






最近GPT o3和GPT o4-mini的图片推理能力又上了新的台阶,导师叫我调研一下基于大模型的图像推理的相关研究,于是花了几天时间整理了一下近年来VLM(visual language model)的相关研究。
目录
一、什么是VLM
视觉语言模型(Visual Language Model)是通过将大语言模型 (LLM) 与图像编码器相结合构建的多模态 AI 系统,使大语言模型具有理解图像的能力。用户可以通过输入图像、视频并通过文字进行指导来与VLM进行交互,VLM会根据输入文字中的提示信息在图像或视频中进行推理,并完成对应任务。
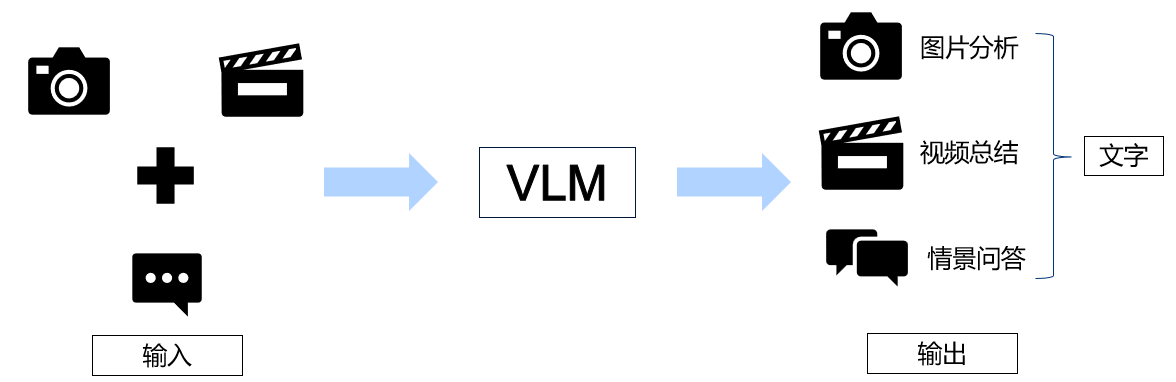
VLM相比于传统的卷积神经网络更为灵活,传统的CNN若要完成某一特定的任务,必须在对应的数据集上进行训练,且后续使用该网络时不能出现训练数据集中不存在的类别。若要使某一训练好的CNN识别更多类别的物体或是完成一项新的任务,必须重新收集训练数据集并在新的数据集上重新进行训练。除此之外,CNN无法通过自然语言进行交互。
因此,VLM具有以下优点:
- 多模态处理能力
- 自然语言理解与处理能力
- 全语义理解能力
- 零/少样本学习能力
- 较强的交互性
二、VLM结构
2.1 VLM结构
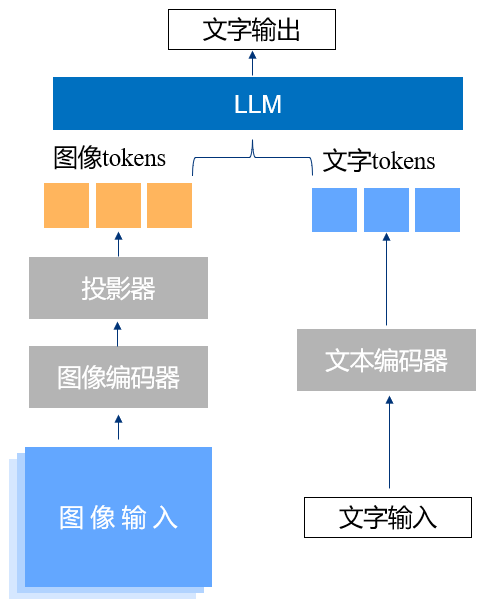
VLM一般由下面几个部分组成:
- 图像编码器:基于transformer架构的CLIP模型,在数百万个图像-文本对上进行预训练,使这一层具有识别图像并将其与文本关联的能力。
- 投影器:将视觉编码器的输出转化为tokens,这些tokens作为LLM的输入。投影器可以使用MLP或交叉注意力层。
