







本文是《图解Spark核心技术与案例实战》一书的读书笔记,简单讲解了Spark Shuffle的相关内容。
Shuffle 介绍
shuffle 在spark 中是连接不同stage的桥梁,连续的若干个算子如果不涉及到shuffle操作,那么就可以作为一个stage使用流水线的方式执行,不用生成和读取中间结果,提高速度。而shuffle就是前一个stage输出中间结果和后一个stage读取中间结果的过程。
Spark DAG中存在宽依赖和窄依赖,所谓宽依赖,就是父RDD分区被多余一个子RDD分区依赖,窄依赖就是父RDD分区被至多一个子RDD分区依赖。宽依赖则需要将父RDD上的所有分区的数据汇聚到下一个任务运行的结点进行执行,这个数据传输的过程称为shuffle,而父RDD输出结果的过程称为shuffle写,子RDD读取中间结果的过程称为shuffle读。接下来使用经典的map reduce模型讲解spark 的shuffle 操作。
shuffle 写
HashShuffle写
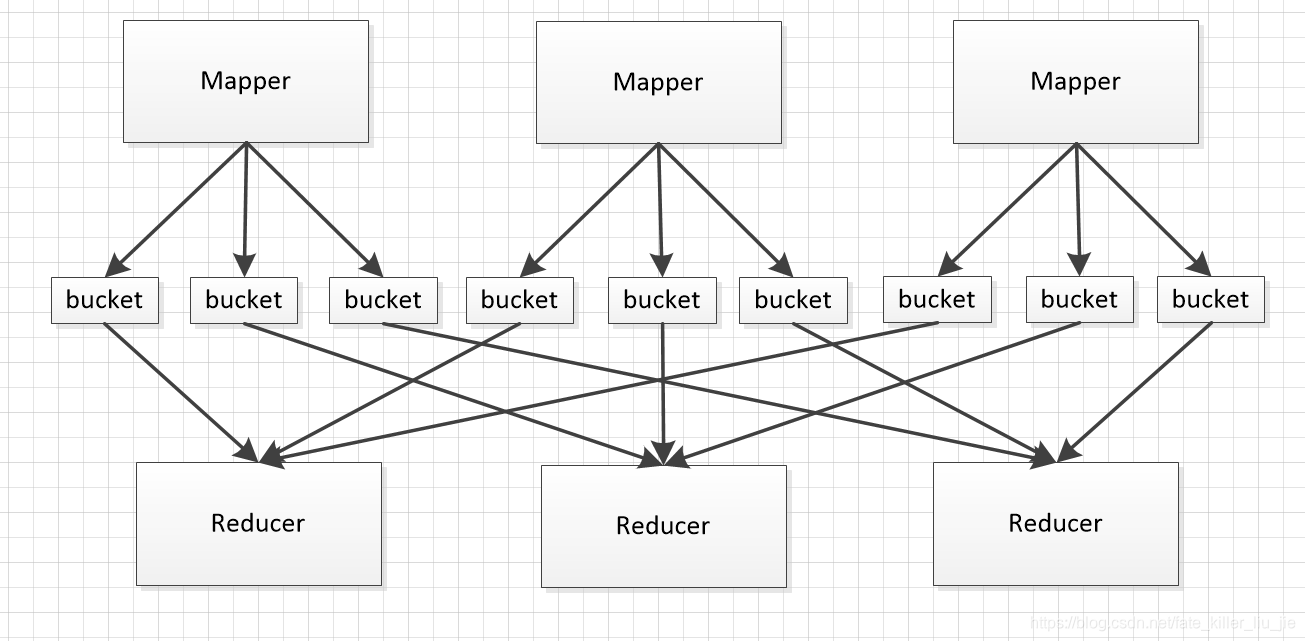
spark 在早期的版本提供了HashShuffle写的方法,Hash Shuffle机制中每个Map会根据reducer的数量创建出对应个bucket,然后将mapper 输出的数据写入到bucket中,这样假设有M个Mapper,R个Reducer,那么一共会有M*R个bucket,具体如图所示:
接下来看看源代码:
在任务执行的最后,调用了getWriter方法,这个方法在Spark1.2之前默认通过反射获取到的是HashShuffleWriter
override def runTask(context: TaskContext): MapStatus = {
……
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
return writer.stop(success = true).get
} catch {
……
}
}
HashShuffleWriter的write方法,首先判断了shuffleDependence是否定义了aggregator,然后判断是否聚合的操作要在map端做,进而判断是否要调用combineValuesByKey,最后计算每个element的bucketid 调用ShuffleWriterGroup的方法进行写入
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
// 是否定义了aggregator
val iter = if (dep.aggregator.isDefined) {
// 如果在map 端聚合
if (dep.mapSideCombine) {
dep.aggregator.get.combineValuesByKey(records, context)
} else {
// 如果在reduce 端聚合
records
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
records
}
for (elem <- iter) {
// 对每个element计算bucketid
val bucketId = dep.partitioner.getPartition(elem._1)
// 调用shuffleWriterGroup的write方法写入
shuffle.writers(bucketId).write(elem._1, elem._2)
}
}
ShuffleWriterGroup通过forMapTask获得
/**
* Get a ShuffleWriterGroup for the given map task, which will register it as complete
* when the writers are closed successfully
*/
def forMapTask(shuffleId: Int, mapId: Int, numBuckets: Int, serializer: Serializer,
