







 本文介绍了使用Python实现K-nearest neighbors (K-nn)算法进行手写数字识别的过程。通过计算测试数据与训练数据的欧式距离,确定最近的k个邻居,并根据出现频率最高的类别进行预测。实验结果显示,该方法具有较高的正确率。
本文介绍了使用Python实现K-nearest neighbors (K-nn)算法进行手写数字识别的过程。通过计算测试数据与训练数据的欧式距离,确定最近的k个邻居,并根据出现频率最高的类别进行预测。实验结果显示,该方法具有较高的正确率。
模式识别的实验作业,弄了一个晚上终于在第二天中午弄明白了!
简单来说,k-nn就是通过计算训练集和 一个测试数据之间的欧式距离,然后将计算结果按照从小到大来排序,找出最小的k个数据,分析k个数据中哪种情况出现的频率最多,那么这个测试数据就属于这一类
思路
读入数据,假设100个训练数据,将训练数据转换为100*1024的二维数组,然后循环读入测试数据,计算测试数据和100个训练数据间的欧式距离:
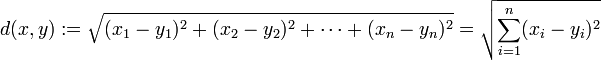
x1-xn为单个训练数据的所有元素,y1-yn为测试数据的所有元素这样就得到一个数组,包含所有训练数据和测试数据的欧式距离,将距离从小到大进行排序。
3. 结果
找出k个最近的距离,看哪个数字出现的频率最多,那么这个测试数据大概率为这个数字
#解压文件
def JY():
path="/Users/fanjialiang2401/Pycha 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









