









程序的机器级表示——概述
程序的机器表示是程序的二进制表示,实际上是一系列指令,这些指令可以用汇编代码展现(且其产生过程也是由汇编代码产生)。本节介绍了汇编以及生成汇编的编译、链接过程,鉴于本书面 向的是软工、数据科学等高级语言编程者,重点在于介绍以C语言为代表的高级语言转换为机器指令的机制。
本节更多的内容可见编译原理的相关讲述。
高级语言转换为机器指令的机制
-
计算机执行机器代码,用字节序列编码低级的操作
编译器基于编程语言的规则、目标机器的指令集和操作系统遵循的惯例
经过一系列的阶段生成机器代码 -
GCC C语言编译器以汇编代码的形式产生输出,汇编代码是机器代码的文本表示
然后GCC调用汇编器和链接器,根据汇编代码生产可执行的机器代码
认识机器指令——汇编
高级语言和汇编的区别
-
高级语言:
- 隐藏了诸多机器级别的特征或将其抽象化,与机器指令并非一一对应
- 靠近自然语言和数学语言,便于编程者理解和编码
- 计算机不能直接识别和执行用高级语言编写的程序,需要编译或解释;
- 有一定的通用、跨平台特性
-
汇编语言:
- 助记符指令和机器指令一一对应。
- 用汇编语言编制的程序效率高,占用存储空间小,运行速度快。汇编语言能编写出最优化的程序,且能反映计算机的实际运行情况。
- 汇编语言能直接与存储器、接口电路打交道,也能申请中断。因此汇编语言程序能直接管理和控制硬件设备。
- 语句偏离自然语言特性但反应了机器实现指令的特性,编程难但是忠实反应机器实现指令的过程
- 缺乏通用性,程序不易移植。不同计算机(准确的来说是不同的CPU构型)的汇编语言之间是不能通用的,但是一个方面相同的CPU构型会有相似的汇编语言(因为汇编语言的标准由CPU构型厂家决定),另一方面汇编语言间仍有相似点。
为什么要认识汇编
- 理解编译器的优化能力,并分析代码中隐含的低效率
- 了解优化C语言及其他高级语言程序的办法
- 了解程序漏洞和bug的生成方式以便于避免
- 通过阅读机器指令可以在无法获取源代码的情况下分析程序的逻辑和运行方式
机器指令中的抽象

-
对程序执行过程的抽象
- 是将机器级程序的格式和行为定义为指令集体系结构。它定义了处理器状态、指令的格式,以及每条指令对状态的影响。
- 将程序的行为描述成好像每条指令是按顺序执行的,即一条指令结束后,下一条指令开始。
-
对内存的抽象(虚拟内存)
- 机器程序使用的存储器地址是虚拟地址,提供的存储器模型看上去是一个非常大的字节数组。存储器系统的实际实现是将多个硬件存储器和操作系统软件组合起来。
- C 语言提供的模型可以在存储器中声明和分配各种数据类型的对象。但是实际上机器代码则只是简单的将存储器看成是一个很大的、按字节寻址的数组。
-

- 注意上图的“运行堆”和“用户栈”,运行堆存储用malloc/new等内存分配方法分配的内存和对象(Java等面向对象语言),用户栈存储变量和递归中的后续函数(递归栈)。具体的区别和实现见下。
-
- 机器只能区分4、8、16、32、64位数,不能区分字符、整数,不区分各种指针,甚至不区分指针和整数。浮点数使用的是另外一套机制存储。
-
对处理器结构的抽象
在汇编语言中,如下的几个处理器状态是可见的:- ①程序计数器(在 amd64 中通常称为 PC,用 %rip 表示):指示将要执行的下一条指令在存储器中的地址。
- ②整数寄存器文件:包含8个命名的位置,可以存储一些地址或者整数的数据。有的用来记录某些重要的程序状态,有的则用来保存临时数据。
- ③条件码寄存器:保存最近执行的算数或逻辑指令的状态信息,它们用来实现控制或数据流中的条件变化,比如用来实现 if 和 while 语句。
- ④浮点寄存器:存储浮点数。
-
对其它IO设备的抽象(万物皆文件)
现行的汇编代码
如何产生汇编代码
在linux中使用
gcc -Og -c mstore.c
可以用gcc编译器将mstore.c编译为二进制文件mstore.o
若是用
gcc -Og -S mstore.c
则可以展示该段C语言代码的编译语言逻辑
其实还是这张老图:

一个c语言程序在编译为汇编命令后之后需要汇编和链接才可以形成可执行目标程序。虽然但是,了解中间阶段的汇编对于了解程序运行原理仍会有所助益。
c语言程序的结构
- 变量(Variable)
- 可定义并使用不同的数据类型
- 运算(Operation)
- 赋值、算术表达式计算
- 控制
- 循环
- 过程(函数)的调用/返回
汇编代码的基本结构
以
multstore:
.LFB24:
.cfi_startproc
endbr64
pushq %rbx
.cfi_def_cfa_offset 16
.cfi_offset 3, -16
movq %rdx, %rbx
call mult2
movq %rax, (%rbx)
popq %rbx
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE24:
.size multstore, .-multstore
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "%ld"
.text
.globl main
.type main, @function
为例
(其源代码为:
#include<stdio.h>
long mult2(long a,long b){
return a*b;
}
void multstore(long x,long y,long *dest){
long t = mult2(x,y);
*dest = t;
}
int main(void){
long a=3,b=4;
long to;
multstore(a,b,&to);
printf("%ld",to);
return 0;
}
中的"multstore")
- 该示例代码使用的是AT&T标准下形成的×86_64汇编代码,特点:
- 虚拟存储代码前有%,且内存和寄存器使用类似的格式表达
- 动作指令后有表示大小和动作方式的后缀
.开头的内容称之为“伪指令”,是有关操作系统和编译器的杂乱信息,只有格式为动作 操作数 被操作数的部分才是与CPU计算与内存动作有关的真指令。每一条指令代表一个计算机步骤,如pushq %rdx代表将%rdx寄存器内容压入栈内存- 与intel格式汇编的对比

