







RNN&LSTM
当前输出的产生与之前的信息(输出、状态)相关
RNN:过去发生的事件可以预测现在
LSTM(进阶RNN):过去发生的事情太多了,全部记住的话,处理起来过于复杂,因此选择遗忘不重要事件,记住重要的(解决长期依赖问题)
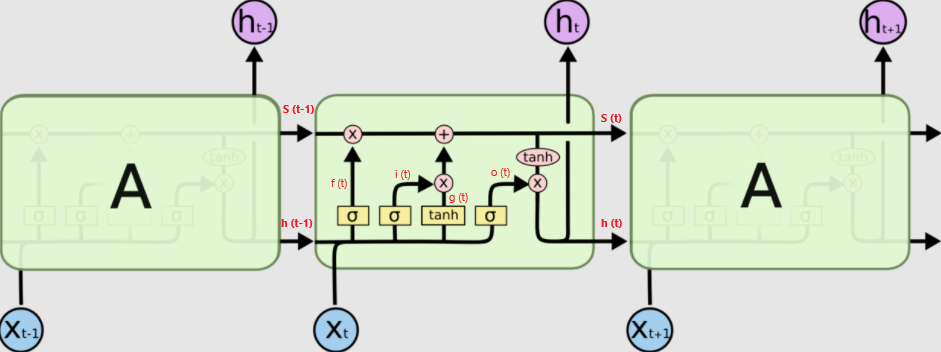
LSTM 核心思想
Sigmoid 层输出 0 到 1 之间的数值,可以用来描述每个部分有多少需要记住。0 指代“全忘记”,1 指“记住所有”
原本RNN只有 tanh层 来处理当前输出(过去和现在输入),LSTM将 Sigmoid 层运用到 tanh层,增添了状态信息,并进一步将其设计为门结构,来决定当前输出。
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。
门是一种让信息选择式通过的方法。他们包含一个sigmoid 神经网络层和一个pointwise 乘法操作。
LSTM 拥有三个门,来保护和控制细胞状态。f,i,o 分别表示遗忘门、输入门、输出门
分别表示遗忘门、输入门、输出门

前向传播
当前状态
LSTM 设计了状态信息Ct来选择是否遗忘,因而三个门中,有两个是用来产生状态信息的,如下:
- (遗忘门 f )sigmoid (Ht-1,Xt)
(pointwise)C t-1 ;——乘:有 0为 0 ,并且以后所有乘0都为0 - (输入门 i )sigmoid (Ht-1,Xt)
(pointwise)tanh(Ht-1,Xt) ;
- Ct = 1输出
+2输出 ;*——与:有0为0,同1为 1 // 加号:同0为0,异为1,同1为2

当前输出
- (输出门 o )sigmoid (Ht-1,Xt)
(pointwise)tanh(Ct)
其中 sigmoid (x,y) 和 tanh(x,y) 等涉及的两个向量x,y处理为 W(x,y)+b,即 sigmoid (W(x,y)+b)、tanh(W(x,y)+b)。再将两个参数向量合并 Xc(t) = [X(t),H(t-1)],则 sigmoid (W(Xc)+b)、tanh(W(Xc)+b)。
则当前cell相关方程如下(s 为状态 C):

