







简介
本文粗略介绍了gpu在通讯方面的演进,发展,及一些基础的性能调优思路。
朴素的内存搬运
数据从一张gpu的显存到另一张gpu的显存,最简单的方式,自然是先将数据从显存搬运到内存,再通过内存搬运到显存。
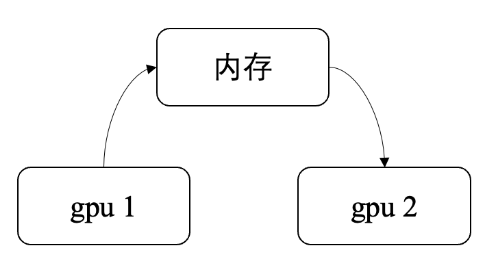
这种方式很朴素,效率自然也不高,带宽一般在几GB/s量级,但事实上,仍旧有许多机器采用这种方式,即便使用的已经是先进的A100, A800等卡,如果硬件不支持,或者配置错误,该慢自然还是慢。这里的配置错误,更多的指的是云厂商配置错误,这里有一篇几年前的文章,就对比了这一点:
GPU云主机基础能力对比
为什么同样一款gpu,性能能相差这么多,那大概率是底层的配置有误,或者忽略了一些gpu跨numa只能走内存搬运的问题。
对于用户而言,也是可以通过底层的cuda api或者一些环境变量的设定,来尝试这种低效的通信方式,一般会带来性能的降低。
GPU Direct P2P: 直接走pcie switch
与通过内存搬运相比,gpu通过pcie通路相连自然是更快很多,达到几十GB/s量级。
gpu归根到底,是一种pcie设备,是插到pcie插槽上面的,而一台多卡的机器,也往往是通过pcie switch将其相连。通过gpu direct p2p技术,一个gpu的数据不再借助内存,而是直接通过pcie switch将数据传输给另一gpu,如下图中gpu1和gpu2的数据通道。
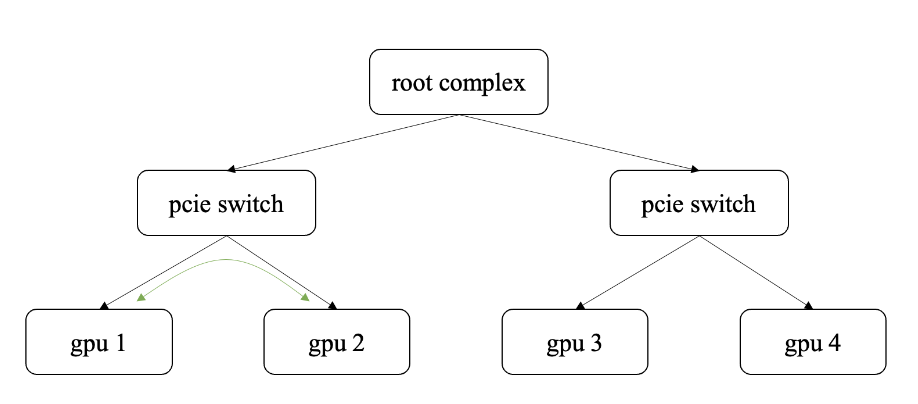
有了gpu direct p2p技术后,gpu的通信性能并不是就高枕无忧了,这里又有了新的配置问题,和亲和性的选择,先说配置问题,主要指的是物理机配置,反直觉的是,很多人的gpu, 说好的是“direct” p2p,事实上数据还是要走cpu的。
为什么会这样,一是无意中开启了虚拟化,二是开启了acs功能。
当访问一个内存时,会通过mmu将虚拟地址翻译为物理地址,而对于gpu而言,也可能通过iommu将其访问的虚拟地址转为物理地址,和mmu必须要有不同,这项功能是可选的,很多人默认开启了。
iommu主要与虚拟化相关,在虚拟化场景中,一台机器的多张卡,会分给不同的用户,所以自然要通过这一层地址转换,否则一个用户就可以随意访问其他用户的地址了,但是如果这台物理机完完全全是你自己的,那就有必要关掉这个功能了。
acs功能基本同上,也是对p2p进行管理控制,不让设备进行随意的p2p,防止恶意的用户或是恶意的硬件,两者都是为了安全,也会让数据经过上图中的root complex中(一般集成到cpu中),造成性能的下降。
当自己独占一台物理机,并没有多租户的安全问题,那么关掉这两个功能,往往会有意想不到的性能提升。
另一个便是亲和性问题,一台机器多张卡,卡与卡之间也是有亲疏远近之分的。很多时候涉及到调度,也许就会惆怅这个问题,一台机器8张卡,现在想要2张,怎么选呢?
