






嵌入式软件项目通常包含几个主导系统性能的关键子例程。通过优化这些例程,您可以降低系统功耗,并减少实时操作所需的时钟速度。优化可以将一个不可行的系统变为可行的系统,或将一个竞争力不强的系统变为有竞争力的系统。
如果您按照第5章中给出的规则仔细编写C代码,您将获得一个相对高效的实现。为了实现最大性能,您可以使用手写汇编语言来优化关键的例程。手动编写汇编语言使您直接控制了三种优化工具,这些工具无法通过编写C源代码显式使用:
■ 指令调度:重新排列代码序列中的指令,以避免处理器停顿。由于ARM实现是流水线的,一条指令的执行时间可能会受到相邻指令的影响。我们将在第6.3节中详细讨论这个问题。
■ 寄存器分配:决定如何将变量分配到ARM寄存器或栈位置,以实现最大性能。我们的目标是尽量减少内存访问次数。请参阅第6.4节。
■ 条件执行:利用ARM的全部条件码和条件指令范围。请参阅第6.5节。
优化汇编例程需要额外的工作量,因此不要费力去优化非关键的例程。当您花时间对一个例程进行优化时,它带来的副作用是让您更好地理解算法、瓶颈和数据流。
第6.1节介绍了在ARM上进行汇编编程的基础知识。它向您展示了如何用汇编函数替换C函数,然后可以对该函数进行性能优化。
我们将介绍一些常见的优化技术,特别适用于ARM汇编语言编写。虽然本章没有专门涵盖Thumb汇编语言,因为在32位总线可用时,ARM汇编语言总是可以获得更好的性能。Thumb对于减小对性能关键性不大的C代码的编译大小以及在16位数据总线上高效执行非常有用。这里介绍的许多原则同样适用于Thumb和ARM。
对于您的目标硬件所使用的ARM核心,特别是信号处理(在第8章中有详细介绍),最佳优化方法可能会有所不同。然而,您通常可以编写一个在所有ARM实现中都相对高效的例程。为了保持一致性,本章在示例中使用ARM9TDMI优化和周期计数。然而,这些示例在从ARM7TDMI到ARM10E的所有ARM核心上都能高效运行。
6.1 Writing Assembly Code
这一节提供了一些示例,展示了如何编写基本的汇编代码。我们假设您已经熟悉第3章中介绍的ARM指令;完整的指令参考可以在附录A中找到。我们还假设您已经熟悉第5.4节中介绍的ARM和Thumb过程调用标准。
和本书的其他部分一样,本章使用ARM宏汇编器armasm来进行示例(有关armasm语法和参考,请参阅附录A中的第A.4节)。您也可以使用GNU汇编器gas(有关GNU汇编器语法的详细信息,请参阅第A.5节)。
示例6.1展示了如何将一个C函数转换为一个汇编函数,这通常是汇编优化的第一步。考虑以下简单的C程序main.c,它打印从0到9的整数的平方:
#include <stdio.h>
int square(int i);
int main(void)
{
int i;
for (i=0; i<10; i++)
{
printf("Square of %d is %d\n", i, square(i));
}
}
int square(int i)
{
return i*i;
}让我们看看如何用执行相同操作的汇编函数来替换`square`函数。删除`square`的C定义,但保留声明(第二行),生成一个新的C文件`main1.c`。然后,添加一个名为`square.s`的armasm汇编器文件,内容如下所示:
AREA |.text|, CODE, READONLY
EXPORT square
; int square(int i)
square
MUL r1, r0, r0 ; r1 = r0 * r0
MOV r0, r1 ; r0 = r1
MOV pc, lr ; return r0
END`AREA`指令用于为代码所在的区域或代码段命名。如果在符号或区域名中使用非字母数字字符,则需要用竖线括起来。否则,许多非字母数字字符将具有特殊含义。在上面的代码中,我们定义了一个名为`.text`的只读代码区域。
`EXPORT`指令使得符号`square`可以用于外部链接。在第六行,我们将符号`square`定义为代码标签。注意,armasm将非缩进的文本视为标签定义。
当调用`square`函数时,参数传递由ATPCS(请参见第5.4节)定义。输入参数通过寄存器r0传递,返回值则通过寄存器r0返回。乘法指令有一个限制,即目标寄存器不能与第一个参数寄存器相同。因此,我们将乘法的结果放入r1,并将其移动到r0。
`END`指令标记汇编文件的结束。分号后面的内容是注释。
下面的脚本演示了如何使用命令行工具构建这个示例:
armcc -c main1.c
armasm square.s
armlink -o main1.axf main1.o square.o示例6.1仅在将C编译为ARM代码时才起作用。如果将C编译为Thumb代码,则汇编例程必须使用BX指令返回。
示例6.2展示了在将C编译为Thumb代码时调用ARM代码所需的唯一更改,即将返回指令改为BX。BX指令根据lr的第0位返回到ARM或Thumb状态。因此,该例程可以从ARM或Thumb中调用。只要处理器支持BX(ARMv4T及更高版本),就应该使用BX lr而不是MOV pc, lr。创建一个名为square2.s的新汇编文件,内容如下所示:
AREA |.text|, CODE, READONLY
EXPORT square
; int square(int i)
square
MUL r1, r0, r0 ; r1 = r0 * r0
MOV r0, r1 ; r0 = r1
BX lr
; return r0
END使用这个例子,我们使用Thumb C编译器tcc来构建C文件。我们使用启用了交互工作标志的汇编文件进行汇编,以便链接器允许Thumb C代码调用ARM汇编代码。您可以使用以下命令来构建这个例子:
tcc -c main1.c
armasm -apcs /interwork square2.s
armlink -o main2.axf main1.o square2.o示例6.3展示了如何从汇编例程中调用子例程。我们将采用示例6.1,并将整个程序(包括main函数)转换为汇编代码。我们将调用C库函数printf作为子例程。创建一个名为main3.s的新汇编文件,内容如下所示:
AREA |.text|, CODE, READONLY
EXPORT main
IMPORT |Lib$$Request$$armlib|, WEAK
IMPORT __main ; C library entry
IMPORT printf ; prints to stdout
i RN 4
; int main(void)
main
STMFD sp!, {i, lr}
MOV i, #0
loop
ADR r0, print_string
MOV r1, i
MUL r2, i, i
BL printf
ADD i, i, #1
CMP i, #10
BLT loop
LDMFD sp!, {i, pc}
print_string
DCB "Square of %d is %d\n", 0
END我们使用了一个新的指令IMPORT,来声明在其他文件中定义的符号。导入的符号Lib$$Request$$armlib是一个请求,要求链接器与标准ARM C库进行链接。WEAK修饰符可以防止链接器在找不到该符号时报错。如果找不到该符号,它的值将为零。第二个导入的符号___main是C库初始化代码的起始位置。只有在定义自己的main函数时才需要导入这些符号;在C代码中定义的main函数会自动导入这些符号。导入printf允许我们调用C库函数。
RN指令允许我们为寄存器使用名称。在本例中,我们将寄存器r4定义为i的替代名称。使用寄存器名称使得代码更易读。而且,在以后更改变量分配到寄存器上时更加方便。
请注意,ATPCS规定函数必须保存寄存器r4到r11和sp。我们破坏了i(r4),调用printf会破坏lr。因此,我们在函数开始处使用STMFD指令将这两个寄存器保存在堆栈中。LDMFD指令从堆栈中取出这些寄存器,并通过将返回地址写入pc来返回。
DCB指令用于定义字节数据,可以是一个字符串或逗号分隔的字节列表。
要构建这个示例,您可以使用以下命令行脚本:
armasm main3.s
armlink -o main3.axf main3.o请注意,示例6.3还假设代码是从ARM代码中调用的。如果代码可以像示例6.2中那样从Thumb代码中调用,那么我们必须能够返回到Thumb代码。对于ARMv5之前的架构,我们必须使用BX指令来返回。将最后一条指令更改为以下两条指令:
LDMFD sp!, {i, lr}
BX lr最后,让我们来看一个传递超过四个参数的示例。回想一下,ATPCS将前四个参数放在寄存器r0到r3中。后续的参数被放置在堆栈上。
示例6.4定义了一个函数sumof,它可以对任意数量的整数进行求和。参数是要求和的整数的数量,后跟整数列表。sumof函数用汇编语言编写,并且可以接受任意数量的参数。将示例的C部分放在名为main4.c的文件中:
#include <stdio.h>
/* N is the number of values to sum in list ... */
int sumof(int N, ...);
int main(void)
{
printf("Empty sum=%d\n", sumof(0));
printf("1=%d\n", sumof(1,1));
printf("1+2=%d\n", sumof(2,1,2));
printf("1+2+3=%d\n", sumof(3,1,2,3));
printf("1+2+3+4=%d\n", sumof(4,1,2,3,4));
printf("1+2+3+4+5=%d\n", sumof(5,1,2,3,4,5));
printf("1+2+3+4+5+6=%d\n", sumof(6,1,2,3,4,5,6));
}接下来,在一个名为sumof.s的汇编文件中定义sumof函数:
AREA |.text|, CODE, READONLY
EXPORT sumof
N RN 0 ; number of elements to sum
sum RN 1 ; current sum
; int sumof(int N, ...)
sumof
SUBS N, N, #1 ; do we have one element
MOVLT sum, #0 ; no elements to sum!
SUBS N, N, #1 ; do we have two elements
ADDGE sum, sum, r2
SUBS N, N, #1 ; do we have three elements
ADDGE sum, sum, r3
MOV r2, sp ; top of stack
loop
SUBS N, N, #1 ; do we have another element
LDMGEFD r2!, {r3} ; load from the stack
ADDGE sum, sum, r3
BGE loop
MOV r0, sum
MOV pc, lr ; return r0
END该代码会保持要求和的剩余值的计数,即N。前三个值存储在寄存器r1、r2、r3中,其余的值存储在堆栈上。您可以使用以下命令来构建这个示例:
armcc -c main4.c
armasm sumof.s
armlink -o main4.axf main4.o sumof.o6.2 Profiling and Cycle Counting
//性能分析与循环计数
优化过程的第一阶段是确定关键的程序段,并测量它们当前的性能。分析器是一种工具,用于测量每个子例程所花费的时间或处理周期的比例。您可以使用分析器来确定最关键的程序段。循环计数器用于测量特定程序段使用的周期数。您可以使用循环计数器在优化前后对给定的子例程进行基准测试,以评估优化效果。
ADS1.1调试器使用的ARM模拟器称为ARMulator,并提供了性能分析和循环计数的功能。ARMulator分析器通过定期采样程序计数器pc来工作。分析器识别pc所指向的函数,并为遇到的每个函数更新一个命中计数器。另一种方法是使用模拟器的跟踪输出作为分析的源数据。
请确保您了解所使用的分析器的工作原理以及其准确性的限制。如果采样数量太少,基于pc采样的分析器可能会产生无意义的结果。您甚至可以使用定时器中断在硬件系统中实现自己的基于pc采样的分析器来收集pc数据点。请注意,定时器中断会减慢您试图测量的系统!