由机器代码获取可读的汇编代码
- 如何由机器代码生成汇编代码?
objdump -d再加上文件名即可直接在终端看到由反汇编器恢复的汇编代码。注意,文件名并不一定得是.o文件,任何可执行文件都可以。
上述程序编译为二进制文件后的反汇编代码如下图所示:

- 其中一些关于机器代码和它的反汇编表示的特性值得注意:
- x86-64的指令长度从1到15个字节不等。常用的指令以及操作数较少的指令所需的字节数少,而那些不太常用或操作数较多的指令所需字节数较多。这是因为复杂指令集用多指令的组合表达多操作指令,是复杂指令集的特性。与复杂指令集相对的是精简指令集,其尽可能减少指令长度,代之以分别定义不同指令并只保留计算机基础运行所需的少量指令。
- 设计指令格式的方式是,从某个给定位置开始,可以将字节唯一地解码成机器指令。例如,只有指令pushq %rbx是以字节值53开头的。
- 反汇编器只是基于机器代码文件中的字节序列来确定汇编代码。它不需要访问该程序的源代码或汇编代码。
- 反汇编器使用的指令命名规则与GCC生成的汇编代码使用的有些细微的差别。在我们的示例中,它省略了很多指令结尾。这些后缀是大小指示符,在大多数情况中可以省略。相反,反汇编器给call和ret指令添加了‘q’后缀,同样,省略这些后缀也没有问题。
汇编语言在计算和控制上的特点
- 用寄存器、内存数据完成算术功能
- 在内存和寄存器之间传送(拷贝)数据
- 从内存载入数据到寄存器
- 将寄存器数据保存到内存
- 在内存和寄存器之间传送(拷贝)数据
- 转移控制
- 无条件跳转到函数或从函数返回
- 条件分支
数据格式
由于计算机是由16位体系结构扩展为32位体系结构的,Intel 用术语 “字”(word) 表示16位数据类型,因此 32 位表示 “双字”(double words),64 位数称为“四字”(quad words)
-
下图为32位系统中的数据类型声明

-
下图为64位系统中的声明
注意汇编代码的后缀,还是要强调字是16位时代的字长(两个字节或者4个十六进制数位)

访问信息
信息存在哪——寄存器结构
 以上为整数寄存器的结构。整数寄存器有16个位置
以上为整数寄存器的结构。整数寄存器有16个位置
- %rax为返回值,%rsp为栈内存的指针,
- 可以访问寄存器的低地址以访问该寄存器(事实上,保留低地址是为了低字长的运用,或者兼容旧的低字长的程序设计的,或向下兼容低字长处理器)
- 有一条特殊规则:当对某个寄存器的低4字节操作时,如%eax,会自动把高4个字节全置为0。
信息的操作——操作数指示符
- 大多数指令有一个或多个操作数(operand),指示出执行一个操作中要使用的源数据值,以及放置结果的目的位置。
- 下面所示为操作数操作符号及其操作的数值,其中Imm为立即数或寄存器,r为指针数,R为某个指针数或寄存器代号指向的操作数,M为总(虚拟)内存地址中的最终操作数。

- 立即数:$+标准整数,取得的操作数就是立即数
- 不带$的立即数:以该数为地址取立即数值
- 寄存器:寄存器地址
- (寄存器):寄存器地址内值
- 立即数1(寄存器1,寄存器2,立即数2),则取得的操作数就是以【立即数1的值+(寄存器1的值+寄存器2的值*立即数2)】为地址,对应取出的操作数
- 例子:

数据的传送
mov S,D,代表从S地址传送操作数至D

- mov后缀代表其操作的字节数
- 决定mov使用哪个后缀的是寄存器的大小,当两边操作的都是寄存器时,若大小不同,必须用第5条中的小数据复制到大目的地的类型的mov指令,当两边操作的是立即数和内存时,可以以立即数大小为准
- 所有mov指令都不支持从一个内存地址直接传到另一个内存地址,如
movw (%rax),4(%rsp)是不行的。 - 操作后的结果以将立即数$1传入%rax返回值寄存器为例:
movabsq $0x0011223344556677, %rax %rax=0x0011223344556677
//movabsq意为将64位数字的原码完全传入%rax,覆盖%rax
movb $-1,%al %rax=0x00112233445566FF
//movb是覆盖一个字节即2个16进制位
movw $-1,%ax %rax= 001122334455FFFF
//movw是覆盖一个字即4个二进制位
movl $-1,%eax %rax =00000000FFFFFFFF
//需要注意的是movl虽使用的是32位(2字),但是会将高4个字节置为0。这是x86_64为兼容32位而采用的惯例
movq $-1,%rax %rax = FFFFFFFFFFFFFFFF
- 当想将小的数据复制到大的目的地时,可以用movz或movs,前者代表用0填充高字节,后者代表用符号位填充高字节,后面还要加上两种转换数据的大小

寄存器操作的实例
void swap(long *xp,long *yp)
{
long t0=*xp;
long t1=*yp;
*xp=t1;
*yp=t0;
}
可被编译为
swap:
movq (%rdi),%rax
movq (%rsi),%rdx
movq %rdx,(%rdi)
movq %rax,(%rdi)
ret
指针、变量的复制和互相拷贝:
可以认为(%寄存器)变量代表寄存器内存储的是(虚拟)内存地址,%寄存器变量带表数据已经存入寄存器了

