},epoch:{epoch}-loss:{str(loss)};lr:{optimizer.param_groups[0]['lr']};eachstep'stimespent:{(str(float(time2-time1)/float(index+0.0001)))}")
#验证
model.eval()
val_loss=validate_model(model,criterion,device,val_loader)
writer.add_scalar("loss/val",val_loss,epoch)
print(f"val_loss:{val_loss} , epoch:{epoch}")
#保存最优模型
if val_loss<best_val_loss:
best_val_loss=val_loss
best_model_path=os.path.join(model_output_dir,"best.pt")
os.makedirs(model_output_dir, exist_ok=True)
print("save best model to ",best_model_path,"epoch: ",epoch)
torch.save(model.state_dict(),best_model_path)
#保存当前模型
last_model_path=os.path.join(model_output_dir,"last.pt")
os.makedirs(model_output_dir, exist_ok=True)
print("save last model to ",last_model_path,"epoch: ",epoch)
torch.save(model.state_dict(),last_model_path)
def validate_model(model,criterion,device,val_loader):
running_loss=0.0
with torch.no_grad():
for index,data in enumerate(tqdm(val_loader,file=sys.stdout,desc="validation data")):
inputs_ids=data['input_ids'].to(device,dtype=torch.long)
attention_mask=data['attention_mask'].to(device,dtype=torch.long)
labels=data['labels'].to(device,dtype=torch.long)
outputs,dec_self_attns=model(inputs_ids,attention_mask)
loss=criterion(outputs,labels.view(-1))
running_loss+=loss.item()
val_loss=running_loss/len(val_loader)
return val_loss
def main():
train_json_path="data/train.jsonl"
val_json_path="data/val.jsonl"
vocab_path="data/vocab.json"
max_length=120 #最大长度
epochs=15
batch_size=128
learning_rate=0.25*1e-4
model_output_dir="output"
logs_dir="logs"
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
tokenizer=Tokenizer(vocab_path)
#模型参数
model_param={
"d_model":768,#嵌入层大小
"d_ff":2048,#FFN层大小
"d_k":64,#k的大小
"d_v":64,
"n_layers":6,#解码层数量
"n_heads":8,
"max_pos":1800,#位置编码的长度
"device":device,
"vocab_size":tokenizer.get_vocab_size()
}
model=GPTModel(**model_param)
print("start load training data...")
train_params={
"batch_size":8,
"shuffle":True,
"num_workers":4,
}
training_set=QADataset(train_json_path,tokenizer,max_length)
training_loader=DataLoader(training_set,**train_params)
print(training_loader)
print("start load validation data...")
val_params={
"batch_size":8,
"shuffle":False,
"num_workers":4,
}
val_set=QADataset(val_json_path,tokenizer,max_length)
val_loader=DataLoader(val_set,**val_params)
#日志记录
writer=SummaryWriter(logs_dir)
optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate)
criterion=torch.nn.CrossEntropyLoss(ignore_index=0).to(device)
model=model.to(device)
#开始训练
print("start training...")
train_model(
model=model,
train_loader=training_loader,
val_loader=val_loader,
optimizer=optimizer,
criterion=criterion,
device=device,
num_epochs=epochs,
model_output_dir=model_output_dir,
writer=writer
)
writer.close()
if __name__=="__main__":
main()使用python training.py即可开始训练。视对应的硬件性能可以调整训练集和测试集的batch-size和学习率加速训练。

预测
import torch
from model import GPTModel
from tokenizer import Tokenizer
def generate(model, tokenizer, text, max_length, device):
#文本的输入一定要经过tokenizer的encode转为编码!
input, att_mask = tokenizer.encode(text)
'''将形状为 (seq_len,) 的张量转换为 (1, seq_len),使其符合模型的输入格式(通常是批量输入)'''
input = torch.tensor(input, dtype=torch.long, device=device).unsqueeze(0)#在第0维度加一维
stop = False
input_len = len(input[0])
while not stop: # 使用 stop 变量控制循环
if len(input[0]) - input_len > max_length:#当前序列长度-初始序列长度大于最大长度,则停止生成
next_symbol = tokenizer.sep_token#如果大于了,设置分隔符并cat到末尾
input = torch.cat(
[input.detach(), torch.tensor([[next_symbol]], dtype=input.dtype, device=device)], -1)
break
'''模型的输出是一个词概率的分布!squeeze?'''
projected, self_attns = model(input)
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]#拿到最后一个维度,即词表的最大值(概率)
next_word = prob.data[-1]#取 prob 的最后一个元素,即序列中最后一个位置预测的最可能的词
next_symbol = next_word
if next_symbol == tokenizer.sep_token:
stop = True
input = torch.cat(
[input.detach(), torch.tensor([[next_symbol]], dtype=input.dtype, device=device)], -1)#不断拼接前面生成的字符,流式输出
decode = tokenizer.decode(input[0].tolist())
decode = decode[len(text):]#从解码后的字符串中去掉原始输入文本的部分,只保留模型生成的部分
return "".join(decode)
def main():
model_path="output/last.pt"
vocab_path="data/vocab.json"
max_length=128
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
tokenizer=Tokenizer(vocab_path)
model_param={
"d_model":768,#嵌入层大小
"d_ff":2048,#FFN层大小
"d_k":64,#k的大小
"d_v":64,
"n_layers":6,#解码层数量
"n_heads":8,
"max_pos":1800,#位置编码的长度
"device":device,
"vocab_size":tokenizer.get_vocab_size()
}
model=GPTModel(**model_param)
model.load_state_dict(torch.load(model_path))
model.to(device)
while(True):
text=input("请输入:")
if not text:
continue
if text=="q":
break
res=generate(model,tokenizer,text,max_length,device)
print("AI: ",res)
if __name__=="__main__":
main()完整的代码:(仅是本人学习transformer过程中的一个记录)
yxyxyyx/gpt_disabled · Hugging Face![]() https://huggingface.co/yxyxyyx/gpt_disabled
https://huggingface.co/yxyxyyx/gpt_disabled
tensorboard --logdir=logs --port=6006
后续:测试了一下发现效果不是很理想,反正代码是能跑,不知道是不是中途服务器断了导致效果不好……
后面再重新炼一遍模型……
to be continued

















 5512
5512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