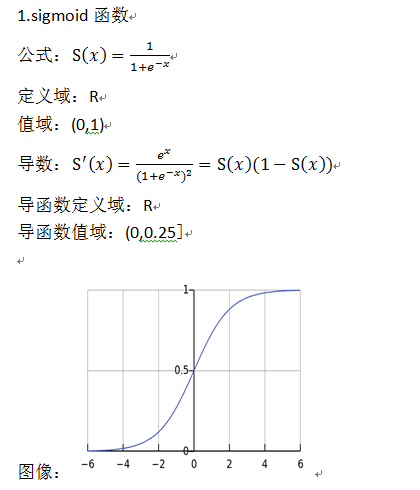
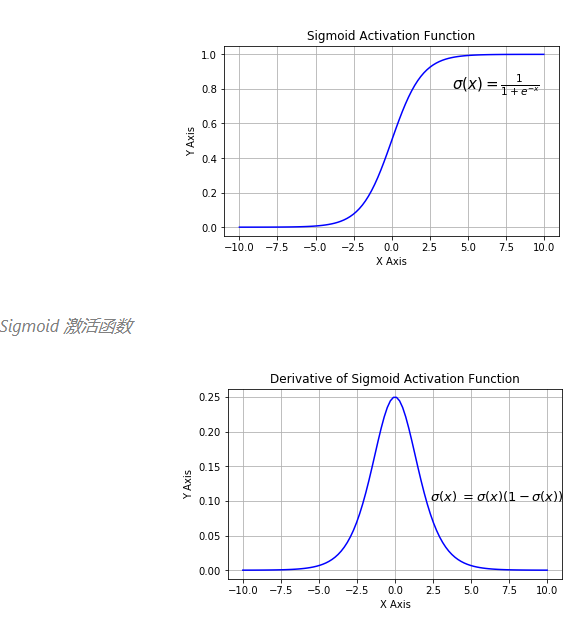
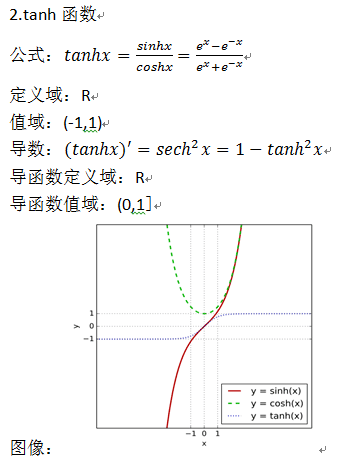
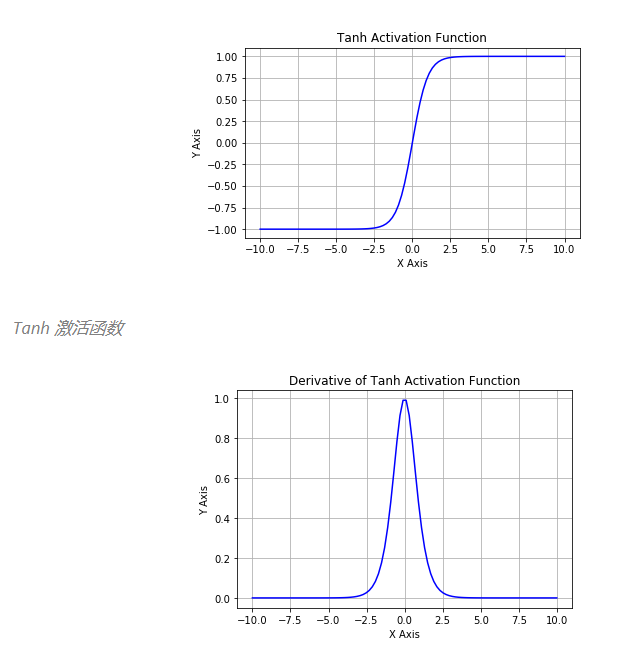
sigmoid和tanh的区别
sigmoid 在特征相差比较复杂或是相差不大时效果比较好
tanh 在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果,0均值
sigmoid在输入处于[-1,1]之间时,函数值变化敏感,一旦接近或者超出区间就失去敏感性,处于饱和状态,影响神经网络预测的精度值。tanh的输出和输入能够保持非线性单调上升和下降关系,符合BP网络的梯度求解,容错性好,有界,渐进于0、1,符合人脑神经饱和的规律,但比 sigmoid 函数延迟了饱和期。
反向传播
已知部分参数基于损失函数 t+1 时刻的偏导数,计算所有参数基于损失函数 t 时刻的偏导数
反向传播计算误差的传播沿两个方向,分别为从输出层传递至输入层,以及沿时间 t 的反向传播
先计算h输出误差,用h表述s状态的误差,再用h和s计算其他参数误差
- diff_h
h(t),y(t) 分别为输出序列与样本标签
diff_h = 2·sum(h(t)-y(t))
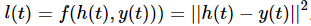

def bottom_diff(self, pred, label):
diff = np.zeros_like(pred)
diff[0] = 2 * (pred[0] - label)
return diff
while idx >= 0:
diff_h = bottom_diff(self.lstm_node_list[idx].state.h, y_list[idx])
diff_h += self.lstm_node_list[idx + 1].state.bottom_diff_h
- diff_s

ds = self.state.o * top_diff_h + top_diff_s
- 其他 diff_o i g f

do = self.state.s * top_diff_h
di = self.state.g * ds
dg = self.state.i * ds
df = self.s_prev * ds
- wi_diff