压入与弹出栈内存
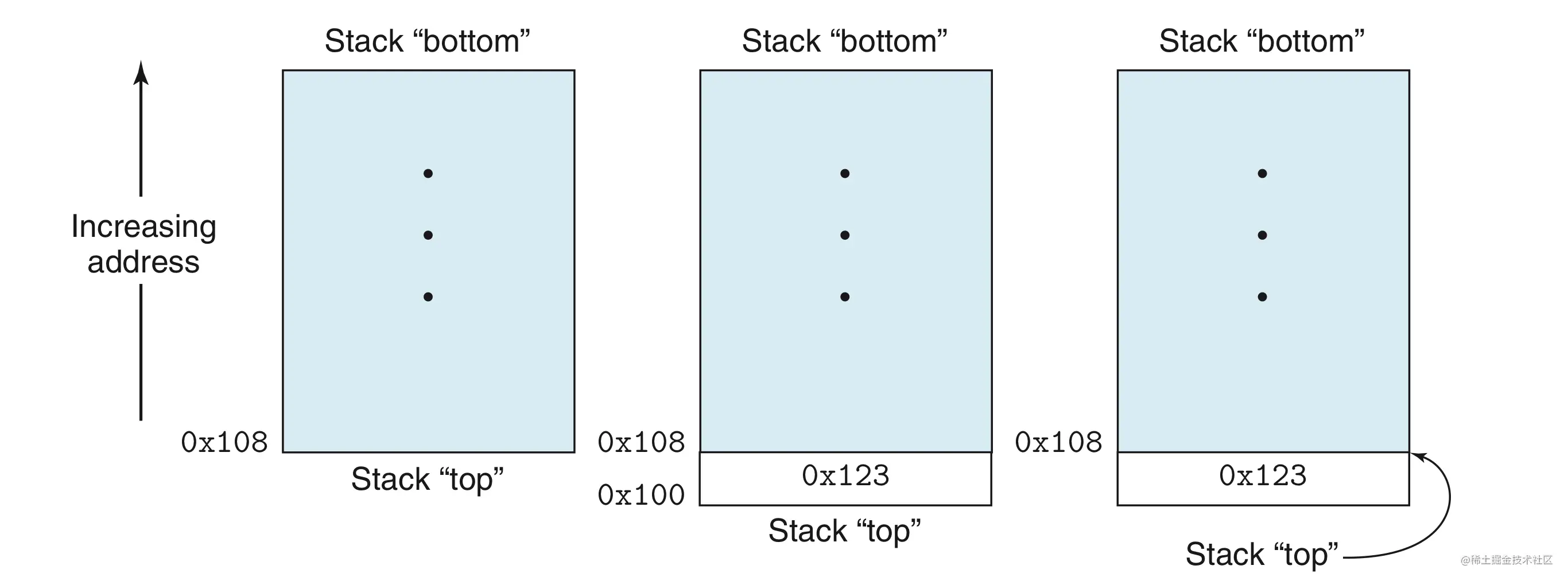
- 栈指针的寄存器代号(指针地址存储器)是%rsp
- 栈顶地址最低,因此我们把栈倒过来画
- pushq和popq的具体含义
-
- pushq相当于

subq $8,%rsp #rsp指针向下移动8位让出栈顶空间
movq %rbp,(%rsp) #将被调用者寄存器的内容调入栈中
- popq相当于
movq (%rsp),%rax #将栈顶内容传给返回值寄存器
addq $8,%rsp #栈地址上移8位以抹去栈顶
算术与逻辑操作

取地址
lea Src, Dst
- 将Src(地址模式表达式 )对应的地址保存到Dst中
- 它实际上是 movl 指令的变形。它的指令形式是从存储器读数据到寄存器,但实际上它根本没有引用存储器,而是将存储器有效地址写入操作数Dst,事实上就是把Dst作为Src的地址存储器。
- 若使用
lea(q) $S,Dst,则是将S作为地址存入Dst
一元和二元操作
所有操作在上表已经列出,其中一元操作是第二格,二元操作是第三格
所有一元操作都是oper a,a为寄存器或内存位置,被操作数为a位置内的数
所有二元操作都是oper a b的格式,第一个数可以是立即数、寄存器或内存位置,第二个必须是寄存器或者内存位置,其中若第二个是内存位置,需将数操作后写回内存
例子:

-
addq %rcx,(%rax)=在%rax的值上+0x1即0x100 -
subq %rdx,8(%rax)=在(%rax)+8=0x108地址上-0x3即0xA8 -
imulq $16,(%rax,%rdx,8)= 在0x100+8*0x3=0x118地址上*16即左移4位即得0x110关于其它三个位运算,详细计算过程详见位运算的相关计算
-
incq 16(%rax)让0x110位置内++1,即0x14 -
decq %rcx让rcx位置内–即0x0 -
subq %rdx,%rax在%rax位置内减去0x3即0xFD
移位
-
第一个操作数是移位量,SAL 和 SHL 都是左移指令,效果是一样的,移动几位,右边补上几位0;右移指令不同,算术右移 SAR 是补上符号位,即右边的第一位;逻辑右移 SHR 是补上 0 。
-
移位的目的操作数可以是一个寄存器或是一个存储器位置。
特殊算术

算术表达式的例子
long arith
(long x, long y, long z)
{
long t1=x+y;
long t2 =z+t1;
long t3 =x+4;
long t4=y*48;
long t5=t3+t4;
long rval=t2 *t5;
return rval;
}
arith:
leaq (%rdi,%rsi),%rax #t1的形成
addq %rdx,%rax #t2的形成,z已经无用可以使用%rdx
leaq (%rsi,%rsi,2),%rdx #将3y送入%rdx
salq $4,%rdx #t4的形成,将3y左移4位即乘以16
leaq 4(%rdi,%rdx),%rcx #t5=x+4+t4,t3和t5同时形成
imulq %rcx,%rax #rval=t2*t5
ret
控制
实现控制流的汇编代码,分为以下几类:
条件码
条件码是一系列单个位的寄存器,描述最近的算术或者逻辑操作的属性,检测这些寄存器执行条件分支指令。
最常用的条件码:
- CF,进位标志,最近的最高位产生进位,可用于检查无符号操作的溢出;
- ZF,零标志,最近的操作得出结果为0
- SF,符号标识,最近的操作得出结果为负(符号位1)
- OF,溢出标志,表示最近操作造成一次补码溢出
大部分运算操作都会改变条件码和寄存器,但亦会有少部分特殊的运算只设置条件码不改变(其它)寄存器,如下图所示:

其中:
-
cmp是S2-S1,但是不会把结果存进寄存器或者内存中,而是会根据计算结果是否为正动SF,是否溢出动OF,etc. 随后可以在使用条件码的地方判断(例如下面所说的访问条件码语句)
- cmpq b, a
- CF=1如果最高有效位有进位(无符号数比较)
- ZF=1如a==b
- SF=1如(a-b)<0(结果看做有符号数)
- OF=1如补码(有符号数)溢出
(a>0 && b<0 && (a-b)<0) || (a<0 && b>0 &&
(a-b)>0)
-
test与and类似(除了是条件码使用器,也是根据结果动条件码)
例子1:

该例子中,comq %rsi,%rdi返回ZF ,sete由ZF判断a-b==0即a==b,便将该结果作为boolean量输入%al
例子2:
int gt (long x, long y)
{ return x > y; }
cmpq %rsi, %rdi # Compare x:y
setg %al # Set when >
movzbl %al, %eax # Zero rest of %rax
ret
y在%rdi,x在%rsi,当x>y即~(SF^OF)&~ZF,setg 设置%al(返回值寄存器的低8位)为1,随后做逻辑扩展。
访问条件码
条件码的三种使用方法:
-
根据条件码的某种组合将一个字节设置为0或1;
-
条件跳转到程序的另外部分
-
有条件地传送数据
条件码组合改变字节
即SET指令,各种SET指令的差别在于其后缀也即需要考虑的条件码的组合。这些后缀均不代表寄存器长度。

- SET指令存在于那些可以更改条件码的指令的后面,这样就可以读取到最新的值了。
- 同义名,比如说setg(表示“设置大于”)和setnle(表示“不小于等于”)指的就是同一条机器指令,编译器和反编译器会随意决定使用哪个名字。
- 虽然所有的算术和逻辑操作都会设置条件码,但是各个SET命令的描述都适用的情况是:执行比较指令,根据计算t=a-b设置条件码。更具体地说,假设a、b和t分别是变量a、b和t的补码形式表示的整数,因此 t = a − w t b t=a -_{w}^{t} b t=a−wtb,这里w取决于a和6的大小。
可寻址的单字节寄存器
= 不改变寄存器其他字节的数值
= 常用指令 movzbl将单字节值零扩展至整个8字节寄存器
= 典例见上
条件跳转
跳转指令

注意跳转指令的跳转目标:
jmp *%rax->以%rax里的值为跳转目标
jmp *(%rax)->以%rax内的值为内存地址,跳转至该地址内值
条件控制、条件传送和条件分支
跳转指令的编码
movq %rdi, %rax #将%rdi内数据移动至返回值
jmp .L2 #跳转至.L2
.L3:
sarq %rax
.L2:
testq %rax, %rax #确定%rax存在
jg .L3
rep; ret
链接后的程序反汇编:
4004d0: 48 89 f8 mov %rdi,%rax
4004d3: eb 03 jmp 4004d8 <loop+0x8>
4004d5: 48 dl f8 sar %rax
4004d8: 48 85 c0 test %rax, %rax #8=
4004db: 7f f8 jg 4004d5 <loop+0x5>
4004dd: f3 c3 repz retq
对于如何确定跳转的位置,有多种方法,但是最常用的是PC相对法。这种方法会把目标指令的地址和紧跟在跳转指令后面的指令的地址的差值作为值编码在跳转指令后面。
在执行PC相对寻址时,程序计数器的值是跳转指令后面的那条指令的地址。
使用PC相对法进行编码,好处就是指令很简洁,而且目标代码可以不做修改就移植到别的机器上。
至于rep和repz指令,并没有实际用处,只是可以让AMD的U上的程序跑得更快,AMD自己说的,毕竟是AMD64(
条件分支
long absdiff
(long x, long y)
{
long result;
if (x > y)
result = x-y;
else
result = y-x;
return result;
}
可被编译为:
absdiff:
cmpq %rsi, %rdi #x:y比较
jle .L4 # 当符号数x<y跳转至.L4
movq %rdi, %rax #将x移入返回值
subq %rsi, %rax #x-y
ret
.L4: # x <= y
movq %rsi, %rax
subq %rdi, %rax #y-x
ret
其中:
- %rdi:参数 x
- %rsi:参数 y
- %rax:返回值
可以用goto表述
- C 允许使用goto语句
- 跳转到标号指定的位置
long absdiff_j(long x, long y)
{
long result;
int ntest = x <= y;
if (ntest) goto Else;
result = x-y;
goto Done;
Else:
result = y-x;
Done:
return result;
}
//其结构和汇编语句高度相似
条件传送
样式为:if (Test) Dest <–Src,具体指令如下:

1995年之后的 x86处理器均支持条件传送。
对于使用条件控制来实现条件转移,在现代处理器中可能会很低效。原因:
首先来看看为什么条件控制可能是低效的。现代处理器使用了称为流水线的处理结构,使得一个时钟周期内可以处理多条指令的不同阶段操作。但是这种高效率依赖于流水线的满载,如果流水线空荡荡的那反而是降低了性能。**于是需要CPU提前把指令填充到流水线,而有些指令没法提前填充,于是CPU使用它的预测算法,把那些未来的指令放到它可能被执行的流水线上。**但是!一旦放错了,后果开销更大,此时因为指令的跳转,需要清空流水线,重新载入新的指令。当代CPU可以做到90%准确率,不过有时如果输入偏于随机的话,那么性能就下来了。
但是条件传送不需要预测结果,因为所有的可能结果全部完成运算,仅仅在最后输出时选择一个正确的结果就好,这就把预测取消了。同时因为取消了预测,此时控制流与输入数据无关,流水线一直是满载。
作者:小白白白_
链接:https://juejin.cn/post/6855129008108273678
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
故GCC编译器一般使用此方法,但是是在保证安全的前提下1
一般条件表达式
以
//val=Test?Then_Expr:Else_Expr
val=x>y?x-y:y-x;
为例,可转换为goto语句样式
ntest=!Test;
if(ntest) goto Else;
val=Then_Expr;
goto Done;
Else:
val=Else_Expr;
Done:
……
从而被编译为上面已经有的形式
也可以在条件传送方法下以以下方式编译:
#x in %rdi,y in %rsi
absdiff:
movq %rsi,%rax
subq %rdi,%rax #rval=y-x
movq %rdi,%rdx
subq %rsi,%rdx #eval=x-y
cmpq %rsi,%rdi #compare x:y
cmovge %rdx,%rax #if(x>=y)rval=eval;else return rval
ret
由此也可以看出条件传送的优缺点:
-
优点:
-
一般情况下性能高于条件赋值状态
-
符合三元表达式的思维,但也可以用于if/else判断的编译,此时性能一般高于以条件赋值方式实现if/else
-
-
缺点:
-
因为条件传送指令将对两个表达式都求值,因此如果两个表达式计算量很大时,那么条件传送指令的性能就可能不如if/else的分支判断。
-
若出现危险或者有副作用的计算(即前一次计算结果会影响后一次)……
 2
2
-
循环
do-while
以以下例函数为例:
long fact_do(long n)
{
long result = 1;
do{
result *=n;
n=n-1;
} while (n > 1);
return result;
}
用goto转换就是
long fact_do(long n)
{
long result = 1;
loop:
result *=n;
n=n-1;
if(n>1)
goto loop;
return result;
}
也就是将断言t(这里是n>1)作为返回循环体的断言
# long fact_do(long n)
# n in %rdi
fact_do:
movl $1,%eax #set result=1
jmp .L5 #跳到判断部分
.L6
imulq %rdi,%rax #result*=n
subq $1,%rdi #n-=1
.L5
cmpq $1,%rdi #n与1比较
jg .L6 #若n-1>0则跳转至.L6
rep;ret
转化规律可总结为:
–>

while
以
long pcount_while
(unsigned long x) {
long result = 0;
while (x) {
result += x & 0x1;
x >>= 1;
}
return result;
}
为例。
-
法1:将while翻译为do-while,用do-while的格式去做

要实现此等方法需要使用-O1优化,goto等价如下:
long pcount_goto_dw
(unsigned long x) {
long result = 0;
if (!x) goto done;
loop:
result += x & 0x1;
x >>= 1;
if(x) goto loop;
done:
return result;
}
特点:初始条件守护循环的入口
- 法2:“中间跳转法”:

goto等价如下:
long pcount_goto_jtm
(unsigned long x) {
long result = 0;
goto test;
loop:
result += x & 0x1;
x >>= 1;
test:
if(x) goto loop;
return result;
}
循环体放在中间,判断体放在末尾
翻译为汇编即为:
特点:两个goto,第一个goto语句跳到test处启动循环
for
#define WSIZE 8*sizeof(int)
long pcount_for
(unsigned long x)
{
size_t i;
long result = 0;
for (i = 0; i < WSIZE; i++)
{
unsigned bit = (x >> i) & 0x1;
result += bit;
}
return result;
}
for语句的结构可以认为是四部分:
i=0:初始化(Init)i<WSIZE:循环条件测试(Test)i++:更新(Update)unsigned bit = (x >> i) & 0x1; result += bit;
循环体
故上述for语句可以此结构转换为while语句

long pcount_for_while
(unsigned long x)
{
size_t i;
long result = 0;
//初始化
i = 0;
//循环条件测试(Test)
while (i < WSIZE)
{
//循环体
unsigned bit = (x >> i) & 0x1;
result += bit;
//更新
i++;
}
return result;
}
进而可进一步转化为goto表示法
long pcount_for_goto_dw
(unsigned long x) {
size_t i;
long result = 0;
//初始化
i = 0;
/*以下内容为初始化判断,被优化删除
if (!(i < WSIZE))
goto done;
*/
loop:
{
//循环体
unsigned bit =(x >> i) & 0x1;
result += bit;
}
//更新
i++;
//循环条件测试
if (i < WSIZE)
goto loop;
done:
return result;
switch语句
思考:switch和if-else有什么不同?
汇编代码会考虑使用一种称为跳转表的数据结构来使switch语句实现更加高效,此时,跳转的时间复杂度和语句数目无关。
跳转表就像一个数组,索引是switch的索引值,数组值是代码块地址。这样就可以通过以switch值寻址数组的形式来完成控制跳转。
 以以下switch代码为例
以以下switch代码为例
void switch_eg(long x, long n,long *dest)
{
long val=x;
switch (n){
case 100:
val *= 13;
break;
case 102:
val+= 10;
/* Fall through */
case 103:
val += 11;
break;
case 104:
case 106:
val *=val;
break;
default:
val=0;
*dest = val;
}
}
转换goto形式即为
void switch_eg_impl(long x, long n,long *dest)
/* Table of code pointers */
static void *jt[7]={
&&loc_A,&&loc_def,&&loc_B,&&loc_C,&&loc_D,&&loc_def,&&loc_D
};
unsigned long index =n- 100;
long val;
if (index>6)
goto loc_def;
/* Multiway branch */
goto *jt[index];
/* Case 100 */
1oc_A:
val=x* 13;
goto done;
loc_B:
/* Case 102 */
x=X+10;
/* Fall through */
/* Case 103 */
loc_C:
val=x+ 11;
goto done;
/* Cases 104, 106 */
1oc_D:
val=x *x;
goto done;
loc_def: /* Default case */
val=0;
done:
*dest = val;
}
其可以转换为汇编
# void switch_eg(long x,long n,long *dest)
# x in %rdi,n in %rsi,dest in %rdx
switch_eg:
subq $100,%rsi
cmpq $6,%rsi
ja .L8
jmp *.L4(,%rsi,8)
.L3: #loc_A
leaq (%rdi,%rdi,2),%rax #3*x
leaq (%rdi,%rdx,4),%rdi #val=13*x
jmp .L2 #goto done
.L5: #loc_b
addq $10,%rdi #x+=10
.L6 #loc_c
addq $15,%rdi #val=x+11
jmp .L2 #goto done
.L7 #loc_d
imulq %rdi,%rdi #val=x*x
jmp .L2
.L8: #loc_def
movl $0,%edi #val=0
.L2:
movq %rdi,(%rdx) #*dest=val
ret
跳转表
该switch的跳转表为:

- 表结构
- 每个目标需8字节
- 基地址为.L4
- 跳转指令
- 直接跳转:jmp .L8
跳转到标号.L8处 - 间接跳转:jmp *.L4(,%rdi,8)
跳转表的起始地址:.L4 - 必须以8为比例因子 (地址是8字节)
- 0 ≤ x ≤ 6时,从有效地址.L4 + x*8处获取目标地址
- 直接跳转:jmp .L8
处理下穿(Fall-Through)
见上面.L2处。默认状态下,我们以break为一个case的终点,用其来跳转至共用终止点,但存在多个case共用一个语句,或者其它需要不停止的情况,则需要暂时不跳转。
过程
- 传递控制
- 调用:转到过程代码的起始处
- 结束:回到返回点
- 传递数据
- 过程参数
- 返回值
- 内存管理
- 过程运行期间申请
- 返回时解除分配
- 该机制全部由机器指令实现
x86-64 过程的实现只是使用了
这些机制
x86-64 栈
栈: 支持过程的调用、返回
过程调用
call func_label
- 返回地址入栈(Push)
- 跳转到func_label (函数名字就是函数代码段的起始地址)
long mult2
(long a, long b)
{
long s = a * b;
return s;
}
void multstore
(long x, long y, long *dest)
{
long t = mult2(x, y);
*dest = t;
}
–>>
注意以下代码中,每条命令前的16进制数值,为PC(程序计数器)的值
0000000000400550 <mult2>:
400550: mov %rdi,%rax
# a
400553: imul %rsi,%rax
# a * b
400557: retq
# Return
0000000000400540 <multstore>:
400540: push %rbx
# Save %rbx,将被被调用者保存寄存器里的数据入栈
400541: mov %rdx,%rbx
# Save dest
400544: callq 400550 <mult2>
# mult2(x,y)
400549: mov %rax,(%rbx)
# Save at dest
40054c: pop %rbx
# Restore %rbx
40054d: retq
返回地址
- 紧随call指令的下一条指令的地址 (考虑PC——RIP的含义)
- PC:程序计数器
- %rip:存储命令地址(程序计数器值)的寄存器
- 过程返回
ret
- 从栈中弹出返回地址(pop)
- 跳转到返回地址
控制流规律
- RIP寄存器存放着当前指令的地址
- 被调用者寄存器寄存函数用不上的数据(先把寄存器原有数据入栈)
- call 0x400550 时寻址0x400550即mult2(x,y)
- 将返回地址入(运行)栈
- jmp跳转至相应地址执行函数
- ret后将返回地址出栈
- 回到返回地址继续运行
数据传递
 数据流的实例:
数据流的实例:
0000000000400550 <mult2>:
# a in %rdi, b in %rsi
400550: mov %rdi,%rax
# a 进入返回值
400553: imul %rsi,%rax
# a * b
# s in %rax
400557: retq
# Return
0000000000400540 <multstore>:
# x in %rdi, y in %rsi, dest in %rdx
• • •
400541: mov %rdx,%rbx
# Save dest
400544: callq 400550 <mult2> # mult2(x,y)
# t in %rax
400549: mov %rax,(%rbx)
# Save at dest
栈帧
-
C语言的内存管理采用栈的结构,先进后出的顺序。程序可以通过这种方式来管理它所需要的存储空间,当P调用Q时,会把Q添加到栈顶,然后运行结束再释放。
-
机器用栈来传递过程参数、存储返回信息、保存寄存器用于以后恢复,以及本地存储。而为单个过程分配的那部分栈称为栈帧(stack frame)。
-
栈帧可以认为是程序栈的一段,它有两个端点,一个标识着起始地址,一个标识着结束地址,而这两个地址,则分别存储在固定的寄存器当中,即起始地址存在%ebp寄存器当中,结束地址存在%esp寄存器当中。也就是说寄存器 %ebp 为帧指针,寄存器 %esp 为栈指针。
-
当程序执行时,栈指针可以移动,因此大多数信息的访问都是相对于帧指针的。
-
每一个栈帧都建立在调用者的下方(也就是地址递减的方向),即栈朝低地址方向增长
-
因此如果我们将栈指针减去一定的值,就相当于给栈帧分配了一定空间的内存。这个理解起来很简单,因为在栈指针向下移动以后(也就是变小了),帧指针和栈指针中间的区域会变长,这就是给栈帧分配了更多的内存。
栈帧的整体分配:

一个栈帧分为两个部分:
- 当前栈帧:
- “参数建立” :把即将调用的函数所需参数入栈
- 局部变量:如果不能用寄存器实现,则将暂时不用的局部变量入栈,用时推出
- 保存的寄存器内容
- 旧栈帧指针 (可选)
- 调用者栈帧(运行栈帧)
- 返回地址:由call指令压入栈
- 本次调用的参数
栈帧的管理
- 进入过程时申请空间
- 生成代码——构建栈帧
- 包括call指令产生的push操作
- 当返回时解除申请
- 结束代码——清理栈帧
- 包括ret指令产生的pop操作
寄存器分配原理
寄存器是唯一被所有过程共享的资源
(虽然内存也是,但是每个过程都有自己独立的空间,所以不算共享,他们只是共享物理内存这个设备而已,设备里的东西不共享)。
为了防止P的寄存器被Q过程覆盖,x86-64规定了一组规则,把寄存器做了分类。根据惯例,寄存器%rbx, %rbp, %r12~%r15被划分成被调用者保存寄存器;而除了这几个寄存器,以及栈指针%rsp之外的寄存器,都是调用者保存寄存器。
- 被调用者寄存器:假如P调用了Q,那么被调用者保存寄存器要求Q对这几个寄存器(里面存储的是P的数据,在调用之前P会将必要的数据存入于此)进行保存,以便在返回到P时,这几个寄存器的值不变,返回到调用者之前,需恢复这些保存的值。
- 调用者寄存器要求P提前保存好相关的寄存器(P运行过程中使用的数据),因为Q可能会产生修改。
- 一般过程是P将数据存入被调用者保存寄存器,再由被调用者保存寄存器入栈
注意特殊寄存器%rax 、%r10 /11、%rbp、%rsp:
-
%rax
- 返回值
- 调用者保存
- 被调用过程可修改
-
%r10/11:
- 调用者保存的临时值
- 被调用过程可修改
-
%rbp:
被调用者保存并恢复,可用作栈顶指针
-
%rsp:
- 被调用者保存的特殊形式
- 在离开过程时,恢复为原始值(CALL之前的值)
递归的运作
以
/* Recursive popcount */
long pcount_r(unsigned long x) {
if (x == 0)
return 0;
else
return (x & 1) + pcount_r(x >> 1);
}
为例
# x in %rdi
pcount_r:
movl $0, %eax # 将返回值置0
testq %rdi, %rdi
je .L6 # 若x==0返回0
pushq %rbx # 将被调用者保存寄存器入栈
movq %rdi, %rbx # 将x调用者保存至被调用者保存寄存器
andl $1, %ebx # 被调用者保存寄存器里的x&=1
shrq %rdi # x>>1
call pcount_r # 自呼叫
addq %rbx, %rax # 将返回值加上x&1
popq %rbx # 被调用者保存以免被破坏
.L6:
rep; ret
从这个例子我们可以看到,递归调用一个函数本身与调用其他函数是一样的。
- 栈规则提供了一种机制,每次函数调用都有它自己私有的状态信息(保存的返回位置和被调用者保存寄存器的值)存储空间。
- 如果需要,它还可以提供局部变量的存储。栈分配和释放的规则很自然地就与函数调用-返回的顺序匹配。
- 这种实现函数调用和返回的方法甚至对更复杂的情况也适用,包括相互递归调用(例如,过程P调用Q,Q再调用P)。
- 例子:书3.32
数组的分配和访问
C语言的数组是一种将标量数据聚合成更大的数据类型的方式。
基本原则
T a[N]
- T 数据类型
- a 数组标识符,也为头指针的标识符
- xa 起始地址标识符
- L=sizeof(T) (单位字节),分配一个L*N的空间
- &a[i]=xa+L*i
- 假定xa在%rdx,下标在%rcx,数组元素长度4个字节(32位,l)
movl (%rdx,%rcx,4),%eax
指针运算
- 假设整型数组E的起始地址和整数索引i分别存放在寄存器%rdx和%rcx中。下面是一些与E有关的表达式。我们还给出了每个表达式的汇编代码实现,结果存放在寄存器%eax(如果是数据)或寄存器%rax(如果是指针)中。元素大小4字节。

嵌套的数组
 当我们创建数组的数组时,数组分配和引用的一般原则也是成立的。例如,声明 `int A[5][3];` 等价于下面的声明
当我们创建数组的数组时,数组分配和引用的一般原则也是成立的。例如,声明 `int A[5][3];` 等价于下面的声明
typedef int row3_t[3];
row3_t A[5];
数据类型row3_t被定义为一个3个整数的数组。数组A包含5个这样的元素,每个元素需要12个字节来存储3个整数。整个数组的大小就是4×5×3=60字节。
在C语言以及其它现代的高级语言中,嵌套的多维数组是行优先的,即&D[i][j]=x0+L(C*i+j),前一个数表达的是多少行,C为每行列数。
行访问
int *get_pgh_zip(int index){ return pgh[index]; }
# %rdi = index
leaq (%rdi,%rdi,4),%rax # 5 * index
leaq pgh(,%rax,4),%rax # pgh + (20 * index)
元素访问
int get_pgh_digit(int index, int dig) { return pgh[index][dig]; }
leaq (%rdi,%rdi,4), %rax # 5*index
addl %rax, %rsi # 5*index+dig
movl pgh(,%rsi,4), %eax # M[pgh + 4*(5*index+dig)]
综合判断
 M=5,N=7,后两条分别为Memory[&Q+8(i+5j)]->ret和Memory[&P+8(7i+j)]
M=5,N=7,后两条分别为Memory[&Q+8(i+5j)]->ret和Memory[&P+8(7i+j)]
多于二维的数组
变长数组
要理解定长和变长数组,我们必须搞清楚一个概念,就是说这个“定”和“变”是针对什么来说的。在这里我们说,这两个字是针对编译器来说的,也就是说,如果在编译时数组的长度确定,我们就称为定长数组,反之则称为变长数组。
定长数组的优化
编译器会进行自动的优化。
主要优化方法是将乘法改为连续寄存器上加法,以及用指针操作代替每次都要计算数组元素的地址。这在循环里尤为明显,如

在N*N矩阵的访问过程中,当N为2的倍数,可以实现用移位替代乘法进而实现访问的快速
变长数组的处理
在C99标准和其它高级语言中,变长数组是被支持的.
变长数组由于在数组创建时才知道数组大小,因而在低等级编译选项里难以实现优化。高等级编译选项可以提前知道程序访问多维数组的元素的步长并试图优化。
异质数据结构的使用
struct
所有的组成部分在存储器中连续存放,字段顺序必须与声明一致!,指向结构的指针指向结构的第一个字节。机器级程序不理解结构体,结构体在汇编中是以整体存取的相邻变量形式展现