ARM的实现通常不包含循环计数硬件,因此为了便于测量循环计数,您应该使用带有ARM模拟器的ARM调试器。您可以配置ARMulator来模拟各种不同的ARM核心,并获得多个平台的循环计数基准测试数据。
6.3 Instruction Scheduling
//指令调度
指令执行所需的时间取决于实现的流水线。在本章中,我们假设使用ARM9TDMI流水线定时。您可以在附录D的D.3节中找到相关信息。以下规则总结了ARM9TDMI上常见指令类别的周期计时:
- 根据cpsr中的ARM条件码进行条件判断的指令,如果条件不满足,则执行需要一个周期。如果条件满足,则遵循以下规则:
- 包括立即数移位在内的ALU操作(如加法、减法和逻辑操作)需要一个周期。如果使用寄存器指定的移位,则需要再增加一个周期。如果指令写入pc寄存器,则增加两个周期。
- 加载指令(如LDR和LDM)用于加载N个32位字的内存数据,发出指令需要N个周期,但最后一个加载的字的结果在下一个周期不可用。更新的加载地址在下一个周期可用。这里假设在无缓存系统中存在零等待状态的内存,或者在有缓存系统中存在缓存命中。加载单个值的LDM是例外情况,需要两个周期。如果指令加载pc寄存器,则增加两个周期。
- 加载16位或8位数据的指令(如LDRB、LDRSB、LDRH和LDRSH)发出指令需要一个周期。加载结果在接下来的两个周期内不可用(如下LS1/LS2)。更新的加载地址在下一个周期可用。这里假设在无缓存系统中存在零等待状态的内存,或者在有缓存系统中存在缓存命中。
- 分支指令需要三个周期。
- 存储指令(如STR和STM)存储N个值需要N个周期。这里假设在无缓存系统中存在零等待状态的内存,或者在有缓存系统中存在缓存命中或具有N个空闲条目的写缓冲区。存储单个值的STM是例外情况,需要两个周期。
- 乘法指令的执行周期数取决于乘积中第二个操作数的值(请参阅附录D的表格D.6)。
根据ARM9TDMI流水线的定时规则,不同的指令类别需要不同数量的周期来完成执行。这些周期计时信息对于优化代码的性能很有帮助。
要了解如何在ARM上高效地安排代码,我们需要了解ARM流水线和依赖关系。ARM9TDMI处理器并行执行五个操作:
■ 获取(Fetch):从内存中获取地址为pc处的指令。该指令被加载到核心并按顺序流经核心管道。
■ 解码(Decode):解码上一个周期获取的指令。如果某些输入操作数无法通过任何转发路径获得,则处理器也会从寄存器库中读取它们。
■ ALU:运行上一个周期解码的指令。请注意,该指令最初从地址pc-8(ARM状态)或pc-4(Thumb状态)处获取。通常,这涉及计算数据处理操作的答案或加载、存储、分支操作的地址。一些指令可能在此阶段花费多个周期。例如,乘法和寄存器控制移位操作需要多个ALU周期。
■ LS1:加载或存储由加载或存储指令指定的数据。如果该指令不是加载或存储指令,则该阶段不起作用。
■ LS2:提取并对通过字节或半字加载指令加载的数据进行零扩展或符号扩展。如果该指令不是8位字节或16位半字项的加载指令,则该阶段没有影响。
//ARM9TDMI属于ARMv4系列。
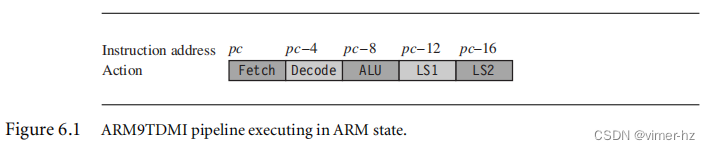
图6.1显示了五级ARM9TDMI流水线的简化功能视图。请注意,乘法和寄存器移位操作未在图中显示。在指令完成五个流水线阶段后,核心将结果写入寄存器文件。请注意,pc指向正在获取的指令的地址。 ALU同时执行从地址pc-8最初获取的指令和从地址pc处获取的指令。
流水线如何影响指令的时间?考虑以下示例。这些示例显示了由于早期指令必须在当前指令可以向下流水线之前完成某个阶段而导致的周期计时方式的更改。
要计算代码块需要多少个周期,请使用附录D中总结一系列ARM内核的周期计时和互锁周期的表格。
如果某条指令需要前一条指令的结果但其结果并不可用,则处理器会暂停运行,这被称为流水线危险或流水线互锁。
例6.5
该示例显示了没有互锁的情况。
ADD r0, r0, r1
ADD r0, r0, r2这个指令对需要两个周期。ALU在一个周期内计算r0 + r1。因此,在第二个周期中,ALU可以使用r0 + r1的结果来计算r0 + r2。
例6.6
该示例显示了由加载-使用引起的一次互锁,需要一个周期。
LDR r1, [r2, #4]
ADD r0, r0, r1这个指令对需要三个周期。在第一个周期中,ALU计算地址r2 + 4,同时并行解码ADD指令。然而,在第二个周期中,ADD指令无法进行,因为加载指令尚未加载r1的值。因此,流水线会在加载指令完成LS1阶段期间暂停一个周期。现在r1已准备好,处理器在第三个周期中执行ALU中的ADD指令。
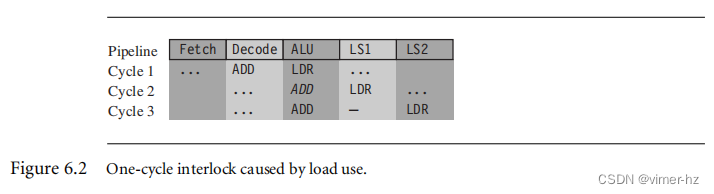
图6.2说明了这种互锁如何影响流水线。处理器将ADD指令在流水线的ALU阶段暂停一个周期,而加载指令完成LS1阶段。我们用斜体的ADD表示这个停顿。由于LDR指令继续向下流水线,但ADD指令被阻塞,它们之间出现了间隙。这个间隙有时被称为流水线气泡。我们用破折号标记了这个气泡。
例6.7
该示例显示了由延迟加载使用引起的一次互锁,需要一个周期。
LDRB r1, [r2, #1]
ADD r0, r0, r2
EOR r0, r0, r1这个指令需要四个周期。虽然ADD在加载字节后的一个周期进行,但是EOR指令无法在第三个周期开始。直到加载指令完成流水线的LS2阶段,r1值才准备好。处理器将EOR指令暂停一个周期。
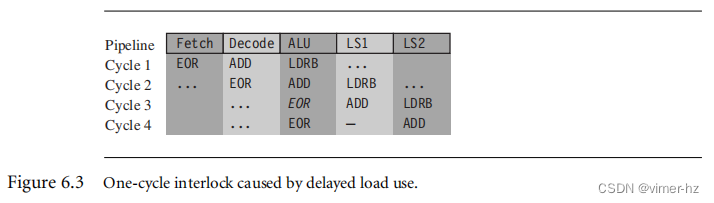
请注意,ADD指令根本不影响时间。无论是否存在该序列,该序列都需要四个周期!图6.3显示了该序列如何通过处理器流水线进行。由于ADD不使用加载的结果r1,因此ADD不会导致任何停顿。
例6.8
该示例展示了为什么分支指令需要三个周期。当跳转到一个新地址时,处理器必须清空流水线。
MOV r1, #1
B case1
AND r0, r0, r1
EOR r2, r2, r3
...
