










-
绪言
前面因需要学习了几天manim的用法,在使用MathTex时发现内容里面有中文且存在数学公式时,改变字体的颜色出现显示不正确,在这里折腾了好几个晚上,期间过程也比较曲拆,在网上查找了很多资料,根据资料来修改manim的python源码,最后功夫不负苦心人,终于解决了这个问题。就本篇文章发布之前,可以说是在网上找不到问题的解决方案,为了让使用manim的伙伴们不再走弯路,在下提供解决问题的方法。
展示效果
FlyLevalStart

环境
本人的环境如下:
manim版本:Manim Community v0.18.1
python版本: Python 3.10.15
latex编译器:MikTex 4.12
ffmpeg编码解码器:ffmpeg version N-117703-gdf00705e00-20241104 Copyright (c) 2000-2024 the FFmpeg developers
解决步骤
1、首先在代码中设定 latex 文档模板的主导区的命令内容
关于latex 文档模板标准格式,可以自已百度一下,设置后如何验证,可以使用latex在线编辑器,我使用的是下面这个:
TeXPage - Online LaTeX Editor | Compile LaTeX Online
言归正传,我在自已的python代码文件中修改如下,在类的构造里面设置
class FlyLevalStart(Scene):
# set background
def setBackground(self):
self.camera.background_color = (68, 84, 106)
def construct(self):
config.tex_template = TexTemplate()
config.tex_template.add_to_preamble(r"\usepackage{ctex}")
config.tex_template.add_to_preamble(r"\usepackage{xcolor,color,soul}")
#config.tex_template.tex_compiler = "pdflatex"
#------to do start----------------------
#self.addPage1()
#self.wait()
#self.clear()
self.addExaple2()
#self.wait()
#self.clear()
def addExaple2(self):
pass
2、修改部分manim本身源代码
我的manim安装的路径为:
C:\Users\Lenovo\anaconda3\envs\miky_31013\Lib\site-packages\manim,我使用的是anaconda3中的环境。
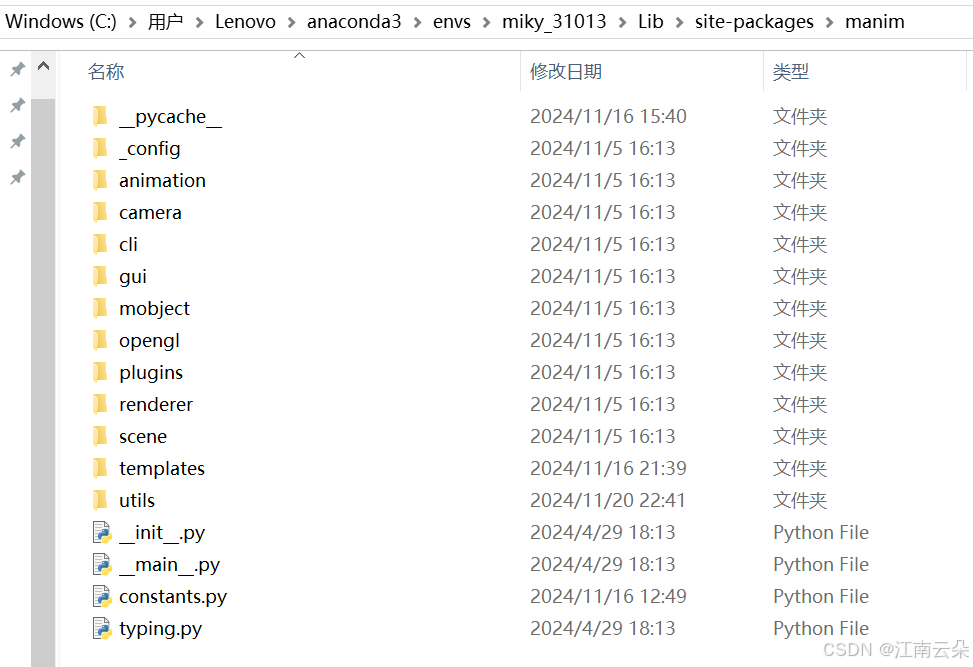
- 在该路径下的utils文件夹下,打开tex.py文件,在 class TexTemplate:这个类的下面先增加两个方法,这是我增加的两个方法:is_chinese contains_chinese,判断是否包含中文
@dataclass(eq=True)
class TexTemplate:
#fcc 这是我增加的两个方法:is_chinese contains_chinese,判断是否包含中文
def is_chinese(self,char):
result = False
if '\u4e00' <= char <= '\u9fff':
result = True
if '\u3000' <= char <= '\u303F':
result = True
if '\uFF00' <= char <= '\uFFEF':
result = True
return result
def contains_chinese(self,text):
return any(self.is_chinese(char) for char in text)- 再在这个tex.py文件中找到get_texcode_for_expression_in_env,get_texcode_for_expression这两个方法,修改为
def get_texcode_for_expression_in_env(
self, expression: str, environment: str
) -> str:
left_del_char = "LDC{"
right_del_char = "}"
if self.contains_chinese(expression):
expression = expression.replace(left_del_char, "\\text{")
expression = expression.replace("}", "}")
expression = expression.replace("hscolor", "textcolor{yellow}")