wi_diff += np.outer( (1. - i) * i *di, xc)
1. - i相比较1 - i,若 i 为整数,结果为 float
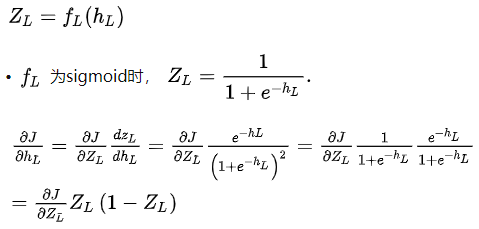
以下代码主要来自参考文章7
LSTM 代码实现
import random
import numpy as np
import math
def sigmoid(x):
return 1. / (1 + np.exp(-x))
# createst uniform random array w/ values in [a,b) and shape args
def rand_arr(a, b, *args):
np.random.seed(0)
return np.random.rand(*args) * (b - a) + a
# 参数
class LstmParam:
def __init__(self, mem_cell_ct, x_dim):
self.mem_cell_ct = mem_cell_ct
self.x_dim = x_dim
concat_len = x_dim + mem_cell_ct
# 权重矩阵 weight matrices
self.wg = rand_arr(-0.1, 0.1, mem_cell_ct, concat_len)
self.wi = rand_arr(-0.1, 0.1, mem_cell_ct, concat_len)
self.wf = rand_arr(-0.1, 0.1, mem_cell_ct, concat_len)
self.wo = rand_arr(-0.1, 0.1, mem_cell_ct, concat_len)
# 偏置 bias terms
self.bg = rand_arr(-0.1, 0.1, mem_cell_ct)
self.bi = rand_arr(-0.1, 0.1, mem_cell_ct)
self.bf = rand_arr(-0.1, 0.1, mem_cell_ct)
self.bo = rand_arr(-0.1, 0.1, mem_cell_ct)
# 梯度 diffs (derivative of loss function w.r.t. all parameters)
self.wg_diff = np.zeros((mem_cell_ct, concat_len))
self.wi_diff = np.zeros((mem_cell_ct, concat_len))
self.wf_diff = np.zeros((mem_cell_ct, concat_len))
self.wo_diff = np.zeros((mem_cell_ct, concat_len))
self.bg_diff = np.zeros(mem_cell_ct)
self.bi_diff = np.zeros(mem_cell_ct)
self.bf_diff = np.zeros(mem_cell_ct)
self.bo_diff = np.zeros(mem_cell_ct)
def apply_diff(self, lr = 1):
self.wg -= lr * self.wg_diff
self.wi -= lr * self.wi_diff
self.wf -= lr * self.wf_diff
self.wo -= lr * self.wo_diff
self.bg -= lr * self.bg_diff
self.bi -= lr * self.bi_diff
self.bf -= lr * self.bf_diff
self.bo -= lr * self.bo_diff
# reset diffs to zero
self.wg_diff = np.zeros_like(self.wg)
self.wi_diff = np.zeros_like(self.wi)
self.wf_diff = np.zeros_like(self.wf)
self.wo_diff = np.zeros_like(self.wo)
self.bg_diff = np.zeros_like(self.bg)
self.bi_diff = np.zeros_like(self.bi)
self.bf_diff = np.zeros_like(self.bf)
self.bo_diff = np.zeros_like(self.bo)
# 状态
class LstmState:
def __init__(self, mem_cell_ct, x_dim):
self.g = np.zeros(mem_cell_ct)
self.i = np.zeros(mem_cell_ct)
self.f = np.zeros(mem_cell_ct)
self.o = np.zeros(mem_cell_ct)
self.s = np.zeros(mem_cell_ct)
self.h = np.zeros(mem_cell_ct)
self.bottom_diff_h = np.zeros_like(self.h)
self.bottom_diff_s = np.zeros_like(self.s)
self.bottom_diff_x = np.zeros(x_dim)
# LSTM各节点
class LstmNode:
def __init__(self, lstm_param, lstm_state):
# 状态和参数 store reference to parameters and to activations
self.state = lstm_state
self.param = lstm_param
# 输入x(t) 节点的非经常性输入 non-recurrent input to node
self.x = None
# 输入x(t)和 h(t-1) 非经常性输入与经常性输入同时进行 non-recurrent input concatenated with recurrent input
self.xc = None
# 前向传播
def bottom_data_is(self, x, s_prev = None, h_prev = None):
# 首节点
if s_prev is None:
s_prev = np.zeros_like(self.state.s)
if h_prev is None:
h_prev = np.zeros_like(self.state.h)
# 为反向传播存储数据
self.s_prev = s_prev
self.h_prev = h_prev
# 拼接 x(t) and h(t-1)为 xc
xc = np.hstack((x, h_prev))