case1
SUB r0, r0, r1这三条执行的指令共需要五个周期。MOV指令在第一个周期执行。在第二个周期,分支指令计算目标地址。这导致核心清空流水线,并使用新的PC值重新填充流水线。重新填充需要两个周期。最后,SUB指令正常执行。图6.4说明了每个周期的流水线状态。当分支发生时,流水线会丢弃分支后面的两条指令。
6.3.1 Scheduling of load instructions
加载指令在编译代码中经常出现,约占所有指令的三分之一。仔细调度加载指令,以避免流水线停顿可以提高性能。编译器会尽力对代码进行调度,但是我们在5.6节中所看到的C语言的别名问题限制了可用的优化。编译器不能将加载指令移到存储指令之前,除非它确定所使用的两个指针不指向同一个地址。
让我们考虑一个内存密集型任务的例子。下面的函数str_tolower将一个以零结尾的字符字符串从in复制到out,并在此过程中将字符串转换为小写。
void str_tolower(char *out, char *in)
{
unsigned int c;
do
{
c = *(in++);
if (c>=’A’ && c<=’Z’)
{
c=c+ (’a’ -’A’);
}
*(out++) = (char)c;
} while (c);
}ADS1.1编译器生成了以下编译输出。请注意,编译器将条件(c >= 'A' && c <= 'Z')优化为检查0 <= c - 'A' <= 'Z' - 'A'。编译器可以使用单个无符号比较执行此检查。
str_tolower
LDRB r2,[r1],#1 ; c = *(in++)
SUB r3,r2,#0x41 ; r3 = c -‘A’
CMP r3,#0x19 ; if (c <=‘Z’-‘A’)
ADDLS r2,r2,#0x20 ; c +=‘a’-‘A’
STRB r2,[r0],#1 ; *(out++) = (char)c
CMP r2,#0 ; if (c!=0)
BNE str_tolower ; goto str_tolower
MOV pc,r14 ; return不幸的是,SUB指令直接使用加载c的LDRB指令之后的c的值。因此,ARM9TDMI流水线将停顿两个周期。由于之后的所有操作都依赖于加载c的值,编译器无法做出更好的处理。然而,使用汇编语言可以通过改变算法的结构来避免这些周期,我们称这两种方法为预加载和展开。
6.3.1.1 Load Scheduling by Preloading
在这种预加载的方法中,我们在前一个循环结束时加载下一个循环所需的数据,而不是在当前循环开始时加载。为了在增加代码大小很少的情况下提高性能,我们不展开循环。
以下是应用预加载方法到str_tolower函数的汇编示例(Example 6.9):
out RN 0 ; pointer to output string
in RN 1 ; pointer to input string
c RN 2 ; character loaded
t RN 3 ; scratch register
; void str_tolower_preload(char *out, char *in)
str_tolower_preload
LDRB c, [in], #1 ; c = *(in++)
loop
SUB t, c, #’A’ ; t = c-’A’
CMP t, #’Z’-’A’ ; if (t <= ’Z’-’A’)
ADDLS c, c, #’a’-’A’ ; c += ’a’-’A’;
STRB c, [out], #1 ; *(out++) = (char)c;
TEQ c, #0 ; test if c==0
LDRNEB c, [in], #1 ; if (c!=0) { c=*in++;
BNE loop
;
goto loop; }
MOV pc, lr
; return预调度版本的指令长度比C版本多一个,但每个内部循环迭代可以节省两个周期。这将在ARM9TDMI上将每个字符的循环从11个周期减少到9个周期,从而提高了1.22倍的速度。ARM架构特别适合这种类型的预加载,因为指令可以有条件地执行。由于循环i正在加载循环i + 1的数据,始终存在第一个和最后一个循环的问题。对于第一个循环,我们可以在循环开始之前插入额外的加载指令来预加载数据。对于最后一个循环,关键是循环不读取任何数据,否则它将读取超出数组的末尾。这可能导致数据异常!在ARM上,我们可以通过使加载指令有条件地执行来轻松解决这个问题。在Example 6.9中,只有在循环还将迭代一次时,才会发生下一个字符的预加载。在最后一个循环中不进行字节加载。
6.3.1.2 Load Scheduling by Unrolling
这种预加载的方法通过展开循环,然后交错执行循环体来实现。例如,我们可以交错执行循环迭代i、i + 1、i + 2。当循环i中的操作结果尚未准备好时,我们可以执行循环i + 1中的操作,避免等待循环i的结果。
以下是将展开循环应用于str_tolower函数的汇编示例(Example 6.10):
out RN 0 ; pointer to output string
in RN 1 ; pointer to input string
ca0 RN 2 ; character 0
t RN 3 ; scratch register
ca1 RN 12 ; character 1
ca2 RN 14 ; character 2
; void str_tolower_unrolled(char *out, char *in)
str_tolower_unrolled
STMFD sp!, {lr} ; function entry
loop_next3
LDRB ca0, [in], #1 ; ca0 = *in++;
LDRB ca1, [in], #1 ; ca1 = *in++;
LDRB ca2, [in], #1 ; ca2 = *in++;
SUB t, ca0, #’A’ ; convert ca0 to lower case
CMP t, #’Z’-’A’
ADDLS ca0, ca0, #’a’-’A’
SUB t, ca1, #’A’ ; convert ca1 to lower case
CMP t, #’Z’-’A’
ADDLS ca1, ca1, #’a’-’A’
SUB t, ca2, #’A’ ; convert ca2 to lower case
CMP t, #’Z’-’A’
ADDLS ca2, ca2, #’a’-’A’
STRB ca0, [out], #1 ; *out++ = ca0;
TEQ ca0, #0
; if (ca0!=0)
STRNEB ca1, [out], #1 ; *out++ = ca1;
TEQNE ca1, #0
; if (ca0!=0 && ca1!=0)
STRNEB ca2, [out], #1 ; *out++ = ca2;
TEQNE ca2, #0
; if (ca0!=0 && ca1!=0 && ca2!=0)
BNE loop_next3 ; goto loop_next3;
LDMFD sp!, {pc} ; return;在我们目前所看到的实现中,这个循环是最高效的。在ARM9TDMI上,每个字符需要七个周期。这使得str_tolower函数的速度提高了1.57倍。同样,正是ARM指令的条件性质使得这种优化成为可能。我们使用条件指令来避免存储超出字符串末尾的字符。
然而,Example 6.10中的改进也有一些代价。该例程的代码大小超过原始实现的两倍。我们假设您可以读取输入字符串末尾之后的两个字符,但如果字符串正好位于可用RAM的末尾,则可能不成立,因为读取超出末尾将导致数据异常。此外,对于非常短的字符串,性能可能会较慢,因为(1)堆叠lr会导致额外的函数调用开销,(2)该例程可能会处理多达两个字符,然后才发现它们位于字符串末尾之外。
对于应用程序中时间关键的部分,您应该使用展开循环的这种调度方式,前提是您知道数据大小较大。如果在编译时还知道数据的大小,那么可以解决读取超出数组末尾的问题。
总结指令调度:
- ARM核心具有流水线体系结构。流水线可能会延迟某些指令的结果多个周期。如果您在后续指令中使用这些结果作为源操作数,处理器将插入停顿周期,直到该值准备好。
- 在许多实现中,加载和乘法指令的结果会有延迟。您可以参考附录D,了解特定ARM处理器核心的时钟周期和延迟时机。
- 您有两种软件方法可以消除加载指令后的互锁:您可以预加载,使循环i加载循环i + 1的数据,或者您可以展开循环并交错执行循环i和i + 1的代码。
6.4 Register Allocation
//寄存器分配
您可以使用16个可见的ARM寄存器中的14个来存储通用数据。另外两个寄存器是栈指针r13和程序计数器r15。为了使函数符合ATPCS规范,它必须保留寄存器r4到r11的被调用者值。ATPCS还指定堆栈应该是8字节对齐的;因此,如果调用子程序,您必须保持这种对齐。以下是用于需要许多寄存器的优化汇编例程的模板:
routine_name
STMFD sp!, {r4-r12, lr} ; stack saved registers
; body of routine
; the fourteen registers r0-r12 and lr are available
LDMFD sp!, {r4-r12, pc} ; restore registers and return我们在将r12入栈的唯一目的是为了保持堆栈8字节对齐。如果您的例程不调用其他ATPCS例程,则无需将r12入栈。对于ARMv5及以上版本,即使从Thumb代码中调用,也可以使用上述模板。如果您的例程可能被ARMv4T处理器上的Thumb代码调用,请按如下方式修改模板:
routine_name
STMFD sp!, {r4-r12, lr} ; stack saved registers
; body of routine
; registers r0-r12 and lr available
LDMFD sp!, {r4-r12, lr} ; restore registers
BX lr
; return, with mode switch在这一部分中,我们将研究如何为寄存器密集型任务分配变量到寄存器号码,如何使用超过14个局部变量,并如何充分利用可用的14个寄存器。
6.4.1 Allocating Variables to Register Numbers
当您编写汇编例程时,最好从变量的名称开始使用,而不是显式的寄存器号码。这样可以轻松地更改变量到寄存器号码的分配方式。当它们的使用不重叠时,甚至可以使用相同的物理寄存器号码的不同寄存器名称。寄存器名称提高了优化代码的清晰度和可读性。
在大多数情况下,ARM操作在寄存器号码方面是正交的。换句话说,特定的寄存器号码没有特定的作用。如果在例程中交换两个寄存器Ra和Rb的所有出现次数,则该例程的功能不会改变。
但是,有几种情况下寄存器的物理编号很重要:
■ 参数寄存器。ATPCS规范定义将函数的前四个参数放置在寄存器r0到r3中。其他参数放置在堆栈上。返回值必须放置在r0中。
■ 在加载或存储多个寄存器时使用的寄存器。加载和存储多个指令LDM和STM按升序寄存器号码的顺序操作寄存器列表。如果寄存器列表中出现r0和r1,则处理器将始终使用较低的地址加载或存储r0,以此类推。
■ 加载和存储双字。在ARMv5E中引入的LDRD和STRD指令操作具有连续寄存器号码的一对寄存器Rd和Rd + 1。此外,Rd必须是偶数寄存器号码。
在编写汇编代码时,为了示例说明如何分配寄存器,假设我们想要通过k位将一个包含N位的数组向内存上方移动。为简单起见,假设N很大且是256的倍数。还假设 0 ≤ k < 32,并且输入和输出指针是字对齐的。这种操作在处理多精度数字的算术中很常见,我们希望将其乘以2的k次方。它还可用于在不同的位或字节对齐方式之间进行块复制。例如,C库函数memcpy可以使用该例程仅使用字访问来复制字节数组。
C例程shift_bits实现了对N位数据进行简单的k位移位。它返回移位后剩余的k位。
unsigned int shift_bits(unsigned int *out, unsigned int *in,
unsigned int N, unsigned int k)
{
unsigned int carry=0, x;
do
{
x = *in++;
*out++ = (x << k) | carry;
carry = x >> (32-k);
N -= 32;
} while (N);
return carry;
}为了提高效率,显而易见的方法是展开循环,每次处理8个长度为256位的字,这样我们可以使用加载和存储多个操作一次性加载和存储8个字,以达到最大的效率。在考虑寄存器编号之前,我们编写以下汇编代码:
shift_bits
STMFD sp!, {r4-r11, lr} ; save registers
RSB kr, k, #32
; kr = 32-k;
MOV carry, #0
loop
LDMIA in!, {x_0-x_7}
; load 8 words
ORR y_0, carry, x_0, LSL k ; shift the 8 words
MOV carry, x_0, LSR kr
ORR y_1, carry, x_1, LSL k
MOV carry, x_1, LSR kr
ORR y_2, carry, x_2, LSL k
MOV carry, x_2, LSR kr
ORR y_3, carry, x_3, LSL k
MOV carry, x_3, LSR kr
ORR y_4, carry, x_4, LSL k
MOV carry, x_4, LSR kr
