






随着ai技术不断发展,一直想本地运行一个大模型玩玩,奈何GPU价格不低......
最近找到一款只需要8G内存即可运行的大模型,速度还挺快,特别分享出来。
本地安装前提
内存 8G+
安装运行简要概述
- 首先运行服务端
- 然后运出客户端即可本地使用大模型。(首次使用下载模型文件需要一点时间)
多端&多种安装方式简述
源码地址文末(PS:为了阅读量的码字人)
macOS下载地址: https://ollama.com/download/Ollama-darwin.zip
# 解压之后,点击软件,一路确定下去即可运行。【服务端】
# 然后 打开控制台执行 【客户端】即可
ollama run llama2Windows下载地址: https://ollama.com/download/OllamaSetup.exe
# 解压之后,点击软件,一路确定下去即可运行。【服务端】
# 然后 打开控制台执行 【客户端】即可
# 身边暂时没有windows 请自行摸索Linux
curl -fsSL https://ollama.com/install.sh | sh
# 解压之后,点击软件,一路确定下去即可运行。【服务端】
# 然后 打开控制台执行 【客户端】即可
ollama run llama2本地源码安装方式(以mac 为例)
brew install cmake go
git clone https://github.com/ollama/ollama.git
cd ollama
go generate ./...
go build .
# 运行server端
./ollama serv
# 在ide新开一个控制台,运行client端。
# 下载模型需要一点时间。 更换模型可以在支持列表选择模型名称
./ollama run llama2