- 文本编码器:将输入的文字转化为tokens。
- LLM:大语言模型,根据图像tokens与文本tokens进行推理并生成文本或图像结果。
2.2 VLM类别
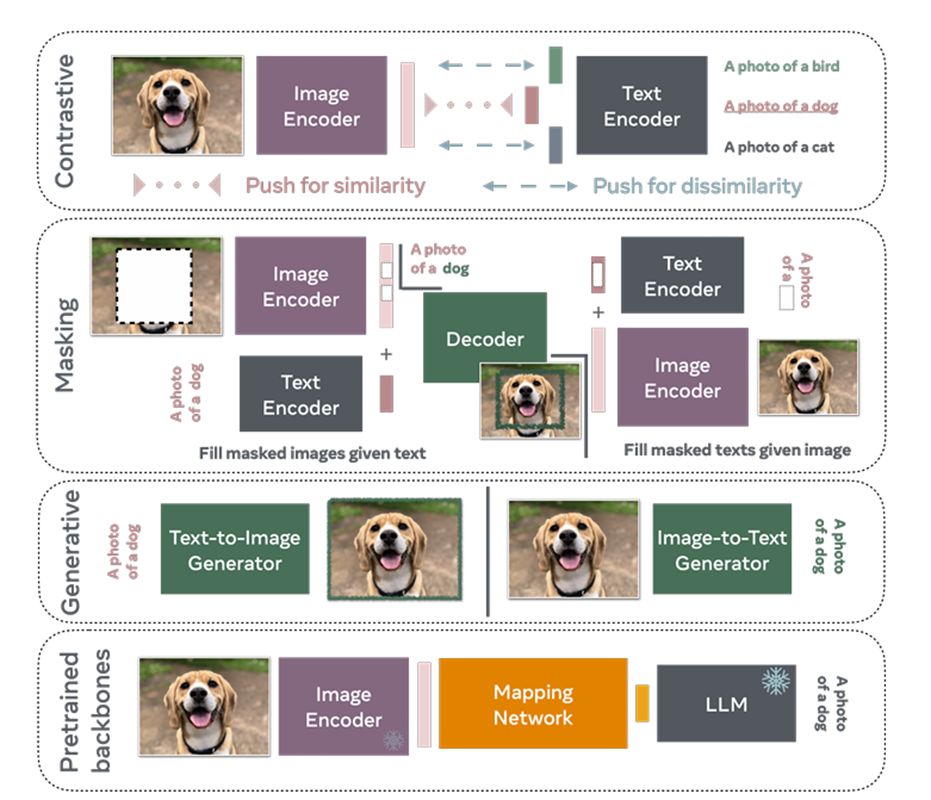
基于transformer架构,共有四种不同的VLM训练模式(training paradigm):
- 基于对比学习(Contrastive)的VLM
- 基于掩码(Masking)的VLM
- 基于生成式(Generative)的VLM
- 基于预训练主干网络(Pretrained Backbones)的VLM
2.2.1 基于对比学习的VLM
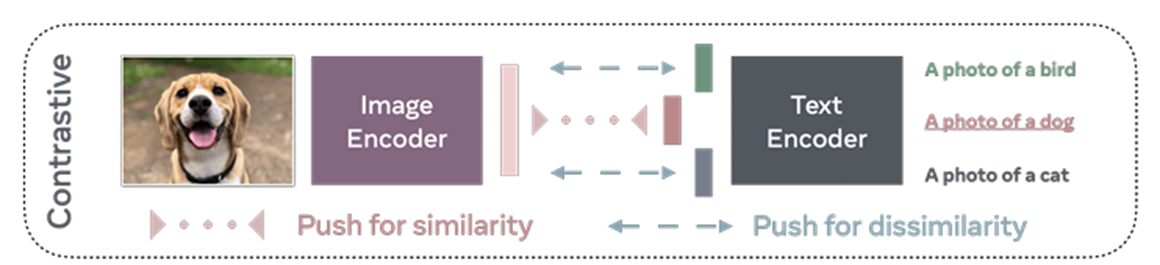
将不同模态的输入编码得到特征,通过对比学习损失拉近正例的特征距离,推远负例的特征距离,从而学习良好的特征表示。从能量模型角度理解,模型会为来自目标分布的数据(正例)分配低能量,为其他数据(负例)分配高能量。
常用的InfoNCE损失函数,通过计算正例对和所有负例对在模型表示空间中的距离(如余弦相似度),让模型学习预测最可能匹配的示例对,为其他负例对分配较低概率 。 InfoNCE损失函数定义如下:![]() 其中(𝑖,𝑗)是正例对,𝑧𝑖 , 𝑧𝑗是其特征表示,𝐶o𝑆𝑖𝑚表示余弦相似度。
其中(𝑖,𝑗)是正例对,𝑧𝑖 , 𝑧𝑗是其特征表示,𝐶o𝑆𝑖𝑚表示余弦相似度。
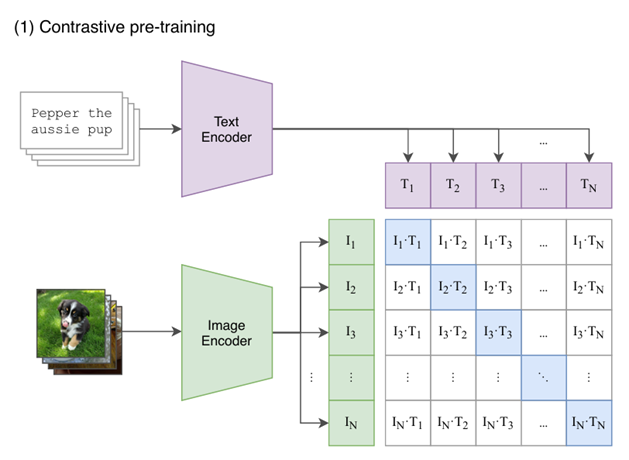
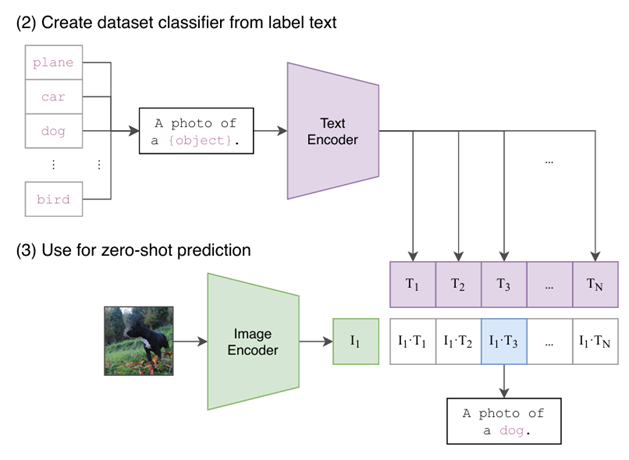