这里建议找寻专业的技术人员,看一下lspci -tv等设备拓扑信息,得到类似上图那样的拓扑关系,往往会找到答案,例如gpu1和gpu2通信,就会比gpu1和gpu3通信快很多,因为不需要经过root complex。
如果说个人用户,没那么较真,也有一个简易的口诀,往往能解决90%的问题:
先找numa再找近,尽量选偶不选奇。
先找numa,多张卡的机器上,卡往往有不同的numa, 可以通过
cat /sys/bus/pci/devices/0000:ff:09.0/numa_node命令查出设备的numa信息,其中0000:ff:09.0是设备的bdf(Bus,Device,Function),俗称pci地址或者pci号。
大部分情况下,系统都是有两个numa,这个值不是1就是0,那么我们选卡的时候,就尽量都在0或者1上选。
那假如说numa 0有四张卡,想选两张,如何选呢,那就需要再找近,这里的近,是设备拓扑的近,但是很多时候不方便看或者看不懂,那就也可以用bdf来代替,因为设备拓扑近,那么他们的bdf也就往往是接近的,但也保不准有台特殊的机器不是这样,所以说口诀只是作为参考。
如果我们numa 0上有四张卡 0,1,2,3(通过nvidia-smi看到的卡号,一般就是通过bdf排序的,参考环境变量 CUDA_DEVICE_ORDER),那么是否选0,1和选1,2都一样呢,这就是后半句口诀了,尽量选偶不选奇,选择0,1,因为这两张卡开头在偶数位。这是为何?因为卡在插向pcie switch的时候,一般都是成对插的,很少说先插三张再插一张这种插法,如果发现这种情况了,建议换个服务器厂商试试。
专业的用户,建议还是通过系统/sys下面的信息,生成一棵设备树,通过这棵设备树来判断拓扑关系,这就相当于计算一棵树两个叶子结点之间的距离。但是还需要区分这个路径上的结点代表着什么,是一个pcie switch还是一个root complex,关于这套找距离的方法,业界已经有示例,那就是nvidia的高性能通讯库nccl,大家可以基于此进行参考。
nvlink/hccs: gpu自己的通讯硬件
pcie协议是由intel主导的,从一开始也并非为卡间高速互联而设计。带宽最高也就在几十GB/s左右。几十GB/s实则也不小了,但是仍旧满足不了gpu的要求。
为了可以进一步增强卡间互联,gpu厂商放弃了在pcie上吊死,而是转为实现了自己的硬件,自己的协议。
其中,最著名的自然是nvidia的nvlink以及华为的hccs了,这里主要介绍nvlink。
从双卡交火到hpc模组,nvlink经过了不小的发展变化,性能功能也越来越强悍。
最开始的nvlink只是类似于一个桥的存在,是一个实体硬件,一端接一张gpu,这两张gpu就可以交互连接了。