writeMetrics: ShuffleWriteMetrics): ShuffleWriterGroup = {
new ShuffleWriterGroup {
shuffleStates.putIfAbsent(shuffleId, new ShuffleState(numBuckets))
private val shuffleState = shuffleStates(shuffleId)
private var fileGroup: ShuffleFileGroup = null
val openStartTime = System.nanoTime
val serializerInstance = serializer.newInstance()
// 判断是否使用consolidateShuffleFiles策略
val writers: Array[BlockObjectWriter] = if (consolidateShuffleFiles) {
fileGroup = getUnusedFileGroup()
Array.tabulate[BlockObjectWriter](numBuckets) { bucketId =>
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
blockManager.getDiskWriter(blockId, fileGroup(bucketId), serializerInstance, bufferSize,
writeMetrics)
}
} else {
Array.tabulate[BlockObjectWriter](numBuckets) { bucketId =>
//获取块id
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
// 创建输出文件
val blockFile = blockManager.diskBlockManager.getFile(blockId)
// Because of previous failures, the shuffle file may already exist on this machine.
// If so, remove it.
if (blockFile.exists) {
if (blockFile.delete()) {
logInfo(s"Removed existing shuffle file $blockFile")
} else {
logWarning(s"Failed to remove existing shuffle file $blockFile")
}
}
// 创建文件writer
blockManager.getDiskWriter(blockId, blockFile, serializerInstance, bufferSize,
writeMetrics)
}
}
// Creating the file to write to and creating a disk writer both involve interacting with
// the disk, so should be included in the shuffle write time.
writeMetrics.incShuffleWriteTime(System.nanoTime - openStartTime)
……
}
}
上面的代码来自1.4.0版本,对HashWriter进行了一点优化,就是可以开启spark.shuffle.consolidateFiles,使得shuffle write产生的中间文件可以复用,优化的思路是这样的,原先是每个map task 会为下游的reduce task 创建m*r个文件,现在假如有100个map task,50个reduce task,未优化的时候创建5000个文件,优化之后使得不同时间使用同一个核执行的task可以复用之前的文件,那么假设现在有10个核,然后100个map的task只有10个创建了文件,后面的都是复用之前的,这10个map task每个创建50个文件,一共创建了500个文件,文件数量少了10倍。