expression = expression.replace("lscolor", "textcolor{blue}")
print("--------$$$$$$$$$$$$$$$$$$$$tex.py line 182 expression=" + expression)
begin, end = _texcode_for_environment(environment)
return self.body.replace(
self.placeholder_text, "\n".join([begin, expression, end])
)
def get_texcode_for_expression(self, expression: str) -> str:
left_del_char = "LDC{"
right_del_char = "}"
if self.contains_chinese(expression):
#expression = "\\text" + expression + ""
expression = expression.replace(left_del_char,"\\text{")
expression = expression.replace("}","}")
expression = expression.replace("hscolor","textcolor{yellow}")
expression = expression.replace("lscolor", "textcolor{blue}")
print("--------$$$$$$$$$$$$$$$$$$$$tex.py line 155 expression=" + expression)
return self.body.replace(self.placeholder_text, expression)- 然后在manim下面找到\mobject\text\tex_mobject.py这个文件,打开进行修改
#----先找到 MathTex 这个类,在下面增加is_chinese、contains_chinese、process_self_text
#增加三个方法,主要是判断中文和增加格式
class MathTex(SingleStringMathTex):
#fcc add chinese judge--------
def is_chinese(self,char):
result = False
if '\u4e00' <= char <= '\u9fff':
result = True
if '\u3000' <= char <= '\u303F':
result = True
if '\uFF00' <= char <= '\uFFEF':
result = True
return result
def contains_chinese(self,text):
return any(self.is_chinese(char) for char in text)
def process_self_text(self):
new_tex_strings = []
textindex = -1
has_on = False
has_alltime_chinese = True
t_len = len(self.tex_strings)
left_del_char = "LDC{"
right_del_char = "}"
for tex_string in self.tex_strings:
textindex = textindex + 1
if self.contains_chinese(tex_string):
print("@@@@@ 238 line 是中文字符:" + tex_string)
if not has_on:
if textindex == t_len - 1:
new_tex_strings.append(left_del_char + tex_string + right_del_char)
else:
new_tex_strings.append(left_del_char + tex_string)
else:
if textindex == t_len - 1:
new_tex_strings.append(tex_string + right_del_char)
else:
new_tex_strings.append(tex_string)
has_on = True
else:
has_alltime_chinese = False
print("!!!!!!! 250 line 非中文字符:" + tex_string)
new_tex_strings.append(tex_string)
if has_on:
new_tex_strings[textindex - 1] = new_tex_strings[textindex - 1] + right_del_char
has_on = False