但是现在的nvlink, 已经不能说是nvlink,而是nvswitch,只是大家叫习惯了,仍然将其叫做nvlink。如果说最开始的nvlink是一根网线,那么现在的nvlink则是一台交换机了,见下图:
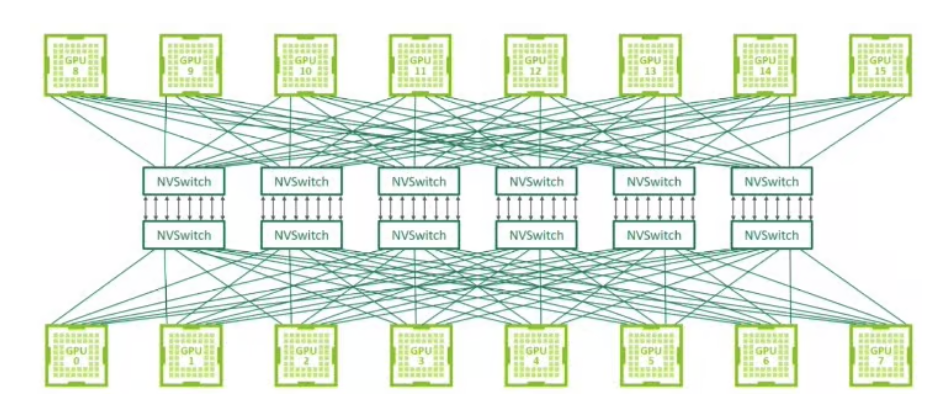
多张卡通过一条条“link”连接到nvswitch上(可以通过命令 nvidia-smi nvlink -s查看),实现了高速的卡间互联,如今带宽已经到达几百GB/s量级,足以满足大部分的场景需求。
nvlink的使用十分简易,简易到几乎没有文档说明,但还是需要做一些操作的,很多人机器里明明有8张卡,但是还是报cuda error没有gpu可用,就是因为有nvlink的机器, 还需要启动nvidia-fabricmanager.service 这个服务。
有了nvlink后,gpu之前的亲和性关系就有了变化,因为不再通过pcie switch传输数据,而是先把数据给nvlink,nvlink再进行数据路由到另一个gpu上,这样两张gpu的拓扑远近就不重要了,就好比两个人通过京me传输数据,不是搬着电脑坐在另一个人工位旁就快,因为数据是需要先上传京me服务器的。
但是仍旧推荐使用上述口诀来判定亲和性,一是numa信息仍旧影响着性能,二是可能会涉及rdma网卡的选择。
GPU Direct RDMA: 多机互联
上文中的通信技术都是应用在同一台机器的gpu与gpu之间,在大模型之前,大家对于多机互联的要求还没有那么高,一台机器8张卡,一张卡80GB,总共640GB显存,除了极少特殊业务外,对于正常训练是绰绰有余。然而,大模型出现后,几百G显存是不足够满足所需的。
首先不可能一台机器装100张gpu,即便有那么大机柜,散热,容灾,扩容都是大问题,所以只能通过网络来连接多台机器,以集群的形式来提供服务。
而网络方面,大家所熟知的tcp协议是很难满足这个要求的。对于socket套接字编程,一般都会分配一块内存,准备一个“buffer”,来接收数据。而数据通过路由网线等硬件设备到达网卡后,这个数据是要经过层层复制,才能到这个buffer里,注定不会快,rdma技术就是为解决这一点。
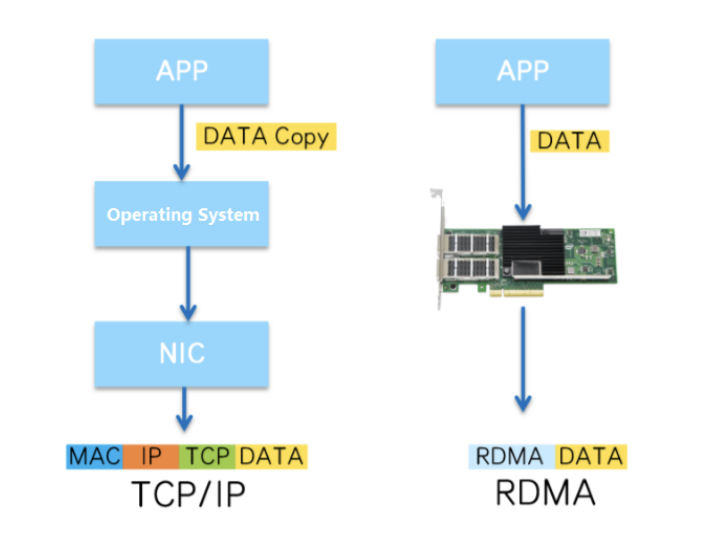
先说dma技术,归根到底就是设备自己负责读写一块内存,减轻cpu的负担。而rdma技术,则是通过rdma网卡直接读写远端机器的一块内存,就好像这个设备,本身就是远端机器的设备在进行dma。
换言之,远端机器准备一块内存后,过一会就会发现,这块内存上有内容了,而且是另一台机器的数据,而期间发生了什么,则不重要了。