sort shuffle writer
sort shuffle writer 可以看成是consolidateFiles之后的进一步优化,hash shuffle writer的主要弊端是产生的临时文件太多,那么sort shuffle 就使得相同的shuffle map task 公用一个输出文件,然后创建一个索引文件对这个文件进行索引。
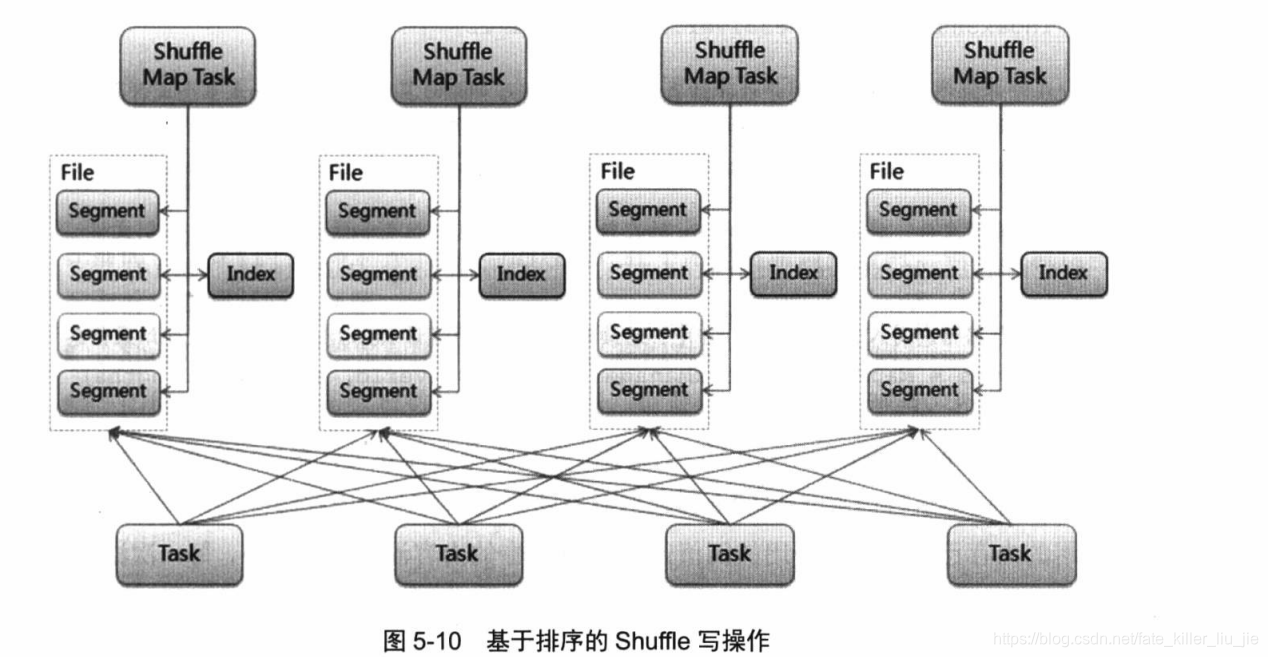
SortShuffleWriter的write方法:
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
// 是否需要在map 端聚合
if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
// 使用外部排序聚合
sorter = new ExternalSorter[K, V, C](
dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
sorter.insertAll(records)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
// 在这种情况下我们既不将聚合函数也不将排序传递给排序器,因为我们不关心是否每个分片
// 是否有序,因为假如运行的是的sortByKey,那么在reduce 端会排好序
sorter = new ExternalSorter[K, V, V](None, Some(dep.partitioner), None, dep.serializer)
// 将Map的内容写入到磁盘
sorter.insertAll(records)
}
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
// 通过shuffle编号和map编号获取文件
val outputFile = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
// 获取shuffle block 编号
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
// 将所有加入了外部排序的数据写入到磁盘组成一个文件
val partitionLengths = sorter.writePartitionedFile(blockId, context, outputFile)
// 创建索引文件,将每个partition的起始位置和结束为止写入到索引文件中
shuffleBlockResolver.writeIndexFile(dep.shuffleId, mapId, partitionLengths)
// 将输出的元信息写入到mapStatus,供之后的流程读取
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
}
insertAll()函数:
def insertAll(records: Iterator[_ <: Product2[K, V]]): Unit = {
// TODO: stop combining if we find that the reduction factor isn't high
val shouldCombine = aggregator.isDefined
// 是否需要合并
if (shouldCombine) {
// Combine values in-memory first using our AppendOnlyMap
// 首先在内存中使用AppendOnlyMap合并
val mergeValue = aggregator.get.mergeValue