Contrastive Language–Image Pre-training (CLIP)是使用InfoNCE的一个常见的方法。正例对被定义为一张图片与其真实描述的样本对,而负例对被定义为这张图片与它的错误描述(同一个小批量中其他图片的描述)。CLIP 训练随机初始化的视觉和文本编码器,以使用对比损失将图像及其描述映射到类似的嵌入向量。
SigLIP与CLIP类似,但SigLIP没有使用InfoNCE,取而代之的是使用基于二进制交叉熵的原始NCE损失,这使得SigLIP在更小的批量上具有比CLIP更好的0-shot性能。
Latent language image pretraining (Llip)通过一个交叉注意力模块,依据目标字幕来对图像的编码进行调节,因为一张图像的描述可以有很多种。这样可以增加模型的特征表达能力。
2.2.2 基于掩码的VLM
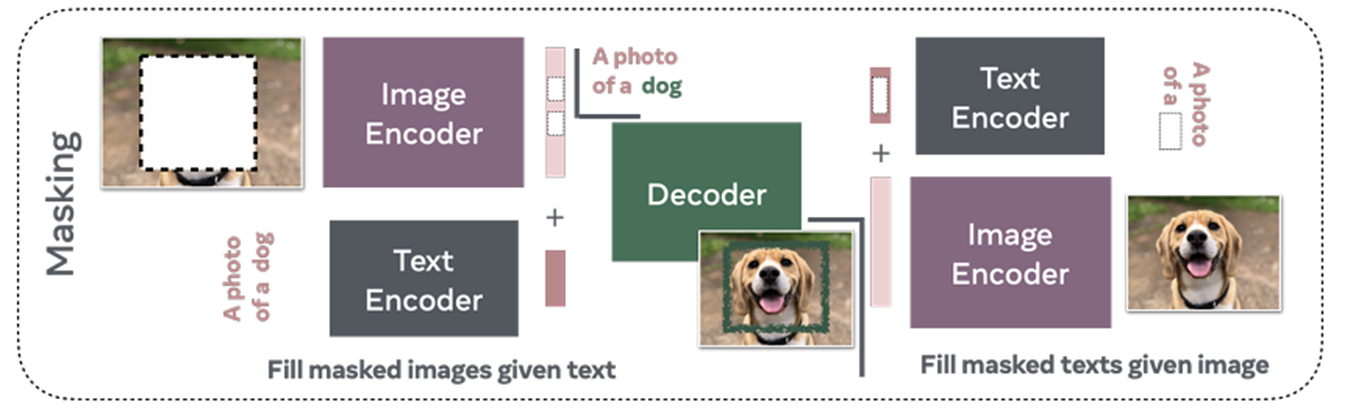
在图像编码器部分,对图像的一些区域或小块进行掩码。模型需要根据未掩码的图像部分以及文本信息来重建被掩码的图像区域。这有助于模型学习图像的空间结构和语义信息,以及图像与文本之间的跨模态对应关系。
在文本编码器部分,类似于BERT中的做法,随机选择一部分文本标记进行掩码处理。模型的任务是根据未掩码的文本标记以及图像信息来预测被掩码的文本标记。通过这种方式,模型可以学习到文本的上下文信息以及文本与图像之间的关联,提高对语言的理解和生成能力。
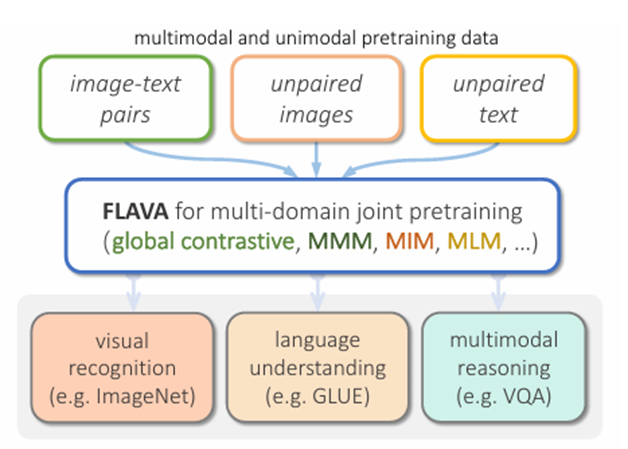
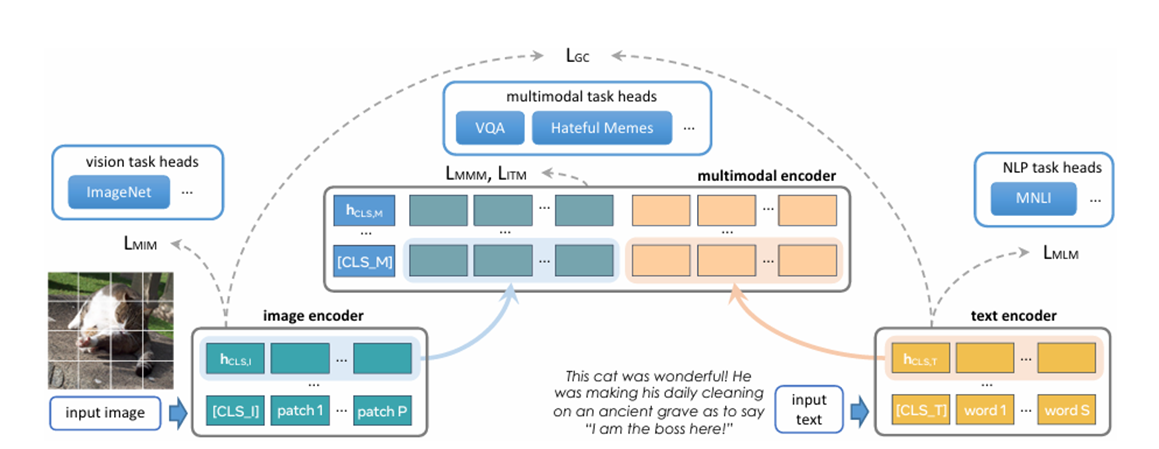