通过rdma技术,绕过了内核网络协议栈,网卡的带宽大大增加,已经到了百G级别,足以满足gpu训练所需,但是想将其用起来却没有那么容易。为什么,因为nccl不是万能的。
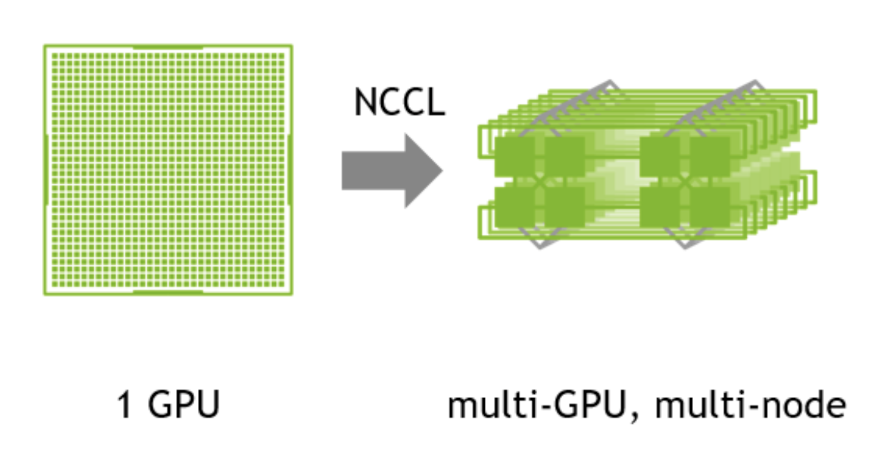
nccl,上文也简单提到过,全称为NVIDIA 集合通信库, gpu的底层api是cuda,但是在单机多卡乃至多机多卡时,cuda编程会变得困难,nccl则是cuda的再一层封装,实现了一套gpu之间的通信api。nccl在多机训练时,也会找寻设备拓扑关系,然后选择正确的设备来使用。
nccl被广泛应用,是主流训练框架pytorch的默认通信后端,即便是单卡训练,其实也是在不停调用nccl的。虽然nccl使用广泛,但许多人从未接触过nccl,因为nccl自适应做的很好,在单机训练乃至多机训练时,几乎不需要再操什么心。但是,在多机多卡牵扯到rdma网卡时,nccl有时就不那么可靠了。
一般一台hpc机器中,网卡是1+8的配置,即1个通信网卡+8个rdma网卡,通信网卡和rdma网卡并不互通。通信网卡就是常见的eth0,负责联网,建立ssh链接等,rdma网卡则是专门为训练使用的,一般不接入外网。然而,在硬件层面上,其实两者很可能都只是一张cx6网卡,之所以功能不同,也只是因为插入的交换机不同,配置的网关不同,上层应用是分不清两者用途的。所以nccl也会陷入这个难题:nccl枚举完网卡后,试了试eth0和另一端的eth0是通着的(相当于两台机器的子网通),但是eth0和任一rdma网卡都不通,于是沉思了一会,干脆就让两台机器的eth0负责训练了。这也造成了,使用hpc机器训练跑起来了,但看着性能不过如此,实则rdma网卡并未正确使用。
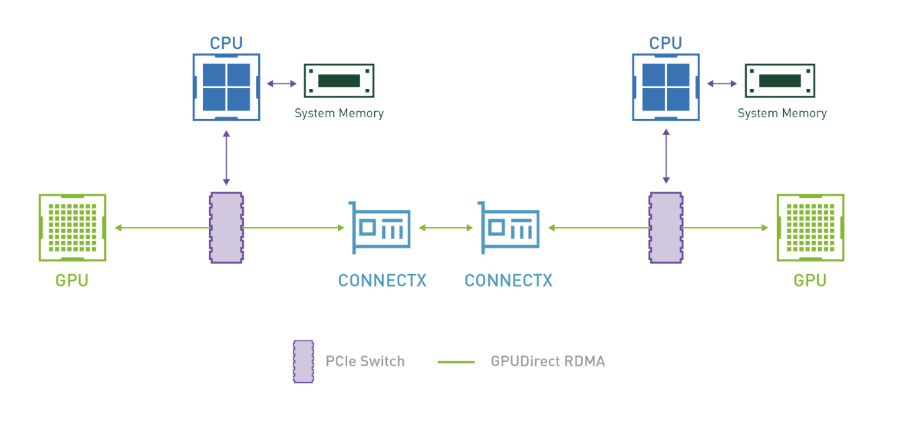
gpu direct rdma技术则是在rdma技术上又增添了一层,gpu直接和网卡进行通信,绕过cpu,这无疑增快了数据传输速度,减少了cpu 内存占用,进一步提升了性能。
但是,这个direct仍然不一定是真direct,除了上文iommu, acs等功能的影响,虚拟化层本身就很难让数据绕过cpu,这一点我们会在后文详细讲述原理。
gpu direct rdma就会让速度更快吗?其实不然,根据实测,如果gpu和网卡在设备拓扑中距离过远,其实还不如使用内存搬运来的快,所以如果想要极致的性能,就不能再让nccl隐于幕后,还是需要调整其一些参数的,我们也会在后文详细讲解这些。
结尾
本文粗略介绍了gpu在通讯方面的演进,发展,及一些基础的性能调优思路。

















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









