







一、SparkSQL和Hive的异同
- Hive和Spark均是:“分布式SQL计算引擎”
- 均是构建大规模结构化数据计算的绝佳利器,同时SparkSQL拥有更好的性能
- 都可以运行在YARN上
二、SparkSQL的数据抽象
一、Pandas-DataFrame
- 二维表数据结构
- 单机(本地)集合
二、SparkCore-RDD
- 无标准数据结构,存储什么数据均可
- 分布式集合(分区)
三、SparkSQL-DataFrame
- 二维表数据结构
- 分布式集合(分区)
四、SparkSQL For JVM - Dataset
- SparkSQL其实有三类数据抽象对象
- SchemaRDD对象(已废弃)
- DataSet对象:可用于Java、Scala语言
- DataFrame对象:可用于Java、Scala、Python
三、DataFrame
一、RDD
- 有分区的
- 分布式的
- 弹性的
- 存储任意结构数据
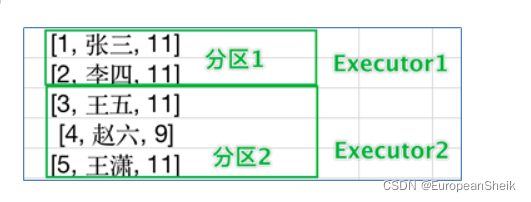
三、DataFrame
- 有分区的
- 分布式的
- 弹性的
- 存储二维表结构数据
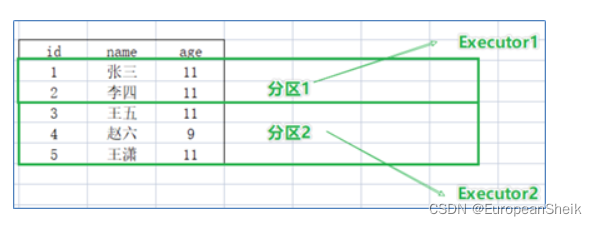
四、DataFrame VS DataSet VS RDD
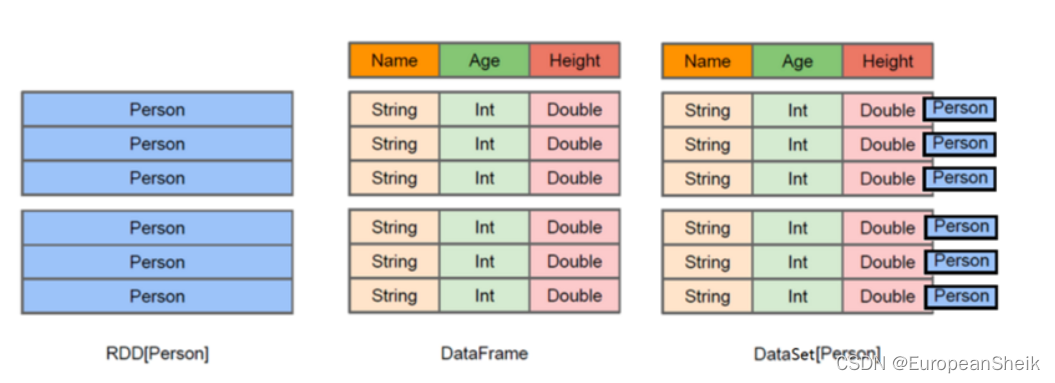
- RDD按对象原有形式进行存储(如存储Person类对象)
- DataFrame按照表格形式组织数据格式
- DataSet同样按照表格形式组织数据,只是对比DataFrame多了泛型的支持。由于Python不支持泛型特性,所以,对于Python语言来说,使用DataFrame就比较合适。除了泛型方面,DataFrame和DataSet没有区别
五、SparkSession对象
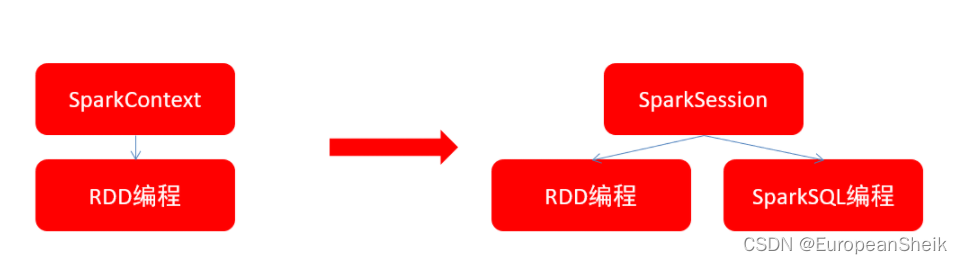
在RDD阶段,程序的执行入口对象是:SparkContext
在Spark2.0之后,推出了SparkSession对象,作为Spark编码的统一入口对象
SparkSession对象可以:
- 用于SparkSQL编程作为入口对象
- 用于SparkCore编程,可以通过SparkSession对象中获取到SparkContext















 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