if has_alltime_chinese:
print("******$$$$$$ 256 line 一直是中文,没有出现英文和数学公式$$$$$******")
if new_tex_strings[t_len-1].endswith(right_del_char):
print("****** 293 line 最后一项=" + new_tex_strings[t_len-1])
else:
print("****** 295 line 最后一项处理前=" + new_tex_strings[t_len - 1])
new_tex_strings[t_len - 1] = new_tex_strings[t_len - 1] + right_del_char
print("****** 297 line 最后一项处理后=" + new_tex_strings[t_len - 1])
return [p for p in new_tex_strings if p]再在这个MathTex类下的 __init__方法调用上面的方法new_tex_strings_array = self.process_self_text()方法生成new_tex_strings_array,把这个给super.__init__方法中去使用,修改的地方我发个图
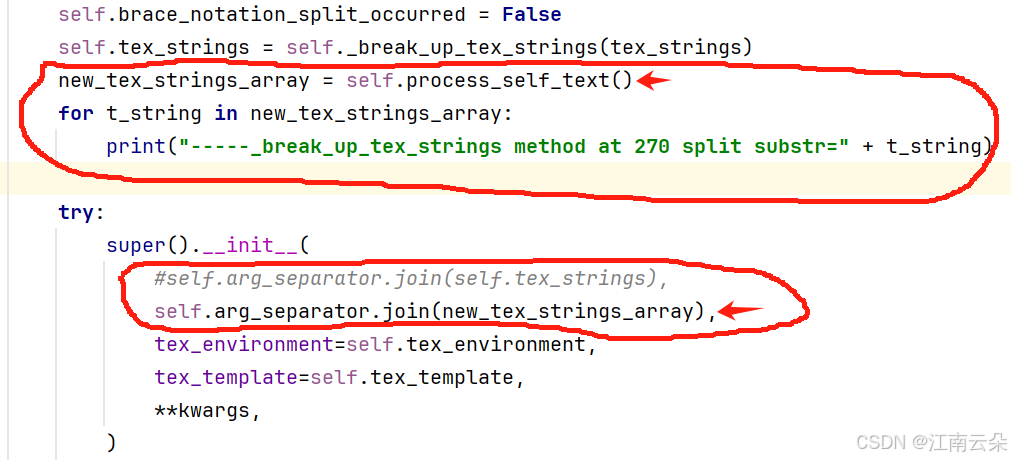
代码如下
def __init__(
self,
*tex_strings,
arg_separator: str = " ",
substrings_to_isolate: Iterable[str] | None = None,
tex_to_color_map: dict[str, ManimColor] = None,
tex_environment: str = "align*",
**kwargs,
):
self.tex_template = kwargs.pop("tex_template", config["tex_template"])
self.arg_separator = arg_separator
self.substrings_to_isolate = (
[] if substrings_to_isolate is None else substrings_to_isolate
)
self.tex_to_color_map = tex_to_color_map
if self.tex_to_color_map is None:
self.tex_to_color_map = {}
self.tex_environment = tex_environment
self.brace_notation_split_occurred = False
self.tex_strings = self._break_up_tex_strings(tex_strings)
new_tex_strings_array = self.process_self_text()
for t_string in new_tex_strings_array:
print("-----_break_up_tex_strings method at 270 split substr=" + t_string)
try:
super().__init__(
#self.arg_separator.join(self.tex_strings),
self.arg_separator.join(new_tex_strings_array),
tex_environment=self.tex_environment,
tex_template=self.tex_template,
**kwargs,
)
print("-----before self._break_up_by_substrings()")
self._break_up_by_substrings()
print("-----after self._break_up_by_substrings()")
except ValueError as compilation_error:
if self.brace_notation_split_occurred:
logger.error(
dedent(
"""\
A group of double braces, {{ ... }}, was detected in
your string. Manim splits TeX strings at the double
braces, which might have caused the current
compilation error. If you didn't use the double brace
split intentionally, add spaces between the braces to
avoid the automatic splitting: {{ ... }} --> { { ... } }.
