







实验名称 25条流域水质情况评价 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
实验题目已知:25条流域水质量各指标的数据,其中含氧量越高越好;PH值越接近7越好;细菌总数越少越好;植物性营养物量介于10-20之间最佳,超过20或低于10均不好。根据上面四个指标评价下表25条河流的水质情况。
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
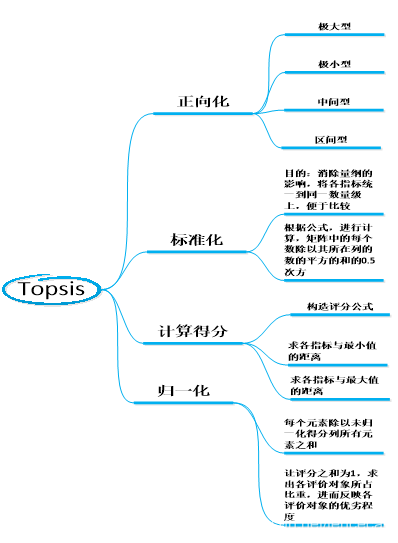
问题分析生活中河流水质量各评价指标类型往往不同,即各指标优劣程度的数值体现不同,有的指标含量越多越好,有的则越少越好,有的越趋于某个值越好,有的落在某个区间最好,离区间越近越好;在评价之前,我们首先得制定评价方法,统一评分规则,否则就会造成尺度的混乱;决策层中有大量原始数据,评价对象较多(远远大于两个)。综合考虑以上因素,我们决定通过优劣解距离法建立评价模型来解决25条流域水质情况评价的问题。该方法既可以充分利用原始数据,又能反应不同流域的水质差距,且计算过程简单,模型无需检验,数据真实可靠。
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
模型建立及求解思路 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
通过仔细分析与研究,我们认为采用TOPSIS法建立评价模型能够准确地反映各评价对象之间的差距,较为合理地解决该问题。首先统一评分规则,再根据优劣解距离法的基本思想构造评分公式找出最优方案与最劣方案,最后通过公式求得各评价对象的比重来反映河流水质情况。 求解思路:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
模型求解步骤 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1)工作区新建矩阵 2)打开从Excel表中粘贴需要的数据 3)关闭,右击该矩阵另存为.mat文件保存位置和topsis.m文件一致 4)使用命令Load 文件名.mat直接调用数据 2.正向化 1)定义一维数组存放指标类型 2)通过for循环循环判断所有指标类型 3)通过if语句具体执行相应的正向化代码 4)指标类型为0,极大型指标无需正向化 5)指标类型为1,极小型指标正向化处理
6)指标类型为2,中间型指标正向化处理(mid为中间值)
7)指标类型为3,区间型指标正向化处理 注:M为距离区间最远的距离,即,当x在区间[a,b]内时,正向化后的值为1; 当x小于区间下限a时, 当x大于区间上限b时,
3.标准化 1)通过for循环的嵌套遍历所有元素 2)通过公式进行标准化
3)使用repmat函数,sum函数及乘方运算
4.计算得分 1)构造评分公式:
评分公式变形:
2)Topsis的思想:最优解即最大值,最劣解即最小值。 定义最大值:Z+用于存放标准化矩阵中每一列的最大值 定义最小值:Z-向量存放标准化矩阵中每一列的最小值 定义第i个(i=1,2,...,n)个评价对象与最大值的距离:等于第i行每一个元素与其所在列的最大值的差的平方和的0.5次方
定义第i个(i=1,2,...,n)个评价对象与最大值的距离:等于第i行每一个元素与其所在列的最小值的差的平方和的0.5次方
3)评分公式
4)通过zeros定义行矩阵G、DP、DN分别存放未归一化的得分,与最优解的距离和与最劣解的距离(matlab代码中的公式实现) 5)通过max函数求出标准化矩阵中每一列的最大值和最小值,即公式中的Z+和Z-(matlab代码中的公式实现) 6)通过两个矩阵先暂存,D+和D-求解过程中根号下边的值 5.归一化 1)将评分之和归一,求出各评价对象的比重。 2)公式: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Matlab计算结果及绘图
