







背景和文章思想
这篇论文考虑的是Non-IID场景下的联邦学习,传统的联邦学习在Non-IID数据集上的表现比IID数据集上的表现要差很多,而且收敛速度也要慢很多。这篇文章便旨在通过对梯度的挑选来实现收敛速度的提升,但是与我们所知的机制不同的是,后者是有一个确定的策略去选梯度,但是前者的思路是使用深度强化学习方法来“学习”梯度的挑选方式
深度强化学习概述
深度强化学习,Deep Reinforcement Learning(DRL)目的是为了训练一个代理器agent,该agent在某个状态 s t s_t st下执行策略 a t a_t at会得到一个奖励 r t r_t rt,训练的目的便是使得总奖励最高,也就是 a g e n t agent agent在某个状态 s t s_t st能够寻则最优的策略 a t a_t at进行执行,agent在状态 s t s_t st执行选择的策略之后跳到状态 s t + 1 s_{t+1} st+1,并且总的奖励会由一个折扣系数 γ ∈ ( 0 , 1 ] \gamma \in (0,1] γ∈(0,1]控制,最后的奖励计算公式为 R = ∑ t = 1 T γ t − 1 r t R = \sum_{t=1}^T \gamma^{t-1}r_t R=∑t=1Tγt−1rt
该算法会维持一张表,记录值函数 Q ( s t , a t ) Q(s_t,a_t) Q(st,at)的值,其中该值函数的计算方式为:

其中
π
\pi
π表示的便是策略,而最优的策略便可以由下面这条个公式表示:
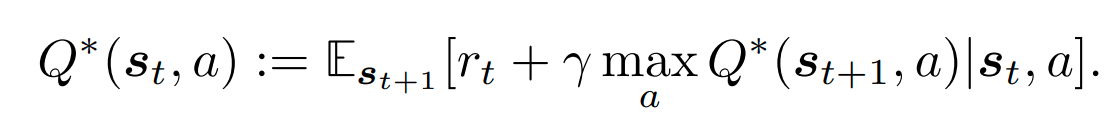
其实就是用贪心去选择奖励最大的策略,
DRL For Client Selection
下面讲的便是这篇论文的核心:如何用DRL去学习一个梯度的选择策略
State
这里的状态 s t s_t st表示为 s t = ( w t , w t ( 1 ) , . . . , w t ( N ) ) s_t = (w_t,w_t^{(1)},...,w_t^{(N)}) st=(wt,wt(1),...,wt(N)),其中第一个 w t w_t wt表示的是全局模型,后面的 w t ( 1 ) , . . . , w t ( N ) w^{(1)}_t,...,w^{(N)}_t wt(1),...,wt(N)表示的是 N N N个client上的模型
Action
这里的值函数表示为 Q ∗ ( s t , a ) Q^*(s_t,a) Q∗(st,a),其中 a = i ∈ { 1 , 2 , . . . , N } a = i \in \{1,2,...,N\} a=i∈{1,2,...,N}表示第 i i i个client被选择进行全局聚合,在每个round都会对 N N N个client都计算一次值函数,然后挑选 k k k个值最高的client进行全局聚合
Reward
在这里 r t r_t rt表示为 r t = Ξ ( w t − Ω ) r_t = \Xi^{(w_t-\Omega)} rt=Ξ(wt−Ω),其中 t = 1 , . . . , T t = 1,...,T t=1,...,T, w t w_t wt表示全局模型的准确率, Ω \Omega Ω表示目标准确率, Ξ \Xi Ξ是一个正常数,用来保证 r t r_t rt的指数增长,由于 0 ≤ w t ≤ Ω ≤ 1 0 \leq w_t\leq \Omega\leq 1 0≤wt≤Ω≤1,因此 r t ∈ ( − 1 , 0 ] r_t \in (-1,0] rt∈(−1,0],算法在 w t = Ω w_t = \Omega wt=Ω停止
因此总奖励的计算方式为:
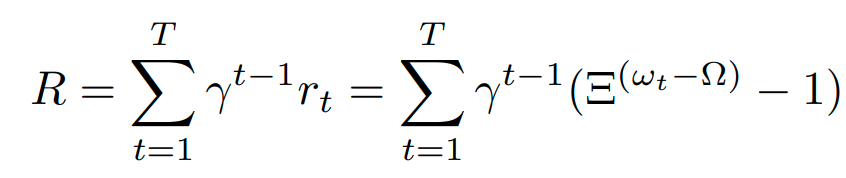
其中
γ
\gamma
γ是一个未来衰减因素
算法流程

对上面过程进行翻译如下:
- 第一步,随机初始化随机模型 w i n i t w_{init} winit
- 第二步,每个client下载模型,本地训练模型,上传模型
- 第三步,服务器收到client上传的模型之后更新服务器上的模型备份,并且对于每一个client a a a,计算值函数 Q ( s t , a ; θ ) Q(s_t,a;\theta) Q(st,a;θ)的值
- 第四步,agent选择K个值函数值最大的client下载最新的全局模型,然后i进行一个epoch的SGD训练,然后上传到服务器上,服务器得到 { w t + 1 ( k ) ∣ k ∈ [ K ] } \{w_{t+1}^{(k)}|k \in [K]\} {wt+1(k)∣k∈[K]}
- 服务器用 { w t + 1 ( k ) ∣ k ∈ [ K ] } \{w_{t+1}^{(k)}|k \in [K]\} {wt+1(k)∣k∈[K]}来更新全局模型,并重复第三步到第五步
算法流程图:

实验

红色曲线是FedAvg算法在IID数据集的表现,紫色曲线是FedAvg算法在Non-IID数据集的表现,蓝色曲线是该文章提出的方法在Non-IID数据集的表现(单看结果的话好像效果一般?)
结论
该文章提出的方法比较具备启发性,并且研究的方向也是比较创新。在客户端选择这一研究方向很多文章都是在资源假设的前提下做的,他们的目的是研究怎么去选梯度能够在花费最少资源的情况下得到ACC最高的模型。这篇文章研究的是怎么在Non-IID的场景下去选择恰当的客户端使得收敛更加快,这种工作相对会比较少一些。
然后这篇文章的一个亮点是,它并没有制定一个明确的挑选策略,而是引入一个深度强化学习的方法,让一个agent去学习一个恰当的挑选策略,这种方法的好处是可能会有效,因为实验结果表明它有效,最好可以将收敛时间降低49%(我看了一下应该是模型ACC达到96%时候的情况,但这时候模型还没到收敛呢…),缺点是我们不知道它为什么有效。我觉得更有意义的工作可能需要深入研究一下背后梯度挑选对于模型收敛的影响















 2619
2619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









