







正规方程与梯度下降的区别
- 梯度下降给出的是一种不断迭代的方法,通过计算机进行反复的运算,找到最优的θ向量使代价函数J(θ)收敛,此时得到最优的假设函数参数θ。
- 正规方程则是给出了一种数学方法,通过数学的推导得到了正规方程,必须经过反复迭代,只需一步计算即可解出最优的θ。
如何使用正规方程
以一个n = 3,m = 4,即有四个特征量和四个训练样本的数据为例。

x对应的是特征量,由于其n = 3,m = 4,将每一个特征量x存储在矩阵中,得到的当然是4*4( (n+1)*m 阶的矩阵,n还需要+1因为包含x0,而x0默认为1 )的矩阵X。而y为训练样本中特征量对应的真实值,将每一个y存储成为一个列向量,得到了四维列向量。
得到矩阵X和列向量y后,即可进行正规方程运算。其运算公式为:
θ = (XTX)-1XTy。T为矩阵的转置,-1为求逆,在Octave中使用inv()或pinv()实现。
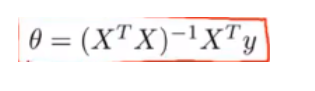
梯度下降与正规方程的对比
梯度下降法的缺点:
- 梯度下降法需要选择学习率α。
- 梯度下降需要多次迭代。
梯度下降法的优点: - 当n( 特征量 xi 的个数 )很大时,也能运行的很好。
正规方程的缺点: - n很大时,运行的速度很慢(对于大多数算法,求解矩阵的逆时的时间复杂度时O(n3))。因此,当n很大时,倾向于使用梯度下降法 ( n = 10000时,可以开始考虑使用梯度下降法 ) 。
- 正规方程并不适用于更复杂的算法,此时仍需使用梯度下降法。
Python实现
def normalEqn(X, y):
theta = np.linalg.pinv(X.T@X)@X.T@y
return theta















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









