






快速下载huggingface模型和modelscope魔搭社区的使用方法汇总
一. 快速下载huggingface模型,目前推荐下面的方法
- 首推 huggingface 镜像站: https://hf-mirror.com
- 首推工具:官方的 huggingface-cli
| 方法类别 | 推荐程度 | 优点 | 缺点 | |
|---|---|---|---|---|
| 基于URL | 浏览器网页下载 | ⭐⭐⭐ | 通用性好 | 手动麻烦/无多线程 |
| 多线程下载器(hfd/IDM等) | ⭐⭐⭐⭐⭐ | 通用性好,鲁棒性好 | 手动麻烦 | |
| CLI工具 | git clone命令 | ⭐⭐ | 简单 | 无断点续传/冗余文件/无多线程 |
| 专用CLI工具 | huggingface-cli+hf_transfer | ⭐⭐⭐ | 官方下载工具链,带加速功能 | 容错性低 |
| huggingface-cli | ⭐⭐⭐⭐⭐ | 官方下载工具功能全 | 不支持多线程 | |
| Python方法 | snapshot_download | ⭐⭐⭐ | 官方支持,功能全 | 脚本复杂 |
| from_pretrained | ⭐ | 官方支持,简单 | 不方便存储,功能不全 | |
| hf_hub_download | ⭐ | 官方支持 | 不支持全量下载/无多线程 |
1. 第1种方法: 这里使用python代码hf_hub_download进行下载
python -m pip install huggingface_hub
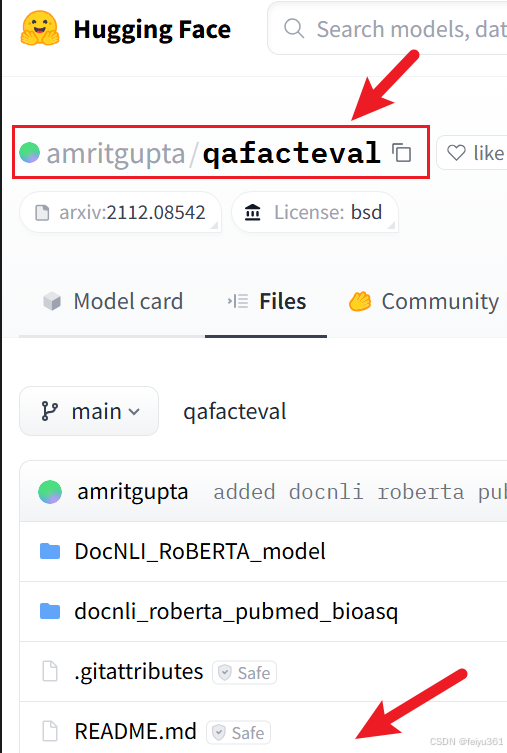
1.1 这里以 {amritgupta/qafacteval} 为例,代码如下
# 设置环境变量
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
# 代码下载
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="amritgupta/qafacteval",filename="README.md",local_dir="./qafacteval")
# 对于需要登录的模型,还需要两行额外代码:
import huggingface_hub
huggingface_hub.login("HF_TOKEN") # token 从 https://huggingface.co/settings/tokens 获取
参数
- repo_id:模型/数据集的完整id(如amritgupta/qafacteval)
- filename:Files中的某个文件(如README.md)
1.2 这里使用python代码snapshot_download进行下载
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="bigscience/bloom-560m",
local_dir="/data/user/test",
proxies={"https": "http://localhost:7890"},
max_workers=8
)
对于需要登录的模型,还需要两行额外代码:
import huggingface_hub
huggingface_hub.login("HF_TOKEN") # token 从 https://huggingface.co/settings/tokens 获取