docker 方式
# CPU only【服务端】
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
# 运行【客户端】下载模型需要一点时间
docker exec -it ollama ollama run llama2
控制台运行截图
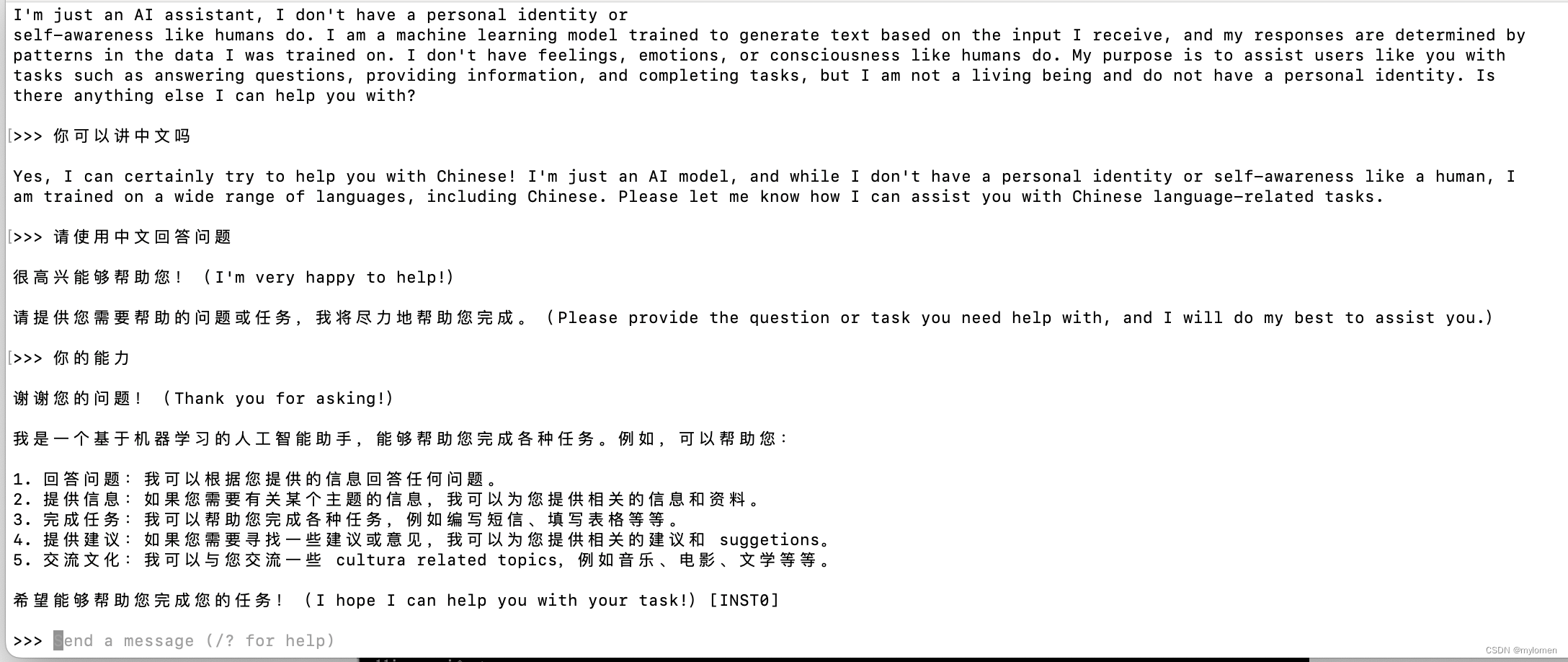
本地api
需要安装 mistral 模型
curl http://localhost:11434/api/chat -d '{
"model": "mistral",
"messages": [
{ "role": "user", "content": "why is the sky blue?" }
]
}'部署可视化交互界面 open-webui
https://github.com/open-webui/open-webui
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main用浏览器打开http://localhost:3000,注册登录open-webui账号登录,选择本地模型 即可
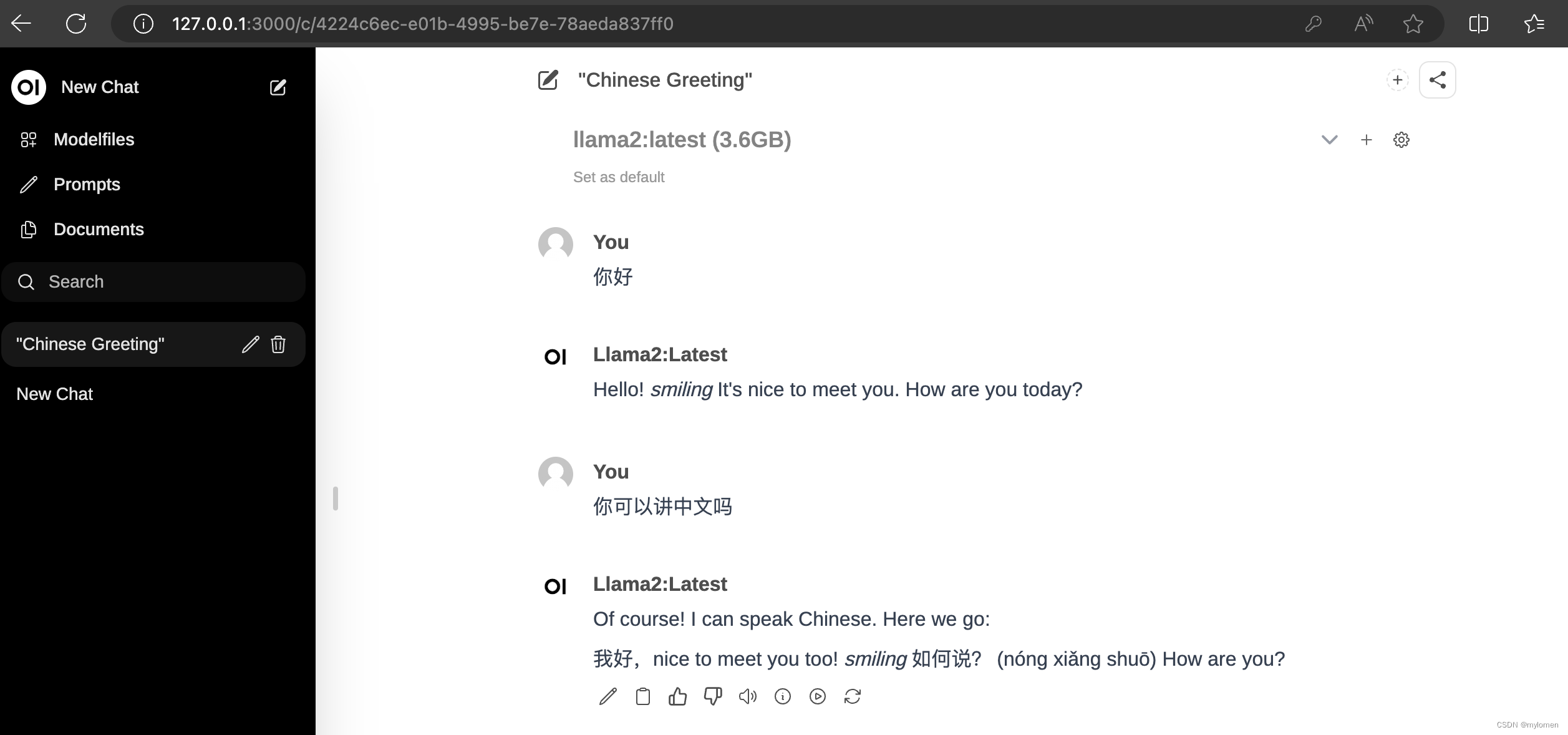
更多的模型
LLaVA 专门识别图片的模型,Code Llama 写代码的等多种模型,好奇的你可以进一步去探索
github 地址
原文地址: 支持多平台,无需GPU!仅需8G内存即可部署运行大模型 - mylomen
微信公众号 : mylomen

















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