# 定义参数方程
self.state.g = np.tanh(np.dot(self.param.wg, xc) + self.param.bg)
self.state.i = sigmoid(np.dot(self.param.wi, xc) + self.param.bi)
self.state.f = sigmoid(np.dot(self.param.wf, xc) + self.param.bf)
self.state.o = sigmoid(np.dot(self.param.wo, xc) + self.param.bo)
self.state.s = self.state.g * self.state.i + s_prev * self.state.f
self.state.h = self.state.s * self.state.o
self.x = x
self.xc = xc
# 导数计算
def top_diff_is(self, top_diff_h, top_diff_s):
# notice that top_diff_s is carried along the constant error carousel
ds = self.state.o * top_diff_h + top_diff_s
do = self.state.s * top_diff_h
di = self.state.g * ds
dg = self.state.i * ds
df = self.s_prev * ds
# diffs w.r.t. vector inside sigma / tanh function
# sigmoid导数
di_input = (1. - self.state.i) * self.state.i * di
df_input = (1. - self.state.f) * self.state.f * df
do_input = (1. - self.state.o) * self.state.o * do
# tanh 导数
dg_input = (1. - self.state.g ** 2) * dg
# 权重和偏置导数 diffs w.r.t. inputs
self.param.wi_diff += np.outer(di_input, self.xc)
self.param.wf_diff += np.outer(df_input, self.xc)
self.param.wo_diff += np.outer(do_input, self.xc)
self.param.wg_diff += np.outer(dg_input, self.xc)
self.param.bi_diff += di_input
self.param.bf_diff += df_input
self.param.bo_diff += do_input
self.param.bg_diff += dg_input
# compute bottom diff
dxc = np.zeros_like(self.xc)
dxc += np.dot(self.param.wi.T, di_input)
dxc += np.dot(self.param.wf.T, df_input)
dxc += np.dot(self.param.wo.T, do_input)
dxc += np.dot(self.param.wg.T, dg_input)
# save bottom diffs
self.state.bottom_diff_s = ds * self.state.f
self.state.bottom_diff_x = dxc[:self.param.x_dim]
self.state.bottom_diff_h = dxc[self.param.x_dim:]
# LSTM网络
class LstmNetwork():
def __init__(self, lstm_param):
self.lstm_param = lstm_param
self.lstm_node_list = []
# input sequence
self.x_list = []
# 输出节点遍历
def y_list_is(self, y_list, loss_layer):
"""
Updates diffs by setting target sequence
with corresponding loss layer.
Will *NOT* update parameters. To update parameters,
call self.lstm_param.apply_diff()
"""
assert len(y_list) == len(self.x_list)
idx = len(self.x_list) - 1
# first node only gets diffs from label ...
loss = loss_layer.loss(self.lstm_node_list[idx].state.h, y_list[idx])
diff_h = loss_layer.bottom_diff(self.lstm_node_list[idx].state.h, y_list[idx])
# here s is not affecting loss due to h(t+1), hence we set equal to zero
diff_s = np.zeros(self.lstm_param.mem_cell_ct)
self.lstm_node_list[idx].top_diff_is(diff_h, diff_s)
idx -= 1
### ... following nodes also get diffs from next nodes, hence we add diffs to diff_h
### we also propagate error along constant error carousel using diff_s
while idx >= 0:
loss += loss_layer.loss(self.lstm_node_list[idx].state.h, y_list[idx])
diff_h = loss_layer.bottom_diff(self.lstm_node_list[idx].state.h, y_list[idx])
diff_h += self.lstm_node_list[idx + 1].state.bottom_diff_h
diff_s = self.lstm_node_list[idx + 1].state.bottom_diff_s