2. 第2种方法: 命令行下载
2.0 安装下载库
python -m pip install "huggingface_hub[cli]"
2.1 设置环境变量
创建一个文件
touch ~/.bashrc
针对不同的系统进行设置
win的是
$env:HF_ENDPOINT = "https://hf-mirror.com"
linux的是
export HF_ENDPOINT=https://hf-mirror.com
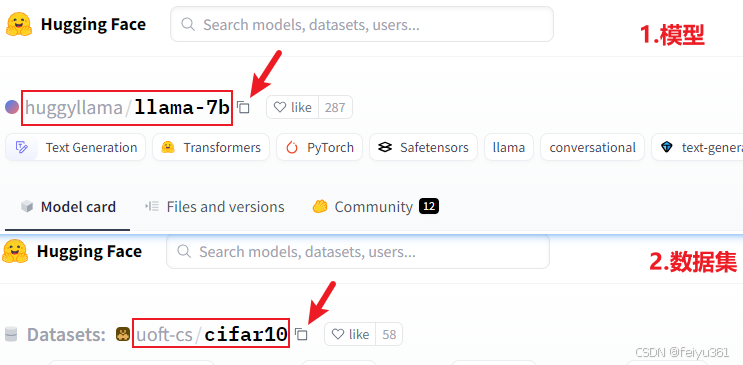
2.2 开始下载, 两个模型和数据集为例
2.3 开始下载模型
huggingface-cli download huggyllama/llama-7b --local-dir /data/llama-7b
- –local-dir:安装路径(若路径不存在,则自动创建)
2.4 下载数据集
huggingface-cli download --repo-type dataset uoft-cs/cifar10 --local-dir cifar10
- —repo-type:类型(模型/数据集)
- –local-dir:安装路径(若路径不存在,则自动创建)
3. 第3种方法: hf_transfer(基于rust的下载方式) ! 推荐
3.1 安装依赖库
python -m pip install -U hf-transfer
3.1 设置 HF_HUB_ENABLE_HF_TRANSFER 环境变量为 1。
Windows Powershell
$env:HF_HUB_ENABLE_HF_TRANSFER = 1
$env:HF_ENDPOINT = "https://hf-mirror.com"
Linux
export HF_HUB_ENABLE_HF_TRANSFER=1
3.2 开启后使用方法同 huggingface-cli:
huggingface-cli download tencent/Hunyuan3D-2 --local-dir ./checkpoints
- resume-download 参数,指的是从上一次下载的地方继续,一般推荐总是加上该参数,断了方便继续。然而如果你一开始没有开启 hf_transfer,下载中途停掉并设置环境变量开启,此时用 --resume-download 会由于不兼容导致 hf_transfer 开启失败!总之观察是否有进度条就可以知道有没有开启成功,没有进度条就说明开启成功!
二. ModelScope魔搭社区的使用
- https://modelscope.cn/
1. 安装下载库
pip install modelscope
2. 选择 {模型文件} 点击右侧的下载会有提示命令
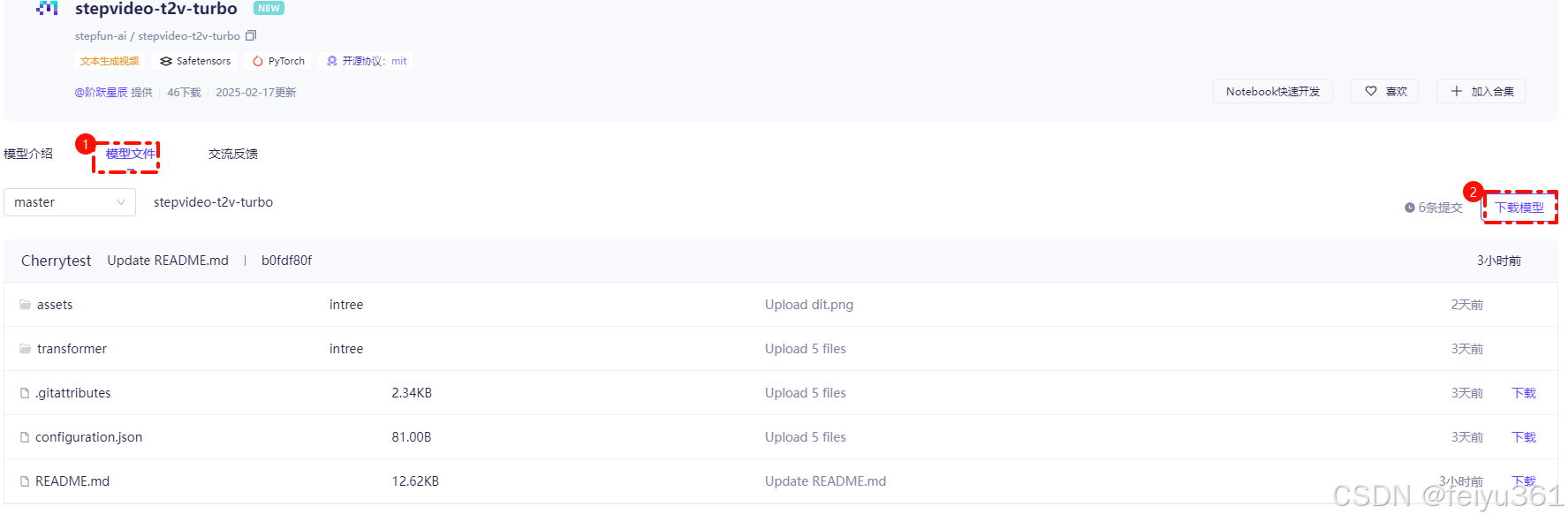
2.1 SDK下载
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('stepfun-ai/stepvideo-t2v-turbo')
2.2 命令行下载
pip install modelscope
2.3 下载完整模型repo
modelscope download --model stepfun-ai/stepvideo-t2v-turbo


















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