val createCombiner = aggregator.get.createCombiner
var kv: Product2[K, V] = null
// 按key 合并
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
addElementsRead()
kv = records.next()
map.changeValue((getPartition(kv._1), kv._1), update)
// 如果超过了内存存放的阈值,那么溢写到磁盘中
maybeSpillCollection(usingMap = true)
}
// 这里是当numPartitions <= bypassMergeThreshold时,不需要本地排序,直接将
// 数据写入到文件,避免多次序列化和反序列化
} else if (bypassMergeSort) {
// SPARK-4479: Also bypass buffering if merge sort is bypassed to avoid defensive copies
if (records.hasNext) {
spillToPartitionFiles(
WritablePartitionedIterator.fromIterator(records.map { kv =>
((getPartition(kv._1), kv._1), kv._2.asInstanceOf[C])
})
)
}
} else {
// Stick values into our buffer
// 不需要聚合,那么数据排序之后放入缓冲区
while (records.hasNext) {
addElementsRead()
val kv = records.next()
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
maybeSpillCollection(usingMap = false)
}
}
}
shffle 读
针对hash shuffle写操作和sort shuffle 写,对应的有hash shuffle 读和sort shuffle 读。shuffle读的流程图:
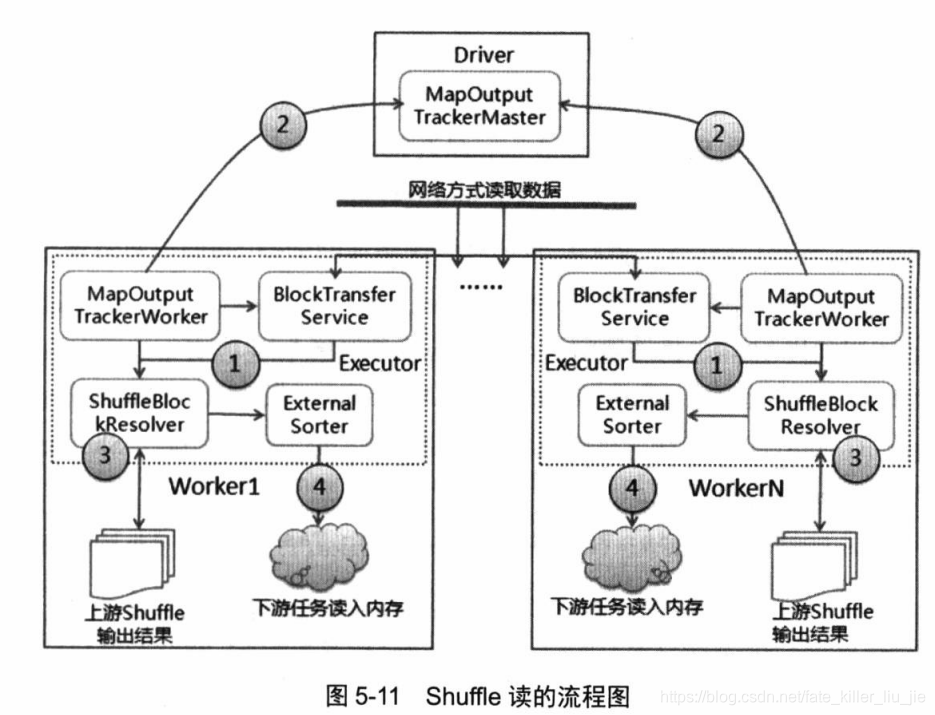
在程序启动的时候,会实例化ShuffleManager,BlockManager,MapOutputTracker,其中ShuffleManager有三种,HashShuffleManager,SortShuffleManager,自定义的ShuffleManager,其中HashShuffleManager会实例化一个FileShuffleBlockResolver,SortShuffleManager实例化一个IndexShuffleBlockResolver,通过这种方式来针对不同的写入方式使用不同的读取方式。
选择了正确的读取方式之后,还要获取到需要读取的数据的位置信息,例如数据所在的节点,executor的编号等等,通过对之前存储架构的了解,这些需要和Driver进行交互获得。读取数据的入口是在ShuffleRDD的compute方法里面,接下来调用了getReader()返回了BlockStoreShuffleReader,在其read方法里面进行了数据的读取,BlockStoreShuffleReader方法里面调用了mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition),来根据shuffleId 获取MapStatus,这个是通过trackerEndpoint.askWithRetry[T](message)这个调用实现的,而这个方法是给位于DriverEndpoint上面的MapOutputMaster发送消息,获取MapStatus之后就可以共MapStatus中解析出数据的存放位置,进而选择本地读取或者通过Netty远程读取。