ORR y_5, carry, x_5, LSL k
MOV carry, x_5, LSR kr
ORR y_6, carry, x_6, LSL k
MOV carry, x_6, LSR kr
ORR y_7, carry, x_7, LSL k
MOV carry, x_7, LSR kr
STMIA out!, {y_0-y_7} ; store 8 words
SUBS N, N, #256
; N -= (8 words * 32 bits)
BNE loop
; if (N!=0) goto loop;
MOV r0, carry
; return carry;
LDMFD sp!, {r4-r11, pc}现在来看寄存器分配。为了避免输入参数需要移动寄存器,我们可以立即分配寄存器。
out RN 0
in RN 1
N RN 2
k RN 3为了使加载多个操作能够正常工作,我们必须将x0到x7逐渐分配给递增的寄存器编号,以及将y0到y7类似地分配。请注意,在开始y1之前,我们会先完成x0的分配。一般来说,我们可以将xn分配给与yn+1相同的寄存器。因此,分配如下:
x_0 RN 5
x_1 RN 6
x_2 RN 7
x_3 RN 8
x_4 RN 9
x_5 RN 10
x_6 RN 11
x_7 RN 12
y_0 RN 4
y_1 RN x_0
y_2 RN x_1
y_3 RN x_2
y_4 RN x_3
y_5 RN x_4
y_6 RN x_5
y_7 RN x_6我们快要完成了,但是还有一个问题。还剩下两个变量carry和kr,但只剩下一个空闲寄存器lr。当寄存器用完时,有几种可能的解决方法:
■ 减少每个循环中操作的数量,以减少所需的寄存器数量。在这种情况下,我们可以在每个加载多个操作中加载四个字,而不是八个。
■ 使用栈来存储最不常用的值,以释放更多的寄存器。在这种情况下,我们可以将循环计数器N存储在栈上。(有关将寄存器交换到栈的更多详细信息,请参见第6.4.2节。)
■ 更改代码实现以释放更多的寄存器。这是我们在下面考虑的解决方案。(更多示例请参见第6.4.3节。)
通常,我们会多次迭代执行实现和寄存器分配的过程,直到算法适配为可用的14个寄存器。在这种情况下,我们注意到carry值实际上不需要保持在同一个寄存器中!我们可以开始时将carry值分配给y0,然后当x0不再需要时将其移动到y1,以此类推。我们通过将kr分配给lr并重新编码来完成程序,以使carry不再需要。
Example 6.11 以下汇编代码展示了我们最终的shift_bits例程。它使用了所有可用的14个ARM寄存器。
kr RN lr
shift_bits
STMFD sp!, {r4-r11, lr} ; save registers
RSB kr, k, #32
; kr = 32-k;
MOV y_0, #0
; initial carry
loop
LDMIA in!, {x_0-x_7} ; load 8 words
ORR y_0, y_0, x_0, LSL k ; shift the 8 words
MOV y_1, x_0, LSR kr ; recall x_0 = y_1
ORR y_1, y_1, x_1, LSL k
MOV y_2, x_1, LSR kr
ORR y_2, y_2, x_2, LSL k
MOV y_3, x_2, LSR kr
ORR y_3, y_3, x_3, LSL k
MOV y_4, x_3, LSR kr
ORR y_4, y_4, x_4, LSL k
MOV y_5, x_4, LSR kr
ORR y_5, y_5, x_5, LSL k
MOV y_6, x_5, LSR kr
ORR y_6, y_6, x_6, LSL k
MOV y_7, x_6, LSR kr
ORR y_7, y_7, x_7, LSL k
STMIA out!, {y_0-y_7} ; store 8 words
MOV y_0, x_7, LSR kr
SUBS N, N, #256
; N -= (8 words * 32 bits)
BNE loop
; if (N!=0) goto loop;
MOV r0, y_0
; return carry;
LDMFD sp!, {r4-r11, pc}6.4.2 Using More than 14 Local Variables
如果在例程中需要超过14个32位本地变量,那么必须将一些变量存储在堆栈上。标准的处理过程是从算法最内层的循环开始向外工作,因为最内层的循环具有最大的性能影响。
Example 6.12展示了三个嵌套循环,每个循环都需要从其周围的循环继承的状态信息。(有关循环结构的更多想法和示例,请参见第6.6节。)
nested_loops
STMFD sp!, {r4-r11, lr}
; set up loop 1
loop1
STMFD sp!, {loop1 registers}
; set up loop 2
loop2
STMFD sp!, {loop2 registers}
; set up loop 3
loop3
; body of loop 3
B{cond} loop3
LDMFD sp!, {loop2 registers}
; body of loop 2
B{cond} loop2
LDMFD sp!, {loop1 registers}
; body of loop 1
B{cond} loop1
LDMFD sp!, {r4-r11, pc}当使用示例6.12中的结构时,您可能会发现内层循环的寄存器不足,这时需要将内层循环的变量置换到堆栈中。由于如果使用数字作为堆栈地址偏移量,汇编代码非常难以维护和调试,所以汇编器提供了自动分配变量到堆栈的过程。
Example 6.13展示了如何使用ARM汇编器指令MAP(别名∧)和FIELD(别名#)在处理器堆栈上定义和分配变量和数组的空间。该指令类似于C语言中的struct操作符。
MAP 0 ; map symbols to offsets starting at offset 0
a FIELD 4 ; a is 4 byte integer (at offset 0)
b FIELD 2 ; b is 2 byte integer (at offset 4)
c FIELD 2 ; c is 2 byte integer (at offset 6)
d FIELD 64 ; d is an array of 64 characters (at offset 8)
length FIELD 0 ; length records the current offset reached
example
STMFD sp!, {r4-r11, lr} ; save callee registers
SUB sp, sp, #length ; create stack frame
; ...
STR r0, [sp, #a]
; a = r0;
LDRSH r1, [sp, #b] ; r1 = b;
ADD r2, sp, #d ; r2 = &d[0]
; ...
ADD sp, sp, #length ; restore the stack pointer
LDMFD sp!, {r4-r11, pc} ; return6.4.3 Making the Most of Available Registers
在像ARM这样的加载存储架构中,相对于内存中保存的值,访问寄存器中保存的值更加高效。有几种技巧可以将多个小于32位长度的变量装入一个32位寄存器中,从而减小代码大小并提高性能。本节介绍了三个示例,展示了如何将多个变量打包到一个ARM寄存器中。
示例6.14假设我们希望通过可编程增量遍历数组。常见的例子是以不同的速率遍历音频样本以产生不同音高的音符。我们可以使用以下C代码来表达这个过程:
sample = table[index];
index += increment;通常索引(index)和增量(increment)的值都小到可以使用16位来保存。我们可以将这两个变量打包到一个32位的变量indinc中:
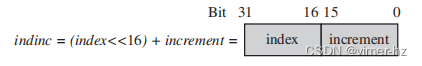
这段C代码可以转换成汇编代码,并使用单个寄存器来保存indinc的值:
LDRB sample, [table, indinc, LSR#16] ; table[index]
ADD indinc, indinc, indinc, LSL#16 ; index+=increment请注意,如果索引(index)和增量(increment)是16位的值,将索引放在indinc的高16位中可以正确实现16位的循环。换句话说,index = (short)(index + increment)。如果您在使用一个循环缓冲区时需要从末尾回到开头(通常称为循环缓冲区),这将非常有用。
示例6.15说明了如何使用一个寄存器来表示移位数量,并结合循环计数器来将一个包含40个元素的数组向右移动shift位。我们定义了一个新的变量cntshf,它将count和shift组合在一起:

out RN 0 ; address of the output array
in RN 1 ; address of the input array
cntshf RN 2 ; count and shift right amount
x RN 3 ; scratch variable
; void shift_right(int *out, int *in, unsigned shift);
shift_right
ADD cntshf, cntshf, #39 << 8 ; count = 39
shift_loop
LDR x, [in], #4
SUBS cntshf, cntshf, #1 << 8 ; decrement count
MOV x, x, ASR cntshf ; shift by shift
STR x, [out], #4
BGE shift_loop
; continue if count>=0
MOV pc, lr示例6.16
如果您处理的是8位或16位值的数组,有时可以通过将多个值打包到单个32位寄存器中来一次性处理多个值。这称为单指令多数据(SIMD)处理。
ARMv5及其之前的ARM架构版本不直接支持SIMD操作。然而,在某些情况下仍然可以实现SIMD类型的紧凑性。第6.6节展示了如何将多个循环值存储在单个寄存器中。这里我们介绍一个图形处理的示例,演示如何使用常规的ADD和MUL指令来处理图像中的多个8位像素,以实现一些SIMD操作。
假设我们想要合并两个图像X和Y以生成一个新图像Z。分别用xn、yn和zn表示这些图像中第n个8位像素。假设0 ≤ a ≤ 256是一个缩放因子。为了合并这些图像,我们设置:
![]()
换句话说,图像Z是将图像X的强度按照 a/256 缩放后与图像Y按照 1 - (a/256) 缩放后相加得到的。请注意:
![]()
因此,每个像素需要进行减法、乘法、移位相加和右移操作。为了一次处理多个像素,我们使用字加载指令一次性加载四个像素。我们使用括号表示法来表示多个值打包到同一个字中:
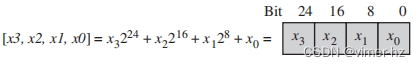
然后,我们使用与掩码寄存器的AND操作将8位数据解包并提升为16位数据。我们使用如下的表示法:
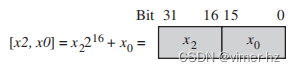
请注意,即使对于有符号的值 [a,b] + [c,d] = [a + b,c + d],如果我们使用数学方程 a216 + b 来解释 [a,b]。因此,我们可以使用常规算术指令对这些值执行SIMD操作。
下面的代码展示了如何使用只有两个乘法来一次处理四个像素。该代码假定一个大小为176×144的QCIF图像。
IMAGE_WIDTH EQU 176 ; QCIF width
IMAGE_HEIGHT EQU 144 ; QCIF height
pz RN 0 ; pointer to destination image (word aligned)
px RN 1 ; pointer to first source image (word aligned)
py RN 2 ; pointer to second source image (word aligned)
a RN 3 ; 8-bit scaling factor (0-256)
xx RN 4 ; holds four x pixels [x3, x2, x1, x0]
yy RN 5 ; holds four y pixels [y3, y2, y1, y0]
x RN 6 ; holds two expanded x pixels [x2, x0]
y RN 7 ; holds two expanded y pixels [y2, y0]
z RN 8 ; holds four z pixels [z3, z2, z1, z0]
count RN 12 ; number of pixels remaining
mask RN 14 ; constant mask with value 0x00ff00ff
; void merge_images(char *pz, char *px, char *py, int a)
merge_images
STMFD sp!, {r4-r8, lr}
MOV count, #IMAGE_WIDTH*IMAGE_HEIGHT
LDR mask, =0x00FF00FF ; [ 0, 0xFF, 0, 0xFF ]
merge_loop
LDR xx, [px], #4 ; [ x3, x2, x1, x0 ]
LDR yy, [py], #4 ; [ y3, y2, y1, y0 ]
