







- 背景
- 问题说明
- 分析
- LeNet5参数
- MNIST程序参数
- 遗留问题
- 小结
背景
之前博文中关于CNN的模型训练功能上是能实现,但是研究CNN模型内部结构的时候,对各个权重系数
w
,偏差
问题说明
# Input Layer
x = tf.placeholder('float',[None,784])
y_ = tf.placeholder('float',[None,10])
# First Layer
W_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32])
x_image = tf.reshape(x,[-1,28,28,1])
h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# Second Layer
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# Connect Layer
W_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1) + b_fc1)
# Dropout Layer
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob)
# Output Layer
W_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])这段程序,是mnist_test2.py中关于Tensorflow Graph建立的代码,里面为所有使用到的Variables都分配了指定的大小。例如x通过placeholder预留了None*784大小的shape(None会随着batch获取的数据个数而改变),第一层的卷积系数W_conv1是5*5*1*32大小的shape,后面不再赘述。
有些shape比如输入的xNone*784的784是28*28个8位灰度值的shape,y_是None*10个数字分类的shape,输出的b_fc2是对应10个输出类别的偏差。但是对于其他参数的话,我就不禁要问:①这么做是为什么呢?②如果不这么设置参数行不行呢?③如果我换一套数据集,参数还是这么设置么?
先回答第二个问题吧,不行。如果随意更换参数,换的对可能能跑通,但是影响性能,但是更多的时候会是下面的结果:


分析
先看看LeNet5
在回答第一个问题之前,建议大家阅读一下2012年NIPS上做ImageNet的文献1和解释LaNet5的CNN模型的PPT,如果时间不够用的话,也可以直接看一下qiaofangjie的中文参数解析。里面可以先对LeNet5的参数有个大概了解。下面我对照着经典的图,大体归纳一下:
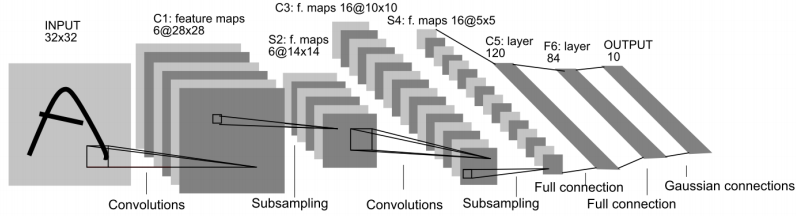
CNN里的层,除了输入/输出层之外,把隐含层又分成了卷积层、池化层、以及全连接层。三者的作用及介绍也可以参考小新的猫的理解。卷积层会对原始输入数据做加权求和的处理,学过通信的同学一定对一维线性卷积里面“错位相乘相加”很熟悉(原谅我强行奶一口原来的专业),这里就是线性卷积在二维里面的推广。池化层是为了减小模型复杂度,通过降采样(又是通信里有概念我会乱讲?)缩小特征图的尺寸。全连接层是将最终高度抽象化的特征图与输出直接进行的全连接,这与入门级MNIST库的模型训练做的事儿是一样的,一个简单的全映射。
具体的看,第一个卷积层C1对32*32的输入数据(假设成一个矩阵,其中每个元素代表当前位置像素点灰度值的强弱)进行二维加权相加
yl+1m,n=∑i,jwli,jxli,j+bl+1
其中上标
l
表示层数,下标
(此处补零采用了VALID模式,这个问题后面会接着说)。我们假设卷积器的权重矩阵是一个5*5的,相当于对5*5的输入数据,与5*5的卷积器卷积后,得到了1*1的数值,如果是5*6的原始数据,卷积后会得到1*2的输出,所以推广到32*32的数据,输出会得到28*28的尺寸。再推广一下就会得到:
输出宽度=输入宽度-(卷积器宽度-1)
输出高度=输入高度-(卷积器高度-1)
至于为什么一幅输入会得到6组对应的卷积输出呢?这个问题对我来说还说不清楚,只能暂时理解为一幅输入的6个不同的特征(Hinton老师讲家谱树的时候就用了6个对应特征表示是英国人还是意大利,是爷爷辈儿还是孙子辈儿等),比如输入是否有圆圈形状,边缘是否明确,是否有纹理特征等。这个问题后面的话有可能会可视化验证一下,目前只能这么理解了。
接下来第二个池化层S2,对6*28*28的特征图进行下采样得到了6*14*14的池化层特征图,主要是因为其中采用每2*2的块儿进行一次容和统计,并且块与块儿直接不交叠,掐指一算还真是(28/2*28/2),池化操作并没有增加特征维度,只是单纯的下采样。
在后面的那层卷积层C3的shape也可以理解了,对14*14的特征输入,输出10*10的特征图,并且此时把6个特征抽象到了更多的16个特征。下面的S4就不说了。
看一下C5,这里又来了问题了,暂时还不能理解,为什么会出现120这个数字,暂且搁置。一般CNN中的全连接层,我见到的都是1-2层,并且两个层的shape是一致的。比如这里都是120,文献1中全是2048。
MNIST库程序
ok,以上就是对LeNet5的参数理解,下面我们来看一下MNIST程序中的各个参数。首先,建议使用如下代码,在跑通的程序中,方便查看每个变量的shape,具体代码如下:
def showSize():
print "x size:",batch[0].shape
#print "x_value",batch[0]
print "y_ size:",batch[1].shape
#print "y_example",batch[1][0]
#print "y_example",batch[1][9]
#print "y_example",batch[1][10]
print "w_conv1 size:",W_conv1.eval().shape
print "b_conv1 size:",b_conv1.eval().shape
print "x_image size:",x_image.eval(feed_dict={x:batch[0]}).shape
print "h_conv1 size:",h_conv1.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "h_pool1 size:",h_pool1.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "w_conv2 size:",W_conv2.eval().shape
print "b_conv2 size:",b_conv2.eval().shape
print "h_conv2 size:",h_conv2.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "h_pool2 size:",h_pool2.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "w_fc1 size:",W_fc1.eval().shape
print "b_fc1 size:",b_fc1.eval().shape
print "h_pool2_flat size:",h_pool2_flat.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "h_fc1 size:",h_fc1.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "h_fc1_drop size:",h_fc1_drop.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape
print "w_fc2 size:",W_fc2.eval().shape
print "b_fc2 size:",b_fc2.eval().shape
print "y_conv size:",y_conv.eval(feed_dict={x:batch[0],y_:batch[1],keep_prob:1.0}).shape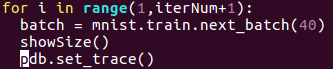
像这样插在每次循环中,然后,我们可以试运行一下看看结果
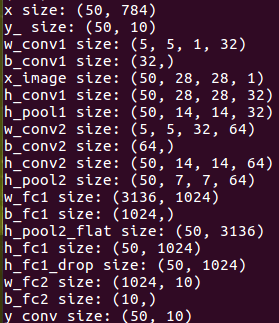
这个小函数写的时候要注意,对于Tensor类型的Variable,并没有shape这个属性,必须在每个Tensor.eval()才可以使用.shape属性,而Tensor.eval()的话,就需要feed_dict一个依赖值才可以获得tensor实例,否则Tensor对象只是一个代号而已。
在输入50个batch的时候可以看到输入,输出shape不说了,w_conv1涉及到tf.conv2d的用法,具体可以参考官方文档,这里的前两个5对应的卷及系数shape,第三个参数1表示输入通道,对应输入数据只有灰度值一个特征,或者说是对应LeNet分析中一幅图,最后一个32是输出通道数,表示输出32组特征。
稍等,对于MNIST的28*28的输入数据,经过第一层卷积C1,为何输出的h_conv1还是28*28的维度,而不是刚刚推论中的24*24呢?这我也研究了好久,原因在于tf.conv2d函数的参数指定了padding类型为“SAME”,这个参数的作用在官方文档中直接决定了输出的shape,截选如下:

这只是数值上说明了,具体的原因小新的猫的理解说的非常明白,他还对比了Matlab和Tensorflow对于Padding参数的不同选项,可以视具体的应用环境在做测试。
最后看一下全连接层的参数w_fc1,对接上面的卷基层输出,第一个参数是池化后7*7的尺寸*64组特征,第二个参数与LeNet的120一致,是输出给全连接的参数。
遗留问题
现在看来,与卷积,池化相关的shape变化应该是可以理解了,不过还有两种参数不理解:
①是卷积层的特征数,为什么LeNet里面两层卷积层的特征会是6和16,而MNIST是32和64,按道理MNIST是28*28的数据输入,还小于LeNet的32*32呢,却有着更高的特征维度。
②全连接层的参数,LeNet里面用的2个120参数的,而MNIST里面全连接却有1024个参数。
这些问题也问过Tensorflow群里群友,问到的都说是经验问题,需要自己把握,真的是这样哇?这两个参数的选择难道只是个工程经验问题嘛?我目前的理解的话只能一边继续看资料,一边工程做实验测试一下模型收敛速度啦。结合TensorBoard可视化应该后者会给我个答案。
小结
这篇文章,对CNN的网络中参数的shape做了分析,希望能对大家理解起来有所帮助,至于文中说到的两个参数遗留问题,也希望有大神能不吝指教呀。
PS:我必须要吐槽!CSDN为什么只能保存一个草稿,我写第一篇博文的时候突然觉得应该把这个问题剥离出来先讲一讲,结果之前那篇的草稿就没有了!那也是1个半小时的思路整理啊!不过也怪自己没有备份。TAT















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