""",
),
)
raise compilation_error
self.set_color_by_tex_to_color_map(self.tex_to_color_map)
if self.organize_left_to_right:
self._organize_submobjects_left_to_right()再在这个文件中找到_break_up_by_substrings这个方法,修改如下,我先发个图
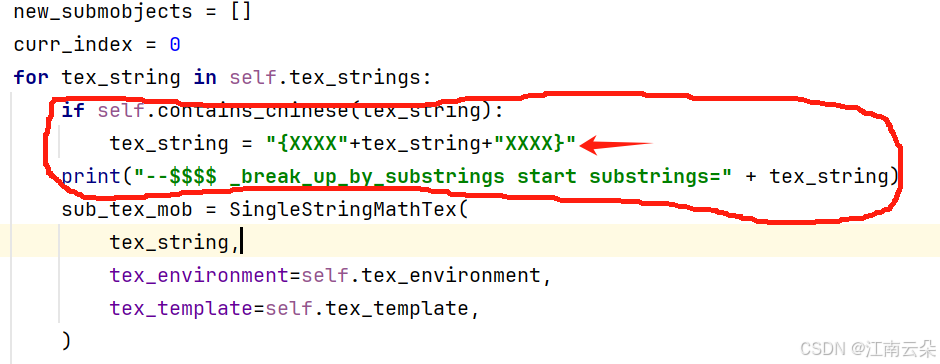
- 代码如下:
def _break_up_by_substrings(self):
"""
Reorganize existing submobjects one layer
deeper based on the structure of tex_strings (as a list
of tex_strings)
"""
left_del_char = "LDC{"
right_del_char = "}"
new_submobjects = []
curr_index = 0
for tex_string in self.tex_strings:
if self.contains_chinese(tex_string):
tex_string = left_del_char+tex_string+right_del_char
print("--$$$$ _break_up_by_substrings start substrings=" + tex_string)
sub_tex_mob = SingleStringMathTex(
tex_string,
tex_environment=self.tex_environment,
tex_template=self.tex_template,
)
print("--$$$$ _break_up_by_substrings SingleStringMathTex finish substrings=" + tex_string)
num_submobs = len(sub_tex_mob.submobjects)
new_index = (
curr_index + num_submobs + len("".join(self.arg_separator.split()))
)
if num_submobs == 0:
last_submob_index = min(curr_index, len(self.submobjects) - 1)
sub_tex_mob.move_to(self.submobjects[last_submob_index], RIGHT)
else:
sub_tex_mob.submobjects = self.submobjects[curr_index:new_index]
new_submobjects.append(sub_tex_mob)
curr_index = new_index
self.submobjects = new_submobjects
return self3、测试运行,到此为止,所有代码修改完毕,测试一下,代码如下
测试重点
1、记得加上模板参数和颜色参数:
substrings_to_isolate=["y","透","sin x"],
tex_to_color_map={"y": RED,"透":PINK,"sin x":BLUE},
tex_template=config.tex_template
2、构造时,分别把中文与公式分开,我的是这样的
tex = MathTex(
"有透明度eeee我的",
"y",
"=",
"\sin x",
substrings_to_isolate=["y","透","sin x"],
tex_to_color_map={"y": RED,"透":PINK,"sin x":BLUE},
tex_template=config.tex_template
)
3、具体看下面代码:
# -*- coding=utf-8 -*-
from manim import *
import numpy as np
import os
from manim.__main__ import main
class FlyLevalStart(Scene):
# set background
def setBackground(self):
self.camera.background_color = (68, 84, 106)
def construct(self):
config.tex_template = TexTemplate()
config.tex_template.add_to_preamble(r"\usepackage{ctex}")
config.tex_template.add_to_preamble(r"\usepackage{xcolor,color,soul}")
#config.tex_template.tex_compiler = "pdflatex"
#------to do start----------------------
self.addExaple2()
#self.wait()
#self.clear()
# ------to do end----------------------
def addExaple2(self):
label = Text("有透明度:", font="STLiti", font_size=25).shift(LEFT * 2)
tex = MathTex(
"有透明度eeee我的",
"y",
"=",
"\sin x",
substrings_to_isolate=["y","透","sin x"],
tex_to_color_map={"y": RED,"透":PINK,"sin x":BLUE},
tex_template=config.tex_template
)
tex.next_to(label, direction=RIGHT, buff=0.5)
self.add(label)
self.play(Write(tex))
if __name__ == "__main__":
module_name = os.path.basename(__file__)
print(module_name)
scene_name = "FlyLevalStart"
os.system(f"manim --disable_caching -pqh {module_name} {scene_name}")最后在pycharm中运行这个文件即可,如果没有安装pycharm,可以直接在命令行中使用如下命令:
# manim --disable_caching -pqh [python文件路径] [场景名]
#例如,这样写
manim --disable_caching -pqh d:/pytest/FlyLevals.py FlyLevalStart贴上运行效果图:

到此本篇文章就结束了,伙伴们,希望对你们有帮助。

















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