AND x, mask, xx ; [ 0, x2, 0, x0 ]
AND y, mask, yy ; [ 0, y2, 0, y0 ]
SUB x, x, y
; [ (x2-y2), (x0-y0) ]
MUL x, a, x
; [ a*(x2-y2), a*(x0-y0) ]
ADD x, x, y, LSL#8 ; [ w2, w0 ]
AND z, mask, x, LSR#8 ; [ 0, z2, 0, z0 ]
AND x, mask, xx, LSR#8 ; [ 0, x3, 0, x1 ]
AND y, mask, yy, LSR#8 ; [ 0, y3, 0, y1 ]
SUB x, x, y
; [ (x3-y3), (x1-y1) ]
MUL x, a, x
; [ a*(x3-y3), a*(x1-y1) ]
ADD x, x, y, LSL#8 ; [ w3, w1 ]
AND x, mask, x, LSR#8 ; [ 0, z3, 0, z1 ]
ORR z, z, x, LSL#8 ; [ z3, z2, z1, z0 ]
STR z, [pz], #4 ; store four z pixels
SUBS count, count, #4
BGT merge_loop
LDMFD sp!, {r4-r8, pc}
因此,通过分别取最高位和最低位的16位部分,可以轻松将值 [w2,w0] 分离为 w2 和 w0。我们成功地使用32位的加载、存储和数据操作一次处理了四个8位像素,以并行方式执行操作。
总结 寄存器分配:
■ ARM有14个可用于通用目的的寄存器:r0到r12和r14。栈指针r13和程序计数器r15不能用于通用数据。操作系统中断通常假设用户模式下的r13指向一个有效的堆栈,因此不要试图重新使用r13。
■ 如果需要超过14个局部变量,请将变量转移到堆栈上,从最内层循环向外工作。
■ 在编写汇编程序时,使用寄存器名称而不是物理寄存器号码。这样可以更容易重新分配寄存器并维护代码。
■ 为了减轻寄存器压力,有时可以将多个值存储在同一个寄存器中。例如,可以将循环计数器和位移存储在同一个寄存器中。还可以将多个像素存储在一个寄存器中。
6.5 Conditional Execution
处理器核心可以有条件地执行大多数ARM指令。这种条件执行基于15个条件码之一。如果不指定条件,汇编器默认为始终执行条件(AL)。其他14个条件分为七对互补条件。条件依赖于存储在cpsr寄存器中的四个条件码标志N、Z、C、V。请参见附录A中的表A.2,了解可能的ARM条件的列表。还请参阅2.2.6节和3.8节,了解条件执行的介绍。默认情况下,ARM指令不会更新ARM cpsr中的N、Z、C、V标志。对于大多数指令,要更新这些标志,需要在指令助记符后附加一个S后缀。例外是不写入目标寄存器的比较指令。它们唯一的目的是更新标志,因此不需要S后缀。通过结合条件执行和条件设置标志,您可以实现不需要分支的简单if语句。这提高了效率,因为分支可能需要很多周期,并且减少了代码大小。
示例6.17:
以下C代码将无符号整数0 ≤ i ≤ 15转换为十六进制字符c:
if (i<10)
{
c=i+ ‘0’;
}
else
{
c=i+ ‘A’-10;
}我们可以使用条件执行而不是条件分支来将其写成汇编代码:
CMP i, #10
ADDLO c, i, #‘0’
ADDHS c, i, #‘A’-10该序列有效,因为第一个ADD不会改变条件码。第二个ADD仍然取决于比较的结果而进行条件执行。6.3.1节展示了类似的使用条件执行将字符转换为小写的示例。条件执行在级联条件方面更加强大。
示例6.18:
以下C代码用于判断c是否是元音字母:
if (c==‘a’ || c==‘e’ || c==‘i’ || c==‘o’ || c==‘u’)
{
vowel++;
}在汇编中,您可以使用条件比较来编写此代码:
TEQ c, #‘a’
TEQNE c, #‘e’
TEQNE c, #‘i’
TEQNE c, #‘o’
TEQNE c, #‘u’
ADDEQ vowel, vowel, #1一旦TEQ比较中的任何一个检测到匹配,cpsr中的Z标志就会被设置。接下来的TEQNE指令没有效果,因为它们是在Z = 0的条件下进行的。下一个有效的指令是ADDEQ,它会增加元音字母计数器。您可以在if语句中的所有比较都是相同类型时使用此方法。
示例6.19:
考虑以下代码,用于检测c是否为字母:
if ((c>=‘A’ && c<=‘Z’) || (c>=‘a’ && c<=‘z’))
{
letter++;
}要有效地实现此代码,我们可以使用加法或减法将每个范围移动到0 ≤ c ≤ limit的形式。然后,我们使用无符号比较来检测此范围,并使用条件比较来连接范围。以下汇编代码有效地实现了此操作:
SUB temp, c, #‘A’
CMP temp, #‘Z’-‘A’
SUBHI temp, c, #‘a’
CMPHI temp, #‘z’-‘a’
ADDLS letter, letter, #1
对于涉及开关的更复杂的决策,请参阅第6.8节。注意,逻辑操作AND和OR之间存在标准的逻辑关系,如表6.1所示。您可以通过反转涉及OR的逻辑表达式来得到涉及AND的表达式,这在简化或重新排列逻辑表达式时通常很有用。
总结条件执行:
- 您可以使用条件执行来实现大多数if语句。这比使用条件分支更高效。
- 您可以使用几个相似条件的逻辑AND或OR来实现if语句,使用的比较指令本身也是有条件的。
6.6 Looping Constructs
大多数对性能至关重要的例程将包含一个循环。在第5.3节中我们看到,在ARM架构中,循环在倒计时至零时速度最快。本节描述了如何在汇编中有效地实现这些循环。我们还会看一些将循环展开以获得最大性能的示例。
6.6.1 Decremented Counted Loops
//递减计数循环
对于一个递减循环,包含N个迭代,循环计数器i从N递减到1(包括1)。循环在i = 0时终止。一个高效的实现方式是:
MOV i, N
loop
; loop body goes here and i=N,N-1,...,1
SUBS i, i, #1
BGT loop循环开销由一次减法设置条件码和一次条件分支组成。在ARM7和ARM9上,每个循环的开销为四个时钟周期。如果i是一个数组索引,那么您可能希望从N-1递减到0(包括0),以便可以访问数组元素0。您可以使用不同的条件分支来实现这一点:
SUBS i, N, #1
loop
; loop body goes here and i=N-1,N-2,...,0
SUBS i, i, #1
BGE loop在这种排列中,Z标志位在循环的最后一次迭代中被设置,其他迭代中被清除。如果最后一次循环有任何不同之处,我们可以使用EQ和NE条件来实现这一点。例如,如果您为下一个循环预加载数据(如第6.3.1.1节所讨论的),那么您希望在最后一个循环中避免预加载。您可以将所有预加载操作都条件地执行NE,就像在第6.3.1.1节中一样。
没有必要在每个循环中递减一个。假设我们需要N/3次循环。与其试图将N除以三,更高效的做法是在每次迭代中从循环计数器中减去三:
MOV i, N
loop
; loop body goes here and iterates (round up)(N/3) times
SUBS i, i, #3
BGT loop6.6.2 Unrolled Counted Loops
//展开的计数循环
这将带我们进入循环展开的主题。循环展开通过多次执行循环体来减少循环开销。然而,还有一些问题需要解决。如果循环计数不是展开数量的倍数怎么办?如果循环计数小于展开数量怎么办?我们在第5.3节中研究了这些问题的C代码。在本节中,我们将看看如何在汇编中处理这些问题。
我们以C库函数memset作为案例研究。该函数将地址为s处的N个字节设置为字节值c。为了提高效率,我们将研究如何展开循环而不对输入操作数添加额外限制。我们的memset版本将具有以下C原型:
void my_memset(char *s, int c, unsigned int N);
为了在大的N上提高效率,我们需要使用STR或STM指令一次写入多个字节。因此,我们的首要任务是对齐数组指针s。然而,只有在N足够大的情况下才值得这样做。我们还不知道“足够大”是什么意思,但假设我们可以选择一个阈值T1,并且只在N≥T1时才对齐数组。显然,T1 ≥ 3,因为如果我们没有四个字节要写入,对齐就没有意义!
假设我们已经对齐了数组s。我们可以使用存储多个指令来高效地设置内存。例如,我们可以使用四个存储多个指令,每个指令存储八个字,以在每次循环中设置128个字节。但是,只有当N ≥ T2 ≥ 128时,这样做才值得,其中T2是稍后确定的另一个阈值。
最后,我们剩下要设置的N < T2个字节。我们可以使用STR以4个字节的块写入字节,直到N < 4。然后,我们可以使用STRB单独写入字节到数组末尾来完成。
例子6.20
这个例子展示了循环展开的memset例程。我们使用一行虚线将与前文段落对应的三个部分分隔开来。直到我们确定了T1和T2的最佳值之前,例程才算完成。
s RN 0 ; current string pointer
c RN 1 ; the character to fill with
N RN 2 ; the number of bytes to fill
c_1 RN 3 ; copies of c
c_2 RN 4
c_3 RN 5
c_4 RN 6
c_5 RN 7
c_6 RN 8
c_7 RN 12
; void my_memset(char *s, unsigned int c, unsigned int N)
my_memset
;-----------------------------------------------
; First section aligns the array
CMP N, #T_1 ; We know that T_1>=3
BCC memset_1ByteBlk ; if (N<T_1) goto memset_1ByteBlk
ANDS c_1, s, #3 ; find the byte alignment of s
BEQ aligned ; branch if already aligned
RSB c_1, c_1, #4 ; number of bytes until alignment
SUB N, N, c_1 ; number of bytes after alignment
CMP c_1, #2
STRB c, [s], #1
STRGEB c, [s], #1 ; if (c_1>=2) then output byte
STRGTB c, [s], #1 ; if (c_1>=3) then output byte
aligned
;the s array is now aligned
ORR c, c, c, LSL#8 ; duplicate the character
ORR c, c, c, LSL#16 ; to fill all four bytes of c
;-----------------------------------------------
; Second section writes blocks of 128 bytes
CMP N, #T_2 ; We know that T_2 >= 128
BCC memset_4ByteBlk ; if (N<T_2) goto memset_4ByteBlk
STMFD sp!, {c_2-c_6} ; stack scratch registers
MOV c_1, c
MOV c_2, c
MOV c_3, c
MOV c_4, c
MOV c_5, c
MOV c_6, c
MOV c_7, c
SUB N, N, #128 ; bytes left after next block
loop128 ; write 32 words = 128 bytes
STMIA s!, {c, c_1-c_6, c_7} ; write 8 words
STMIA s!, {c, c_1-c_6, c_7} ; write 8 words
STMIA s!, {c, c_1-c_6, c_7} ; write 8 words
STMIA s!, {c, c_1-c_6, c_7} ; write 8 words
SUBS N, N, #128 ; bytes left after next block
BGE loop128
ADD N, N, #128 ; number of bytes left
LDMFD sp!, {c_2-c_6} ; restore corrupted registers
;--------------------------------------------
; Third section deals with left over bytes
memset_4ByteBlk
SUBS N, N, #4 ; try doing 4 bytes
loop4 ; write 4 bytes
STRGE c, [s], #4
SUBGES N, N, #4
BGE loop4
ADD N, N, #4 ; number of bytes left
memset_1ByteBlk
SUBS N, N, #1
loop1 ; write 1 byte
STRGEB c, [s], #1
SUBGES N, N, #1
BGE loop1
MOV pc, lr ; finished so return我们需要找到阈值T1和T2的最佳值。为了确定这些值,我们需要分析不同范围N的循环计数。由于该算法操作的是大小为128字节、4字节和1字节的块,因此我们首先将N分解为这些块大小的组合:
N = 128Nh + 4Nm + Nl,其中0 ≤ Nm < 32,0 ≤ Nl < 4
现在我们将其分为三种情况。要了解这些循环计数的详细信息,您需要参考附录D中的指令周期计时数据。
■ 情况0 ≤ N < T1:在ARM9TDMI上,该例程需要5N + 6个周期(包括返回)。
■ 情况T1 ≤ N < T2:如果数组s是对齐的,第一个算法块需要6个周期;否则需要10个周期。假设每种对齐的可能性相等,平均为(6 + 10 + 10 + 10)/4 = 9个周期。第二个算法块需要6个周期。最后一个块需要5(32Nh + Nm) + 5(Nl + Zl) + 2个周期,其中Zl为1如果Nl = 0,否则为0。该情况下的总周期数为5(32Nh + Nm + Nl + Zl) + 17。
■ 情况N ≥ T2:与前一种情况类似,第一个算法块的平均周期数为9个。第二个算法块需要36Nh + 21个周期。最后一个算法块需要5(Nm + Zm + Nl + Zl) + 2个周期,其中Zm为1如果Nm为0,否则为0。该情况下的总周期数为36Nh + 5(Nm + Zm + Nl + Zl) + 32。
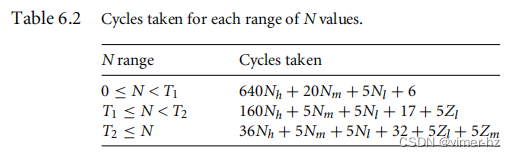
表6.2总结了这些结果。比较三行数据可以清楚地看到,只要Nm ≥ 1,并且Nm ≠ 1或者Nl ≠ 0,第二行的循环计数就优于第一行。我们将T1设置为5,选择第一行和第二行中最佳的循环计数。第三行只要Nh ≥ 1,就优于第二行。因此,我们将T2设置为128。
这个详细的例子向您展示了如何使用阈值来展开任何重要的循环,并在可能的输入值范围内提供良好的性能。
6.6.3 Multiple Nested Loops
在维护多个嵌套循环时,实际上只需要一个循环计数器,或更准确地说,只要每个循环计数所需的位数之和不超过32位。我们可以将这些循环计数合并到一个寄存器中,将最内层循环计数放置在最高位上。本节将通过示例展示如何做到这一点。我们将确保循环计数从最大值减1递减到0,以产生负结果来终止循环。
示例6.21展示了如何将三个循环计数合并为一个单一的循环计数。假设我们希望将矩阵B乘以矩阵C得到矩阵A,其中A、B、C具有以下常量维度。我们假设R、S、T相对较大,但小于256。
为了将这三个循环计数合并为一个单一的循环计数,我们可以在寄存器中为每个循环计数分配一定数量的位。在这种情况下,由于R、S、T小于256,我们可以给每个循环计数分配8位。
假设循环计数寄存器为L,最高位对应于最内层循环计数。为了初始化循环计数,我们将L的值设置为"R << 16 | S << 8 | T"。
在嵌套循环的执行过程中,我们每次迭代都将循环计数L减1,直到它达到0或变为负数为止。这样可以确保循环从其最大值减去1递减至0,循环通过产生负结果来终止。
通过将循环计数合并到一个单一的循环计数寄存器中,我们可以只使用一个循环计数器高效地维护和控制多个嵌套循环。
Matrix A:
R rows × T columns
Matrix B:
R rows × S columns
Matrix C:
S rows × T columns我们用相同名称的小写指针来表示每个矩阵,指向按行组织的字数组。例如,第i行第j列的元素A[i,j]在字节地址 &A[i,j]=a+ 4*(i*T+j)。
矩阵乘法的一个简单的C实现使用三个嵌套循环i、j和k:
#define R 40
#define S 40
#define T 40
void ref_matrix_mul(int *a, int *b, int *c)
{
unsigned int i,j,k;
int sum;
for (i=0; i<R; i++)
{
for (j=0; j<T; j++)
{
/* calculate a[i,j] */
sum = 0;
for (k=0; k<S; k++)
{
/* add b[i,k]*c[k,j] */
sum += b[i*S+k]*c[k*T+j];
}
a[i*T+j] = sum;
}
}
}这里有很多提高效率的方式,比如删除地址索引计算,但我们将集中精力于循环结构。我们分配一个寄存器计数器count,其中包含三个循环计数器i、j和k:
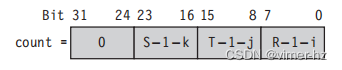
请注意,S - 1 - k 从 S - 1 递减到 0,而不是像 k 那样从 0 递增到 S - 1。下面的汇编代码使用寄存器 count 中的单个计数器来实现矩阵乘法:
R EQU 40
S EQU 40
T EQU 40
a RN 0 ; points to an R rows × T columns matrix
b RN 1 ; points to an R rows × S columns matrix
c RN 2 ; points to an S rows × T columns matrix
sum RN 3
bval RN 4
cval RN 12
count RN 14
matrix_mul ; void matrix_mul(int *a, int *b, int *c)
STMFD sp!, {r4, lr}
MOV count, #(R-1) ; i=0
loop_i
ADD count, count, #(T-1) << 8 ; j=0
loop_j
ADD count, count, #(S-1) << 16 ; k=0
MOV sum, #0
loop_k
LDR bval, [b], #4 ; bval = B[i,k], b=&B[i,k+1]
LDR cval, [c], #4*T ; cval = C[k,j], c=&C[k+1,j]
SUBS count, count, #1 << 16 ; k++
MLA sum, bval, cval, sum ; sum += bval*cval
BPL loop_k ; branch if k<=S-1
STR sum, [a], #4 ; A[i,j] = sum, a=&A[i,j+1]
SUB c, c, #4*S*T ; c = &C[0,j]
ADD c, c, #4 ; c = &C[0,j+1]
ADDS count, count, #(1 << 16)-(1 << 8) ; zero (S-1-k), j++
SUBPL b, b, #4*S ; b = &B[i,0]
BPL loop_j ; branch if j<=T-1
SUB c, c, #4*T ; c = &C[0,0]
ADDS count, count, #(1 >> 8)-1 ; zero (T-1-j), i++
BPL loop_i ; branch if i<=R-1
LDMFD sp!, {r4, pc}上述的结构比起朴素实现方式节省了两个寄存器。首先,我们递减位于16到23位的计数器,直到结果为负数为止。这实现了k循环,从S-1递减到0(包括0)。一旦结果为负数,代码会加上216来清除16到31位的值。然后我们减去28来递减位于8到15位的计数器,实现j循环。我们可以使用单个ARM指令高效地编码常量216 - 28 = 0xFF00。现在,8到15位的值从T-1递减到0。当加法和减法的结果为负数时,我们就完成了j循环。对于i循环,我们重复相同的过程。ARM可以处理加法和减法指令中的广泛范围的旋转常量,使得这种方案非常高效。
//可以试下C语言和汇编的例子,写成testbed,测试下perf
6.6.4 Other Counted Loops
您可能希望在循环中将循环计数器的值作为计算的输入。并不总是希望从N递减到1或从N-1递减到0。例如,您可能希望逐个从数据寄存器中选择位,这种情况下您可能需要一个每次迭代都加倍的二次幂掩码。
以下子节展示了以不同模式计数的有用循环结构。它们使用只有一条指令与一个分支相结合来实现循环。
6.6.4.1 Negative Indexing
这个循环结构以步长为 STEP,从-N递减到0(包括或不包括0)计数。
RSB i, N, #0 ; i=-N
loop
; loop body goes here and i=-N,-N+STEP,...,
ADDS i, i, #STEP
BLT loop
; use BLT or BLE to exclude 0 or not6.6.4.2 Logarithmic Indexing
这个循环结构以2的幂次从2N递减到1进行计数。例如,如果 N = 4,则计数为 16、8、4、2、1。
MOV i, #1
MOV i, i, LSL N
loop
; loop body
MOVS i, i, LSR#1
BNE loop下面的循环结构从N位掩码递减到1位掩码。例如,如果N = 4,则计数为15、7、3、1。
MOV i, #1
RSB i, i, i, LSL N ; i=(1 << N)-1
loop
; loop body
MOVS i, i, LSR#1
BNE loop循环结构总结:
- ARM需要两条指令来实现计数循环:一个减法指令用于设置标志位,一个条件分支指令。
- 对循环进行展开可以提高循环性能,但不要过度展开,因为这会影响缓存的性能。对于迭代次数较小的循环展开可能效率低下,可以通过测试迭代次数来决定是否调用展开后的循环。
- 嵌套循环只需要一个循环计数器寄存器,这可以提高效率,为其他用途释放出寄存器。
- ARM可以高效地实现负索引和对数索引的循环。
6.7 Bit Manipulation
压缩文件格式以位为粒度打包项目,以最大化数据密度。这些项目可以是固定宽度的,例如长度字段或版本字段,也可以是可变宽度的,例如Huffman编码的符号。在压缩中,Huffman编码用于为每个符号分配一串位的编码。对于常见的符号,编码较短,对于罕见的符号,编码较长。
在本节中,我们将介绍处理位流的有效方法。首先,我们将讨论固定宽度编码,然后是可变宽度编码。有关常见的位操作例程(如字节序和位反转),请参阅第7.6节。
6.7.1 Fixed-Width Bit-Field Packing and Unpacking
//固定宽度的位字段打包和解包
在ARM寄存器中提取无符号位字段,如果预先设置掩码,可以在一个周期内完成;否则需要两个周期。对于有符号位字段,除非位字段位于字(最高有效位是寄存器的最高有效位),否则始终需要两个周期来解包。在ARM中,我们使用逻辑操作和移位器来进行编码的打包和解包,如下面的示例所示。
示例6.22
汇编代码展示了如何从寄存器r0中解包位4到15,并将结果放入r1中。
; unsigned unpack with mask set up in advance
; mask=0x00000FFF
AND r1, mask, r0, LSR#4
; unsigned unpack with no mask
MOV r1, r0, LSL#16 ; discard bits 16-31
MOV r1, r1, LSR#20 ; discard bits 0-3 and zero extend
; signed unpack
MOV r1, r0, LSL#16 ; discard bits 16-31
MOV r1, r1, ASR#20 ; discard bits 0-3 and sign extend示例: 6.23 如果r1已经限制在正确的范围,并且r0的相应位字段为空,则将值r1打包到位压缩寄存器r0中只需要一个周期。在这个示例中,r1是一个12位的数字,要插入到r0的第4位。
; pack r1 into r0
ORR r0, r0, r1, LSL #4否则,您需要设置一个掩码寄存器:
; pack r1 into r0
; mask=0x00000FFF set up in advance
AND r1, r1, mask ; restrict the r1 range
BIC r0, r0, mask, LSL#4 ; clear the destination bits
ORR r0, r0, r1, LSL#4 ; pack in the new data6.7.2 Variable-Width Bitstream Packing
我们的任务是将一系列可变长度的编码打包成一个位流。通常,我们会对数据流进行压缩,而可变长度的编码表示哈夫曼或算术编码符号。然而,为了有效地进行打包,我们不需要做出任何关于编码表示的假设。

我们需要注意位打包的字节序。许多压缩文件格式使用大端字节序的位打包顺序,其中第一个编码位于第一个字节的最高有效位。因此,我们将在示例中使用大端字节序的位打包顺序。这有时被称为网络字节序。图6.5展示了如何使用大端打包顺序将可变长度的位码形成字节流。"High"和"low"分别表示字节的最高有效位和最低有效位。
为了在ARM上高效实现打包,我们使用一个32位寄存器作为缓冲区,按照大端序存储四个字节。换句话说,我们将字节流的第0个字节放置在寄存器的最高8位。然后,我们可以逐个将编码插入寄存器中,从最高有效位开始,逐位往下,直到最低有效位。一旦寄存器被填满,我们就可以将32位存储到内存中。对于大端存储系统,我们可以直接存储这个字;对于小端存储系统,我们需要在存储之前反转字节顺序。
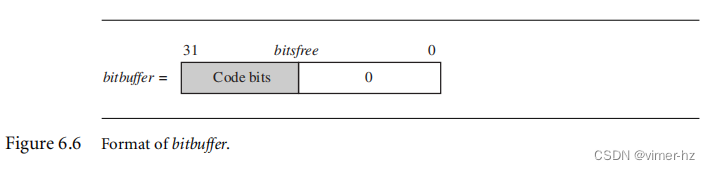
我们将插入代码的32位寄存器称为bitbuffer。我们需要一个名为bitsfree的第二个寄存器来记录bitbuffer中尚未使用的位数。换句话说,bitbuffer包含32 - bitsfree个代码位和bitsfree个零位,如图6.6所示。要将k位的代码插入bitbuffer,我们从bitsfree中减去k,然后使用bitsfree的左移插入代码。
