







为了获得更高的性能,可以使用手写的汇编代码来优化核心的部分。
手写汇编代码能给予你对三个优化工具的直接控制,而这些是C源代码无法提供的。
- Instruction scheduling
- Register allocation
- Conditional execution
我们讲述的优化技巧是用于ARM汇编的,Thumb汇编没有特定的讲解,因为ARM汇编在32-bit bus上总是有更好的性能。
Thumb在减少C代码的编译尺寸的时候是很有用的,然而对于提升性能和更高效的执行没有多大用处。我们这里的大部分准则对于ARM和Thumb都是同样适用的。
| 6-1 Writing Assembly Code |
| 6-2 Profiling and Cycle Counting |
A profiler is a tool that measures the proportion of time or processing cycles spent in each subroutine.
A cycle counter measures the number of cycles taken by a specific routine.
| 6-3 Instruction Scheduling |
执行指令的时间取决于piepline的实现,我们这里以ARM9TDMI为例。
条件指令,在条件不满足的时候需要one cycle,满足时适用于以下准则:
- ALU操作如加减和逻辑操作耗费one cycle(包含带立即数的移位)。使用特定寄存器的移位,增加one cycle。写入pc的指令增加two cycle。
- Load instructions that load N 32-bit words,例如LDR and LDM需要N cycles to issue, 最后加载的word结果在接下来的一个cycle中无法获得的。如果指令加载pc需要额外耗费two cycles
- Load instructions that load 16-bit or 8-bit data such as LDRB,LDRSB,LDRH,LDRSH take one cycle to issue, 加载的结果在接下来two cycles是无法获得的.
- Branch instructions take three cycles
- Store instructions that store N values take N cycles.STM处理单独数值需要two cycles.
- multiply instructions对于second operand的不同需要不同数目的cycles
ARM9TDMI同时操作五步:
- Fetch
- Decode:将那些与input operands相关且在接下来步骤中无法获得的banked register的值读取出来。
- ALU:执行指令,不同的指令在该阶段消耗不同的cycles。
- LS1:是load或者store指令的时候load or store数据,如果不是则该阶段无效
- LS2:如果是byte or haldword load instruction则Extract(取出)and zero- or sign-extend the data;如果不是,该阶段无效。
如下图:
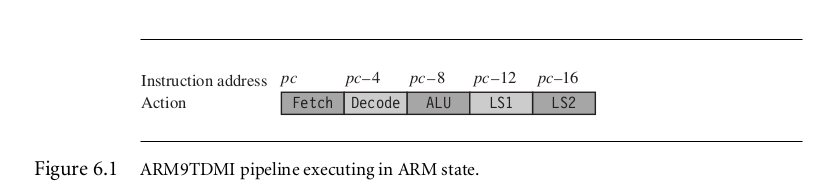
如果一条指令需要前一个指令的结果,但是暂时获得不了,处理器就会stalls。这种情况被称作a pipeline hazard or pipeline interlock.
接下来用例子进行讲解。
Example
1.不会发生interlock的情况
ADD r0, r0, r1
ADD r0, r0, r22.One-cycle interlock caused by load use.
LDR r1, [r2, #4]
LDR r0, r0, r1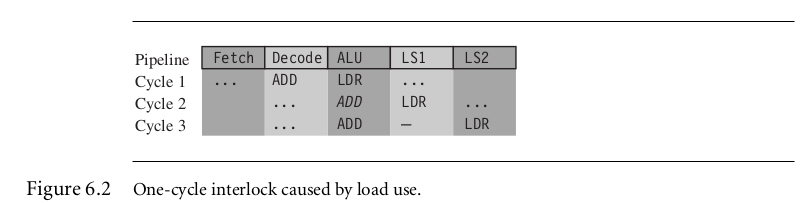
如图所示,当ADD处于ALU阶段的时候,由于LDR还处于LS1阶段也就是r1还没有加载好,因此ADD需要等待一个周期直到r1加载好。
在cycle3 中ADD和LDR中间的间隙又被称为:pipeline bubble
3.This example shows a one-cycle interlock caused by delayed load use.
LDRB r1, [r2, #1]
ADD r0, r0, r2
EOR r0, r0, r1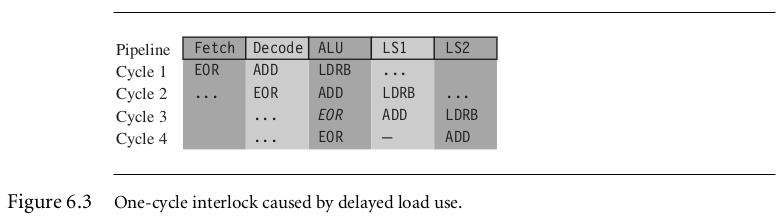
如图,当EOR在ALU-stage的时候,LDRB还处于LS2阶段,因此r1并没有加载好,所以要多等待one cycle。你会发现ADD对于时间没有任何影响,不管有没有ADD指令,该例子必须要经过four cycles。
4.Pipeline flush caused by a branch.
MOV r1, #1
B case1
AND r0, r0, r1
EOR r2, r2, r3
...
case1
SUB r0, r0, r1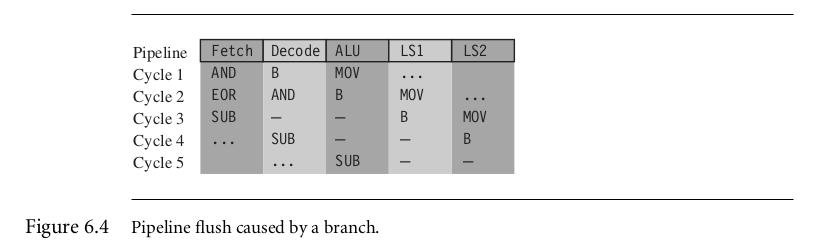
当执行B之后,core会flush pipeline—case1中的SUB指令会进入fetch-stage,因此B的完成需要3 cycles。
| 6.3.1-Scheduling of load instructions |
load指令在编译过的代码里出现频率很高,大约指令的1/3.因此,仔细的scheduling of load instrcutions减少pipeline stalls的发生能够提升性能。由于C的alias问题(section 5.6)限制了编译器的优化能力。编译器不能移动在store instrcution前移动load instruction,除非确定两个指针没有指向相同的地址。
Example:

相应汇编代码如下:

从代码中我们可以看出SUB在LDRB之后,因为r2的值在LDRB完成之前无法确定,因此,pipeline will stall two cycles。
但是,这里有两种办法用于修改算法结构来避免这些无意义的cycles。方法分别为:
1. Preloading
2. Unrolling
Loading Scheduling by Preloading
这种方法是将循环中开头的LDRB放到循环开始前,并且在进行下一次循环前执行LDRB,如下图代码:


在上图loop开始前的LDRB和末尾的LDRNEB,就是与上段代码的不同之处。
该段代码从11 cycles下降到9 cycles。提升到1.22倍的速度。
ARM结构也是和这样的preloading,因为指令可以被条件执行。
Loading Scheduling by Unrolling
这种方法是直接展开代码,将LDRB与处理的代码分割开,代码改成如下:


从代码中可知,先是LDRB出三个ch,然后进行处理,在每个字符处理的时候,相应的LDRB早就完成了。
这种方法比你想象中提升的性能还要多,在ARM9TDMI中从11-cycles下降到7-cycles,提升到1.57倍的速度性能。缺点是提升了一倍的代码空间。此外,字符串在RAM的尾部,超出范围的读取会产生data abort,并且在非常短小的string中性能会降低:stacking lr造成了过度的额外函数调用 。
这种方法适用于时间非常重要且空间足够大的环境中,当你在编译器时间直到数据的尺寸,你可以移除掉读取越界的问题。
| 6.3.2-Summary |
- ARM Core使用pipeline结构,Pipeline会延迟特定指令结果的获得。当你使用了使用该结果的指令,处理器会插入stall cycles直到取得了结果。
- Load and multiply instructions have delayed results in many implementations. See Appendix D for the cycle timings and delay for your specific ARM processor core.
- You have two software methods available to remove interlocks following load instructions: You can
preloadso that loop i loads the data for loop i + 1, or you canunrollthe loop and interleave the code for loops i and i + 1.
| 6-4 Register Allocation |
符合ATPCS的应用程序必须保存寄存器r4~r11的值。ATPCS也规定了stack必须要是eight-bytes aligned。本节讲解如何最好地给变量分配寄存器,以及如何使用超过14个变量,和如何充分利用14个可获得寄存器。
| 6.4.1-Allocating variables to Register Numbers |
当你手写汇编代码的时候,最好给变量使用名字,而不是使用寄存器编号。甚至给相同的物理寄存器使用不同的名字,这样能增加代码的可读性。
然而在有些情况下,寄存器的物理编号是很重要的。
* Argument register。ATPCS规定function前四个参数分别对应于r0~r3,超过4个参数则存放到stack中。返回值必须放入r0中。
* Registers used in a load or store multiple。如LDM,STM操作了一系列连续增加的寄存器编号。如果r0,r1同时在register list中,processor将会使用较低的地址load和store r0,然后才是r1.
* Load and store double word。操作连续的寄存器,如Rd, Rd+1。而且Rd必须是偶数的。
| 6.4.2-Using More Than 14 Local Variables |
如果你想要使用超过14个局部变量,最好的办法是将一些变量存放到stack中。
| 6.4.3-Making the most of available Registers |
| 6-10 Summary |
For the best performance in an application you will need to write optimized assembly routines. It is only worth optimizing the key routines that the performance depends on.You can find these using a profiling or cycle counting tool,such as the ARMulator simulator from ARM.
This chapter covered examples and useful techniques for optimizing ARM assembly.
Here are the key ideas:
■ Schedule code so that you do not incur processor interlocks or stalls. Use Appendix D to see how quickly an instruction result is available. Concentrate particularly on load and multiply instructions, which often take a long time to produce results.
■ Hold as much data in the 14 available general-purpose registers as you can. Sometimes it is possible to pack several data items in a single register. Avoid stacking data in the innermost loop.
■ For small if statements, use conditional data processing operations rather than conditional branches.
■ Use unrolled loops that count down to zero for the maximum loop performance.
■ For packing and unpacking bit-packed data, use 32-bit register buffers to increase efficiency and reduce memory data bandwidth.
■ Use branch tables and hash functions to implement efficient switch statements.
■ To handle unaligned data efficiently, use multiple routines. Optimize each routine for a particular alignment of the input and output arrays. Select between the routines at run time.
















 4522
4522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