读取之后就根据是否需要聚合以及在map端聚合还是reduce端聚合选择combineCombinersByKey还是combineValuesByKey
具体流程如下:
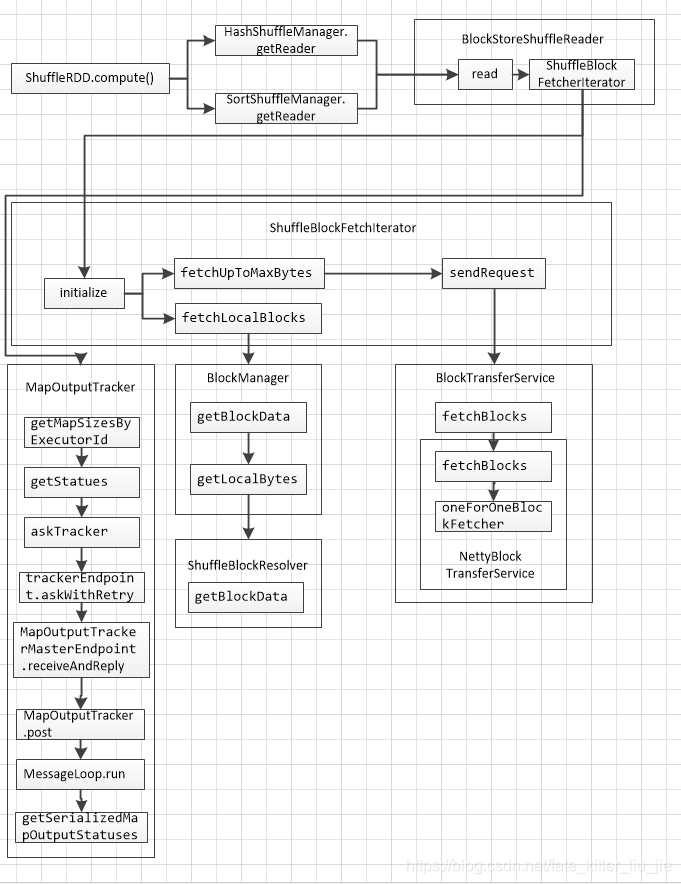
接下来看看源代码,首先是入口的compute()函数:
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
// 两种实现返回的都是BlockStoreShuffleReader
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}
BlockStoreShuffleReader的read方法,读取和读取之后的处理,首先看实例化ShuffleBlockFetcherIterator这个对象,在里面的getMapSizesByExecutorId首先获取了数据的存储位置信息
/** Read the combined key-values for this reduce task */
override def read(): Iterator[Product2[K, C]] = {
val blockFetcherItr = new ShuffleBlockFetcherIterator(
context,
blockManager.shuffleClient,
blockManager,
// 获取数据的存储信息
mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition),
……
}
getMapSizesByExecutorId嵌套调用了getStatues
/**
* Get or fetch the array of MapStatuses for a given shuffle ID. NOTE: clients MUST synchronize
* on this array when reading it, because on the driver, we may be changing it in place.
*
* (It would be nice to remove this restriction in the future.)
*/
private def getStatuses(shuffleId: Int): Array[MapStatus] = {
val statuses = mapStatuses.get(shuffleId).orNull
if (statuses == null) {
logInfo("Don't have map outputs for shuffle " + shuffleId + ", fetching them")
val startTime = System.currentTimeMillis
var fetchedStatuses: Array[MapStatus] = null
fetching.synchronized {
// Someone else is fetching it; wait for them to be done
while (fetching.contains(shuffleId)) {
try {
fetching.wait()
} catch {
case e: InterruptedException =>
}
}
// Either while we waited the fetch happened successfully, or
// someone fetched it in between the get and the fetching.synchronized.
fetchedStatuses = mapStatuses.get(shuffleId).orNull
if (fetchedStatuses == null) {
// We have to do the fetch, get others to wait for us.