我们还需要注意对齐。字节流不一定是字对齐的,因此我们不能使用字访问来写入它。为了允许字访问,我们将首先备份到最后一个字对齐的地址。然后,我们用备份的数据填充32位寄存器bitbuffer。从那时起,我们可以使用字(32位)的读写操作。
例子6.24
该示例提供了三个函数:bitstream_write_start、bitstream_write_code和bitstream_write_flush。这些函数不符合ATPCS规范,因为它们假设像bitbuffer这样的寄存器在调用之间被保留。在实践中,您可以内联此代码以提高效率,所以这不是一个问题。
bitstream_write_start函数对齐位流指针bitstream并初始化32位缓冲区bitbuffer。每次调用bitstream_write_code函数,都会将长度为codebits的值code插入其中。最后,bitstream_write_flush函数将任何剩余的字节写入位流,以终止流。
bitstream RN 0 ; current byte address in the output bitstream
code RN 4 ; current code
codebits RN 5 ; length in bits of current code
bitbuffer RN 6 ; 32-bit output big-endian bitbuffer
bitsfree RN 7 ; number of bits free in the bitbuffer
tmp
RN 8 ; scratch register
mask RN 12 ; endian reversal mask 0xFFFF00FF
bitstream_write_start
MOV bitbuffer, #0
MOV bitsfree, #32
align_loop
TST bitstream, #3
LDRNEB code, [bitstream, #-1]!
SUBNE bitsfree, bitsfree, #8
ORRNE bitbuffer, code, bitbuffer, ROR #8
BNE align_loop
MOV bitbuffer, bitbuffer, ROR #8
MOV pc, lr
bitstream_write_code
SUBS bitsfree, bitsfree, codebits
BLE full_buffer
ORR bitbuffer, bitbuffer, code, LSL bitsfree
MOV pc, lr
full_buffer
RSB bitsfree, bitsfree, #0
ORR bitbuffer, bitbuffer, code, LSR bitsfree
IF {ENDIAN}="little"
; byte reverse the bit buffer prior to storing
EOR tmp, bitbuffer, bitbuffer, ROR #16
AND tmp, mask, tmp, LSR #8
EOR bitbuffer, tmp, bitbuffer, ROR #8
ENDIF
STR bitbuffer, [bitstream], #4
RSB bitsfree, bitsfree, #32
MOV bitbuffer, code, LSL bitsfree
MOV pc, lr
bitstream_write_flush
RSBS bitsfree, bitsfree, #32
flush_loop
MOVGT bitbuffer, bitbuffer, ROR #24
STRGTB bitbuffer, [bitstream], #1
SUBGTS bitsfree, bitsfree, #8
BGT flush_loop
MOV pc, lr6.7.3 Variable-Width Bitstream Unpacking
解压可变宽度代码的位流比打包要困难得多。问题在于,我们通常不知道正在解压的代码的宽度!对于Huffman编码的位流,您必须通过查看下一个比特序列并确定它是哪个代码来推导出每个代码的长度。
在这里,我们将使用查找表来加速解压过程。想法是获取位流的下一个N位,并在两个大小为2N条目的查找表look_codebits[]和look_code[]中进行查找。如果下一个N位足以确定代码,则这些表分别告诉我们代码长度和代码值。如果下一个N位不足以确定代码,则look_codebits表将返回一个逃逸值0xFF。逃逸值只是一个标志,表示这种情况是异常情况。
在Huffman代码序列中,常见代码长度较短,而稀有代码长度较长。因此,我们希望能够快速解码大多数常见代码,使用查找表。在下面的例子中,我们假设N = 8,并使用256个条目的查找表。
例子6.25
该示例提供了三个函数,用于解压存储在字节流中的大端位流。与例6.24类似,这些函数不符合ATPCS规范,并且通常会被内联。函数bitstream_read_start初始化该过程,在位流的字节地址bitstream上开始解码。每次调用bitstream_read_code函数都会将下一个代码返回给寄存器code。该函数仅处理可以从查找表中读取的短代码。长代码会陷入到标签long_code,但是此函数的实现取决于您正在解码的代码。

代码使用一个寄存器bitbuffer,其中包含从最高有效位开始的N + bitsleft个代码位(参见图6.7)。
bitstream RN 0 ; current byte address in the input bitstream
look_code RN 2 ; lookup table to convert next N bits to a code
look_codebits RN 3 ; lookup table to convert next N bits to a code length
code RN 4 ; code read
codebits RN 5 ; length of code read
bitbuffer RN 6 ; 32-bit input buffer (big endian)
bitsleft RN 7 ; number of valid bits in the buffer - N
tmp
RN 8 ; scratch
tmp2 RN 9 ; scratch
mask RN 12 ; N-bit extraction mask (1 << N)-1
N
EQU 8 ; use a lookup table on 8 bits (N must be <= 9)
bitstream_read_start
MOV bitsleft, #32
read_fill_loop
LDRB tmp, [bitstream], #1
ORR bitbuffer, tmp, bitbuffer, LSL#8
SUBS bitsleft, bitsleft, #8
BGT read_fill_loop
MOV bitsleft, #(32-N)
MOV mask, #(1 << N)-1
MOV pc, lr
bitstream_read_code
LDRB codebits, [look_codebits, bitbuffer, LSR# (32-N)]
AND code, mask, bitbuffer, LSR#(32-N)
LDR code, [look_code, code, LSL#2]
SUBS bitsleft, bitsleft, codebits
BMI empty_buffer_or_long_code
MOV bitbuffer, bitbuffer, LSL codebits
MOV pc, lr
empty_buffer_or_long_code
TEQ codebits, #0xFF
BEQ long_code
; empty buffer - fill up with 3 bytes
; as N <= 9, we can fill 3 bytes without overflow
LDRB tmp, [bitstream], #1
LDRB tmp2, [bitstream], #1
MOV bitbuffer, bitbuffer, LSL codebits
LDRB codebits, [bitstream], #1
ORR tmp, tmp2, tmp, LSL#8
RSB bitsleft, bitsleft, #(8-N)
ORR tmp, codebits, tmp, LSL#8
ORR bitbuffer, bitbuffer, tmp, LSL bitsleft
RSB bitsleft, bitsleft, #(32-N)
MOV pc, lr
long_code
; handle the long code case depending on the application
; here we just return a code of -1
MOV code, #-1
MOV pc, lr计数器bitsleft实际上计算的是缓冲区bitbuffer中剩余的位数减去下一个查找所需的N位。因此,只要bitsleft ≥ 0,我们就可以执行下一个表查找。一旦bitsleft < 0,就有两种可能性。一种可能性是我们找到了一个有效的代码,但没有足够的位数来查找下一个代码。另一种可能性是codebits包含了逃逸值0xFF,表示代码长度超过了N位。我们可以使用调用empty_buffer_or_long_code一次捕获这两种情况。如果缓冲区为空,我们将其填充为24位。如果我们检测到了一个长代码,我们将跳转到long_code陷阱。
在ARM9TDMI上,该示例在最佳情况下每个代码解压缩需要七个周期。如果提前知道打包的位字段的大小,可以获得更快的结果。
总结:位操作
■ 使用逻辑操作和移位寄存器,ARM可以高效地对位进行打包和解压缩。
■ 要高效访问位流,请使用一个32位寄存器作为位缓冲区。使用第二个寄存器跟踪位缓冲区中有效位的数量。
■ 要高效解码位流,请使用查找表扫描位流的下一个N位。查找表可以直接返回最多N位长的代码,或者对于更长的代码返回一个逃逸字符。
6.8 Efficient Switches
一个开关或多路分支可以在多个不同的动作之间进行选择。在本节中,我们假设动作取决于变量x。对于不同的x值,我们需要执行不同的动作。本节将讨论如何使用汇编语言高效地实现针对不同类型的x的开关。
6.8.1 Switches on the Range 0 ≤ x<N
示例C函数`ref_switch`根据x的值执行不同的操作。我们只对范围在0 ≤ x < 8的x值感兴趣。
int ref_switch(int x)
{
switch (x)
{
case 0: return method_0();
case 1: return method_1();
case 2: return method_2();
case 3: return method_3();
case 4: return method_4();
case 5: return method_5();
case 6: return method_6();
case 7: return method_7();
default: return method_d();
}
}有两种方法可以在ARM汇编中高效地实现这个结构。第一种方法使用一个函数地址表。我们通过从由x索引的表中加载pc来实现。
示例6.26
`switch_absolute`代码使用一个内联的函数指针表执行开关操作:
x RN 0
; int switch_absolute(int x)
switch_absolute
CMP x, #8
LDRLT pc, [pc, x, LSL#2]
B method_d
DCD method_0
DCD method_1
DCD method_2
DCD method_3
DCD method_4
DCD method_5
DCD method_6
DCD method_7这段代码有效的原因是pc寄存器是流水线化的。当ARM执行LDR指令时,pc指向method_0单词。
上述方法非常快速,但有一个缺点:代码不具备位置无关性,因为它在内存中存储了方法函数的绝对地址。位置无关代码通常用于在运行时将模块安装到系统中。下面的示例展示了如何解决这个问题。
示例 6.27 与switch_absolute相比,switch_relative代码稍慢一些,但它是位置无关的:
; int switch_relative(int x)
switch_relative
CMP x, #8
ADDLT pc, pc, x, LSL#2
B method_d
B method_0
B method_1
B method_2
B method_3
B method_4
B method_5
B method_6
B method_7还有一个最后的优化可以实施。如果方法函数很短,你可以将指令内联到分支指令的位置。
例如 6.28 假设每个非默认方法都有一个包含四条指令的实现。那么你可以使用以下形式的代码:
CMP x, #8
ADDLT pc, pc, x, LSL#4 ; each method is 16 bytes long
B method_d
method_0
; the four instructions for method_0 go here
method_1
; the four instructions for method_1 go here
; ... continue in this way ...6.8.2 Switches on a General Value x
现在假设x不在方便的范围0≤x<N内,其中N足够小以应用6.8.1节中的方法。在不需要逐个测试x与每个可能的值相比较的情况下,我们如何高效地执行switch操作呢?