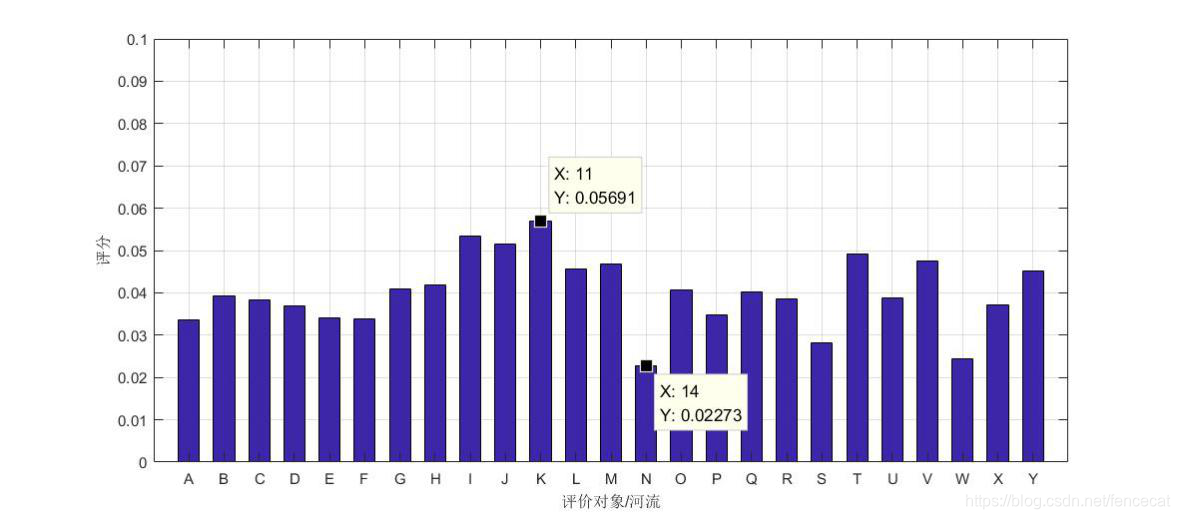
S =[ 0.0337 0.0393 0.0383 0.0370 0.0341 0.0339 0.0409 0.0419 0.0533 0.0516 0.0569 0.0455 0.0467 0.0227 0.0406 0.0347 0.0402 0.0385 0.0281 0.0492 0.0388 0.0475 0.0244 0.0372 0.0451]
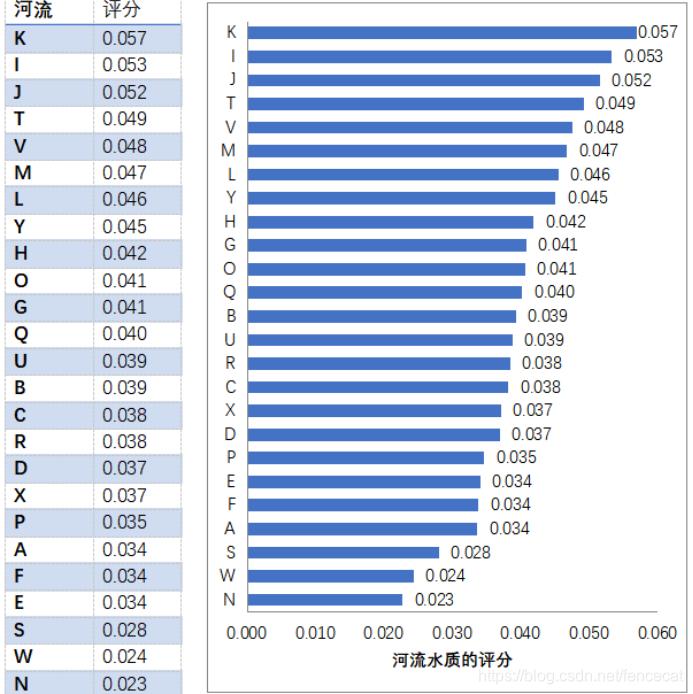
图表1 25条流域水质情况
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Excel数据汇总 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
结论分析: 从上面的条形统计图中,我们可以清楚地看出河流水质评分的多少以及各评价对象之间的差距。我们可以得出这样的结论:在25条流域中,河流K的水质最好,为本题中的最优解;河流N的水质最差,为本题中的最劣解;根据得分S,我们可以直接看出各评价方案即河流水质之间的差距以及它们同最优解和最劣解的距离。 我们的评价得分可以应用于实际的生产活动中。例如:根据河水PH值的评分,看河水是否能用于灌溉、海产养殖等,通过控制河流的植物性营养物量来防止一些藻类植物生长过快而带来的水污染等,还可以针对不同流域的水质量情况,提出科学合理的河流管理方案和治理方案。
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
实验代码
%%调用函数实现topsis法 %导入数据 load data_heliushuju.mat
%% % 指标正向化 A=zhengxianghua(X) %% % 标准化 Z=biaozhunhua(A) %% % 找出最优解和最劣解并计算得分 G=defen(Z) %% % 对得分进行归一化 S=guiyihua(G)
function A=zhengxianghua(X) [r,c]=size(X) Max_total=max(X)%每一列数据的最大值,它是一个行向量 Min_total=min(X)%每一列数据的最小值,它是一个列向量 T=zeros(1,c) for j=1:c disp('请输入指标类型,0表示极大型,1表示极小型,2表示中间型,3表示区间型') T(j)=input('please enter a value for the indicator type:') end C=zeros(1,c) A=zeros(r,c)%这里我用A矩阵存放正向化后的数据 for j=1:c if T(j)==0%无需正向化 for i=1:r A(i,j)=X(i,j);%直接将原数值赋值给矩阵A end elseif T(j)==1%该列数据为极小型,需要正向化 for i=1:r A(i,j)=Max_total(j)-X(i,j); end elseif T(j)==2%中间型指标,需要正向化 mid=input('中间值mid:')%中间值也就是公式中的x(best) for i=1:r C(i)=abs(X(i,j)-mid);%abs函数是绝对值函数 end Max_mid=max(C);%用Max_mid偏离中间值最远的距离 for i=1:r A(i,j)=1-C(i)./Max_mid;%公式计算正向化后的值,赋值给A end