fetching += shuffleId
}
}
if (fetchedStatuses == null) {
// We won the race to fetch the statuses; do so
logInfo("Doing the fetch; tracker endpoint = " + trackerEndpoint)
// This try-finally prevents hangs due to timeouts:
try {
val fetchedBytes = askTracker[Array[Byte]](GetMapOutputStatuses(shuffleId))
fetchedStatuses = MapOutputTracker.deserializeMapStatuses(fetchedBytes)
logInfo("Got the output locations")
mapStatuses.put(shuffleId, fetchedStatuses)
} finally {
fetching.synchronized {
fetching -= shuffleId
fetching.notifyAll()
}
}
}
logDebug(s"Fetching map output statuses for shuffle $shuffleId took " +
s"${System.currentTimeMillis - startTime} ms")
if (fetchedStatuses != null) {
return fetchedStatuses
} else {
logError("Missing all output locations for shuffle " + shuffleId)
throw new MetadataFetchFailedException(
shuffleId, -1, "Missing all output locations for shuffle " + shuffleId)
}
} else {
return statuses
}
}
上面的fetching是个HashSet,最后赚到了askTracker里面的调用,然后通过trackerEndPoint的askWithRetry向位于Driver的MapOutputMasterEndpoint发送消息来获取MapStatus对象,接收到消息之后Driver的MapOutputTrackerMasterEndpoint的receiveAndReply方法调用了MapOutputTracker.post(new GetMapOutputMessage(shuffleId, context))来获取MapStatus,这是个生产者消费者的消息循环,最终是在MessageLoop的run方法里面val mapOutputStatuses = getSerializedMapOutputStatuses(shuffleId)获取了MapStatus
获取了位置信息之后就开始读取数据,读取数据的逻辑在ShuffleBlockFetcherIterator里面的initialize()方法里面,initialize方法通过一个FetchRequest的队列,对MapStatus经过解析之后先放入需要远程获取的FetchRequest,然后开始使用fetchUpToMaxBytes获取远程的数据,接下来使用fetchLocalBlocks()获取本地数据
private[this] def initialize(): Unit = {
// Add a task completion callback (called in both success case and failure case) to cleanup.
context.addTaskCompletionListener(_ => cleanup())
// Split local and remote blocks.
// 先获得所有需要远程获取的
val remoteRequests = splitLocalRemoteBlocks()
// Add the remote requests into our queue in a random order
fetchRequests ++= Utils.randomize(remoteRequests)
assert ((0 == reqsInFlight) == (0 == bytesInFlight),
"expected reqsInFlight = 0 but found reqsInFlight = " + reqsInFlight +
", expected bytesInFlight = 0 but found bytesInFlight = " + bytesInFlight)
// Send out initial requests for blocks, up to our maxBytesInFlight
// 远程获取数据
fetchUpToMaxBytes()
val numFetches = remoteRequests.size - fetchRequests.size
logInfo("Started " + numFetches + " remote fetches in" + Utils.getUsedTimeMs(startTime))
// Get Local Blocks
// 获取本地的数据
fetchLocalBlocks()
logDebug("Got local blocks in " + Utils.getUsedTimeMs(startTime))
}
数据读取完毕之后read方法里面判断了是否要做聚合操作
/** Read the combined key-values for this reduce task */
override def read(): Iterator[Product2[K, C]] = {
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
// 如果在map端做了聚合就调用combineCombinersByKey
if (dep.mapSideCombine) {
// We are reading values that are already combined
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
// 如果在map端做了聚合就调用combineValuesByKey
// We don't know the value type, but also don't care -- the dependency *should*
// have made sure its compatible w/ this aggregator, which will convert the value
// type to the combined type C
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
}
// Sort the output if there is a sort ordering defined.
// 如果需要排序那么使用外部排序进行排序
dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// Create an ExternalSorter to sort the data. Note that if spark.shuffle.spill is disabled,
// the ExternalSorter won't spill to disk.
val sorter =
new ExternalSorter[K, C, C](context, ordering = Some(keyOrd), serializer = dep.serializer)
sorter.insertAll(aggregatedIter)
context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes)
CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop())
case None =>
aggregatedIter
}
}














 4483
4483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