在这种情况下,一种非常有用的技术是使用散列函数(哈希函数)。散列函数是任何将我们感兴趣的值映射到形式为0≤y<N的连续范围的函数y = f (x)。我们可以使用y = f (x)来代替对x进行switch操作。如果出现碰撞,即两个x值映射到相同的y值,则可以处理碰撞。在这种情况下,我们需要进一步的代码来测试所有可能导致该y值的x值。对于我们的目的来说,一个好的散列函数应该容易计算并且不会产生太多的碰撞。
为了执行switch操作,我们先应用散列函数,然后在散列值y上使用6.8.1节中优化过的switch代码。当两个x值可以映射到相同的散列值时,我们需要进行显式测试,但对于一个好的散列函数来说,这种情况应该很少发生。
6.29示例中,假设我们想要在x = 2^k的情况下调用method_k,其中x的取值范围是1, 2, 4, 8, 16, 32, 64, 128。对于x的所有其他值,我们需要调用默认方法method_d。我们需要找到一个由乘以2的幂减1形成的散列函数(这在ARM上是一种高效的操作)。通过尝试不同的乘数,我们发现15 × 31 × y在第9至第11位(最右边第0位)上的值对应于八个情况下的不同值。这意味着我们可以将这个乘积的第9至第11位作为我们的散列函数。
y=1, 15x31x1=000111010001 , k=0
y=2, 15x31x2=001110100010 , k=1
y=3, 15x31x3=010101110011 , k=2
y=4, 15x31x4=011101000100 , k=3
y=5, 15x31x5=100100010101 , k=4
y=6, 15x31x6=101011100110 , k=5
y=7, 15x31x7=110010110111 , k=6
y=8, 15x31x8=111010001000 , k=7
以下是使用该散列函数执行switch操作的汇编代码switch_hash。请注意,其他不是2的幂的值会与我们要检测的值具有相同的散列值。switch操作将情况缩小到单个2的幂,我们可以显式测试。如果x不是2的幂,则会执行默认情况,调用method_d。
x RN 0
hash RN 1
; int switch_hash(int x)
switch_hash
RSB hash, x, x, LSL#4 ; hash=x*15
RSB hash, hash, hash, LSL#5 ; hash=x*15*31
AND hash, hash, #7 << 9 ; mask out the hash value
ADD pc, pc, hash, LSR#6
NOP
TEQ x, #0x01
BEQ method_0
TEQ x, #0x02
BEQ method_1
TEQ x, #0x40
BEQ method_6
TEQ x, #0x04
BEQ method_2
TEQ x, #0x80
BEQ method_7
TEQ x, #0x20
BEQ method_5
TEQ x, #0x10
BEQ method_4
TEQ x, #0x08
BEQ method_3
B method_d高效的switch语句总结如下:
■ 确保switch值在某个小范围内,即0 ≤ x < N,其中N为一个较小的数值。为了实现这一点,你可能需要使用散列函数进行转换。
■ 使用switch值作为索引来查找函数指针表,或者根据switch值在代码中的位置定期分支到短代码段。第二种技术是位置无关的,而第一种技术则不是。
请注意,上述两种技术都可以实现高效的switch语句。使用函数指针表提供了更加优雅和灵活的解决方案,而将代码分成块的方法则更适用于特定场景。选择哪种技术取决于应用的具体需求和限制条件。
6.9 Handling Unaligned Data
在ARM架构中,如果加载或存储使用的地址不是数据传输宽度的倍数,则称为非对齐访问。为了确保代码在不同的ARM架构和实现中具有可移植性,必须避免进行非对齐访问。第5.9节介绍了C语言中处理非对齐访问的方法。在本节中,我们将介绍如何在汇编代码中处理非对齐访问。
最简单的方法是使用字节加载和存储来逐个字节地访问数据。这是推荐的方法,适用于对速度要求不高的访问。以下示例展示了如何以这种方式访问字值。
示例6.30:
该示例展示了如何使用非对齐地址p读取或写入一个32位字。我们使用三个临时寄存器t0、t1和t2来避免冲突。在ARM9TDMI上,所有非对齐字操作需要七个周期。请注意,我们需要针对大端或小端格式存储的32位字分别使用不同的函数。
p RN 0
x RN 1
t0 RN 2
t1 RN 3
t2 RN 12
; int load_32_little(char *p)
load_32_little
LDRB x, [p]
LDRB t0, [p, #1]
LDRB t1, [p, #2]
LDRB t2, [p, #3]
ORR x, x, t0, LSL#8
ORR x, x, t1, LSL#16
ORR r0, x, t2, LSL#24
MOV pc, lr
; int load_32_big(char *p)
load_32_big
LDRB x, [p]
LDRB t0, [p, #1]
LDRB t1, [p, #2]
LDRB t2, [p, #3]
ORR x, t0, x, LSL#8
ORR x, t1, x, LSL#8
ORR r0, t2, x, LSL#8
MOV pc, lr
; void store_32_little(char *p, int x)
store_32_little
STRB x, [p]
MOV t0, x, LSR#8
STRB t0, [p, #1]
MOV t0, x, LSR#16
STRB t0, [p, #2]
MOV t0, x, LSR#24
STRB t0, [p, #3]
MOV pc, lr
; void store_32_big(char *p, int x)
store_32_big
MOV t0, x, LSR#24
STRB t0, [p]
MOV t0, x, LSR#16
STRB t0, [p, #1]
MOV t0, x, LSR#8
STRB t0, [p, #2]
STRB x, [p, #3]
MOV pc, lr如果您需要比每次访问七个周期更好的性能,那么您可以编写几个不同的变体函数,每个变体函数处理不同的地址对齐方式。这将将非对齐访问的开销降低为三个周期:字加载和两个算术指令来将值组合在一起。
示例6.31:
该示例展示了如何从可能是非对齐地址data开始生成N个字的校验和。该代码适用于小端内存系统。请注意,我们可以使用汇编器的宏指令来生成四个函数checksum_0、checksum_1、checksum_2和checksum_3。函数checksum_a处理data是形式为4 + a的地址的情况。
使用宏指令可以节省编程工作量。我们只需要编写一个宏指令,并将其实例化四次以实现我们的四个校验和函数。
sum RN 0 ; current checksum
N RN 1 ; number of words left to sum
data RN 2 ; word aligned input data pointer
w RN 3 ; data word
; int checksum_32_little(char *data, unsigned int N)
checksum_32_little
BIC data, r0, #3 ; aligned data pointer
AND w, r0, #3 ; byte alignment offset
MOV sum, #0
; initial checksum
LDR pc, [pc, w, LSL#2] ; switch on alignment
NOP
; padding
DCD checksum_0
DCD checksum_1
DCD checksum_2
DCD checksum_3
MACRO
CHECKSUM $alignment
checksum_$alignment
LDR w, [data], #4 ; preload first value
10 ; loop
IF $alignment<>0
ADD sum, sum, w, LSR#8*$alignment
LDR w, [data], #4
SUBS N, N, #1
ADD sum, sum, w, LSL#32-8*$alignment
ELSE
ADD sum, sum, w
LDR w, [data], #4
SUBS N, N, #1
ENDIF
BGT %BT10
MOV pc, lr
MEND
; generate four checksum routines
; one for each possible byte alignment
CHECKSUM 0
CHECKSUM 1
CHECKSUM 2
CHECKSUM 3您现在可以像第6.6.2节中所示,展开和优化这些函数以实现最快的速度。由于代码大小的增加,只有在对时间要求非常高的函数中才使用前面的技术。
处理非对齐数据的总结:
- 如果性能不是问题,可以使用多个字节加载和存储来访问非对齐数据。这种方法可以访问给定字节序的数据,而不考虑指针对齐和内存系统配置的字节序。
- 如果性能是一个问题,那么可以使用多个函数,每个函数针对可能的数组对齐方式进行优化。您可以使用汇编器的宏指令来自动生成这些函数。
6.10 Summary
为了实现最佳性能,您需要编写优化的汇编程序。只有对性能影响较大的关键函数进行优化才是值得的。您可以使用性能分析或周期计数工具(例如ARM的ARMulator模拟器)来找到这些关键函数。
本章介绍了针对ARM汇编优化的示例和实用技巧,以下是关键思想:
- 安排代码,以避免处理器的互锁和停顿。使用附录D查看指令结果可用的时间。特别注意加载和乘法指令,因为它们通常需要很长时间才能产生结果。
- 尽量使用14个可用的通用寄存器保存数据。有时可以将多个数据项打包到一个寄存器中。避免在内层循环中进行数据堆栈操作。
- 对于小的条件语句,使用条件数据处理操作而不是条件分支。
- 使用倒计数的展开循环以实现最大的循环性能。
- 对于位压缩数据的打包和解包,使用32位寄存器缓冲区以提高效率并减少内存数据带宽。
- 使用分支表和哈希函数来实现高效的switch语句。
- 要高效处理非对齐数据,请使用多个函数。为输入和输出数组的特定对齐方式优化每个函数。在运行时根据情况选择函数。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