self.lstm_node_list[idx].top_diff_is(diff_h, diff_s)
idx -= 1
return loss
def x_list_clear(self):
self.x_list = []
def x_list_add(self, x):
self.x_list.append(x)
if len(self.x_list) > len(self.lstm_node_list):
# need to add new lstm node, create new state mem
lstm_state = LstmState(self.lstm_param.mem_cell_ct, self.lstm_param.x_dim)
self.lstm_node_list.append(LstmNode(self.lstm_param, lstm_state))
# get index of most recent x input
idx = len(self.x_list) - 1
if idx == 0:
# no recurrent inputs yet
self.lstm_node_list[idx].bottom_data_is(x)
else:
s_prev = self.lstm_node_list[idx - 1].state.s
h_prev = self.lstm_node_list[idx - 1].state.h
self.lstm_node_list[idx].bottom_data_is(x, s_prev, h_prev)
# 损失函数
class ToyLossLayer:
"""
Computes square loss with first element of hidden layer array.
"""
# 损失函数定义
@classmethod
def loss(self, pred, label):
return (pred[0] - label) ** 2
# 节点输出求导
@classmethod
def bottom_diff(self, pred, label):
diff = np.zeros_like(pred)
diff[0] = 2 * (pred[0] - label)
return diff
输入一串连续质数,预估下一个质数
#lstm在输入一串连续质数时预估下一个质数
# 测试
import numpy as np
# from lstm import LstmParam, LstmNetwork, ToyLossLayer
def example_0():
# learns to repeat simple sequence from random inputs
np.random.seed(0)
# 隐藏层节点数和词向量维度
# parameters for input data dimension and lstm cell count
mem_cell_ct = 100
x_dim = 50
# 实例化 LSTM 参数及网络
lstm_param = LstmParam(mem_cell_ct, x_dim)
lstm_net = LstmNetwork(lstm_param)
# 前项输出
y_list = [-0.5,0.2,0.1, -0.5]
# y_list个x_dim维0-1数组
input_val_arr = [np.random.random(x_dim) for _ in y_list]
for cur_iter in range(100):
print("cur iter: ", cur_iter)
for ind in range(len(y_list)):
lstm_net.x_list_add(input_val_arr[ind])
print("y_pred[%d] : %f" % (ind, lstm_net.lstm_node_list[ind].state.h[0]))
loss = lstm_net.y_list_is(y_list, ToyLossLayer)
print("loss: ", loss)
lstm_param.apply_diff(lr=0.1)
lstm_net.x_list_clear()
if __name__ == "__main__":
example_0()
参考文章:
- [译] 理解 LSTM(Long Short-Term Memory, LSTM) 网络 - wangduo - 博客园 (cnblogs.com)
[英原文] Understanding LSTM Networks – colah’s blog - 深入理解RNN与LSTM - 知乎 (zhihu.com)
- RNN - LSTM - GRU - 知乎 (zhihu.com)
- CNN入门讲解:什么是激活函数(Activation Function) - 知乎 (zhihu.com)
- 一文概览深度学习中的激活函数 | 机器之心 (jiqizhixin.com)
- [机器学习] 神经网络-各大主流激活函数-优缺点 - CSDN
- LSTM的推导与实现 - liujshi - 博客园 (cnblogs.com)
- LSTM结构理解与python实现_FlyingLittlePig的博客-CSDN博客_lstm python
- 人人都能看懂的LSTM介绍及反向传播算法推导(非常详细) - 知乎 (zhihu.com)
- LSTM模型与前向反向传播算法 - 刘建平Pinard - 博客园 (cnblogs.com)
- 反向传播算法推导过程(非常详细) - 知乎 (zhihu.com)
- python - 为什么numpy.zeros和numpy.zeros_like之间的性能差异? - IT工具网 (coder.work)
- LSTM-基本原理-前向传播与反向传播过程推导_SZ-crystal-CSDN博客_lstm反向传播
- LSTM背后的数学原理_日积月累,天道酬勤-CSDN博客_lstm数学原理
- 从零实现循环神经网络_日积月累,天道酬勤-CSDN博客
- LSTM cell结构的理解和计算_songhk0209的博客-CSDN博客
- LSTM神经网络的详细推导及C++实现_新博客:https://aping-dev.com/-CSDN博客
- 词向量维度和隐层神经元数目的关系_atarik@163.com-CSDN博客
- 最小熵原理系列:词向量的维度应该怎么选择? - 知乎 (zhihu.com)
- 详解LSTM - 知乎 (zhihu.com)















 131
131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