结构体成员地址的生成
struct rec {
int a[4];
size_t i;
struct rec *next;
};//这是一个链表
int *get_ap (struct rec *r,size_t idx) {
return &r->a[idx];
}
# r in %rdi, idx in %rsi
leaq (%rdi,%rsi,4), %rax #r+4idx
ret
-
每个结构体成员的偏移量(Offset)是在编译阶段确定的
-
地址计算形式: r + 4*idx
链表的处理
void set_val (struct rec *r, int val){
while (r) {
int i = r->i;
r->a[i] = val;
r = r->next; //链表指针后移动的基本操作
}
}
#r in %rdi
.L11 #loop
movslq 16(%rdi), %rax # i = M[r+16]
movl %esi,(%rdi,%rax,4) # M[r+4*i] = val ,即val=r->a[i]
movq 24(%rdi),%rdi # r = M[r+24],结构体指针移动
testq %rdi,%rdi # r==null ?
jne .L11 #if r!=null goto loop
联合
允许以多种类型来引用一个对象,总大小等于它最大字段的大小,而指向一个联合的指针,引用的是数据结构的起始位置。

数据对齐
x86-64系统对齐要求为:对于任何需要K字节的标量数据类型的起始地址必须是K的倍数。汇编.align 8要求后面的数据起始位置是8的倍数。结构体的对齐除了要满足每个字段的对齐要求,还需要考虑整体的结构满足怎样的对齐要求。
编译器对齐的方式:在结构体中插入空白为确保字段正确对齐。


指针和内存
理解指针
- 指针是一种特殊的值,包含类型和地址两个部分
如int *ip,ip是指向int对象的指针,&ip的值在汇编中用leaq Dip,S表示
注意char **cpp,指代的是指向*cpp的指针,即多维指针 - 指针用&运算符创建和取内存值,用*取值
- 数组和指针紧密联系,数组的名字可以当指针用
- 指针的类型转换不改变(地址和内容)值
- 指针也可以指向函数,代表函数的程序计数器地址
✖86_64Linux内存分配机制

char big_array[1L<<24]; /* 16 MB */
char huge_array[1L<<31]; /* 2 GB */
int global = 0;
int useless() { return 0; }
int main ()
{
void *p1, *p2, *p3, *p4;
int local = 0;
p1 = malloc(1L << 28); /* 256 MB*/
p2 = malloc(1L << 8); /* 256 B */
p3 = malloc(1L << 32); /* 4 GB */
p4 = malloc(1L << 8); /* 256 B */
/* Some print statements ... */
}
//程序中各个部分都在哪里?

内存越界引用和缓冲区溢出
typedef struct {
int a[2];
double d;
} struct_t;
double fun(int i) {
volatile struct_t s;
s.d = 3.14;
s.a[i] = 1073741824; /* Possibly out of bounds */
return s.d;
}
为例:
fun(1) =3.14
fun(2) = 3.1399998664856
fun(3) = 2.00000061035156
fun(4) = 3.14
fun(6) = Segmentation fault(段错误)

以上现象称作缓冲区溢出,当超出数组分配的内存大小(范围),
原因包括:
- 程序设计中未给缓冲区(如数组的内存)提供足够空间
- 用户无知的情况下输入大于缓冲区大小的值
- 字符串输入不检查长度
- 特别是堆栈上的有界字符数组
- C语言的字符串函数多有不限制字符串输入字符串长度大小的问题,使得C系语言成为字符串堆栈溢出的高发区
- 例:gets漏洞
char *gets(char *dest){
int c = getchar();
char *p = dest;
while (c != EOF && c != '\n'){
*p++ = c;
c = getchar();
}
*p = '\0';
return dest;
}
缓冲区溢出的“应用”
- 代码注入攻击
- 输入字符串包含可执行代码的字节序列!
- 将返回地址 A用缓冲区B的地址替换
- 当Q执行ret后,将跳转到B处,执行漏洞利用程序(exploit code)
- 基于缓冲区溢出的漏洞利用程序
- 缓冲区溢出错误允许远程机器在受害者机器上执
行任意代码。
- 缓冲区溢出错误允许远程机器在受害者机器上执
- 经典案例
- 原始"互联网蠕虫"(Internet worm),1988
- 即时通讯战争"IM wars",1999
- Twilight hack on Wii, 2000s(不改动硬件,直接在Wii上运
行自制程序)
缓冲区溢出的应对
输入限制
- 例如,使用限制字符串长度的库例程
- fgets 代替gets
- strncpy 代替strcpy
- 在scanf函数中别用%s
- 用fgets读入字符串
- 或用 %ns代替%s,其中n是一个合适的整数
系统级防护
- 随机的栈偏移
- 程序启动后,在栈中分配随机数量的空间
- 将移动整个程序使用的栈空间地址
- 黑客很难预测插入代码的起始地址
- 例如:执行5次内存申请代码,每次程序执行,栈都重新定位
- 非可执行代码段
- 在传统的x86中,可以标记存储区为“只读”或“可写的”
- 可以执行任何可读的操作
- x86-64添加显式“执行”权限
- 将stack标记为不可执行
- 在传统的x86中,可以标记存储区为“只读”或“可写的”
栈金丝雀(Stack Canaries)
- 在栈中buffer之后的位置放置特殊的值——金丝雀
(“canary”) - 退出函数之前,检查是否被破坏
gcc -fstack-protector(现在默认开启)
黑客的应对措施
替代策略
- 使用已有代码
- 例如:stdlib的库代码
- 将片段串在一起以获得总体期望的结果。
- 不用克服栈金丝雀


















 3097
3097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