elseif T(j)==3%指标类型是区间型指标的情况
a=input('请输入区间下限:')%区间下限,公式中的a b=input('请输入区间上限:')%区间上限,公式中的b e=(a-Min_total(j));%求出离区间下限最远的那个值并赋值给c d=(Max_total(j)-b);%求出离区间上限最远的那个值并赋值给d M=max(e,d);%比较e和d的值,并把最大值赋值给M for i=1:r if (X(i,j)>=a)&&(X(i,j)<=b) %Xi在区间内,正向化后值为1 A(i,j)=1;
elseif X(i,j)<a % Xi小于a,计算正向化后的值并赋值给A A(i,j)=1-(a-X(i,j))./M;
elseif X(i,j)>b% xi大于b,计算正向化后的值并赋值给A A(i,j)=1-(X(i,j)-b)./M ; end end end end
function Z=biaozhunhua(A) [r,c]=size(A) for i=1:r for j=1:c D=sum(A.*A).^0.5 ; Z=A./repmat(D,r,1); end end
function G=defen(Z) [r,c]=size(Z) E=zeros(r,c) F=zeros(r,c) DP=zeros(r,1) DN=zeros(r,1) G=zeros(r,1) Max_Z=max(Z);%存放标准化后每一列的最大值 Min_Z=min(Z);%存放标准化后每一列的最小值 for i=1:r for j=1:c E(i,j)=(Max_Z(j)-Z(i,j)).*(Max_Z(j)-Z(i,j));%D+公式根号下面的部分 F(i,j)=(Min_Z(j)-Z(i,j)).*(Min_Z(j)-Z(i,j));% D-公式根号下面的部分 end DP(i)=sum(E(i,:)).^0.5;%第i个评价对象与最大值的距离。 DN(i)=sum(F(i,:)).^0.5;%第i个评价对象与最小值的距离 G(i)=DN(i)/(DP(i)+DN(i)); end
function S=guiyihua(G) r=size(G,1) S=zeros(r,1) for i=1:r S(i)=G(i)/sum(sum(G)); end
|
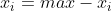
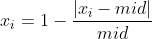
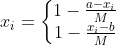
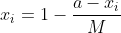
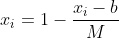
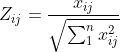
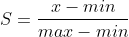
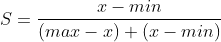
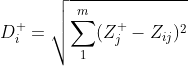
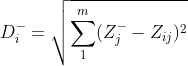
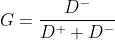
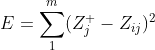
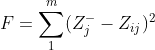
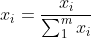


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