Foundational Language And Vision Alignment(FLAVA)是第一个基于掩码的VLM,它的图像编码器采用ViT架构,将图像分割成小块并进行线性嵌入和 Transformer 处理,输出图像隐藏状态向量,其中包含分类标记([CLS_I])。文本编码器利用 Transformer 对文本输入进行标记化和嵌入处理,转化为向量形式后再通过 Transformer 编码,输出隐藏状态向量和分类标记([CLS_T])。多模态编码器则融合图像和文本编码器的隐藏状态,它借助 Transformer 框架内的线性投影和交叉注意力机制,将视觉和文本信息整合在一起,突出多模态分类标记([CLS_M])。
2.2.3 基于生成式的VLM

前两种VLM主要关注文字与图像进行抽象转化后的映射关系,而基于生成式的VLM主要关注文字与图像之间的相互转换。
- 根据图像生成图像对应描述的模型有Contrastive Captioner (CoCa)等;
- 根据描述文字生成图像的模型有Stable Diffusion、Imagen、Parti等;
- 同时生成文字与图像的多模态生成模型有Chameleon团队的Chameleon、CM3leon等。
2.2.4 基于预训练主干网络的VLM

前面的三种VLM都需要使用大量的图片-文本对进行训练,且VLM的训练成本较高,而基于预训练主干网络的VLM使用训练好的开源的图像编码器(如前面提到的CLIP、CoCa等)与LLM(如Vicuna language model、Llama等),这两部分的参数被“冻结”,不参与整体网络的训练,参与训练的部分为负责匹配图像编码器输出与LLM输入tokens的匹配网络,即VLM架构中的投影器projector,以实现将图像编码器提取的视觉特征准确投射到tokens上,从而让模型能够将视觉信息与LLM相结合。
三、VLM训练
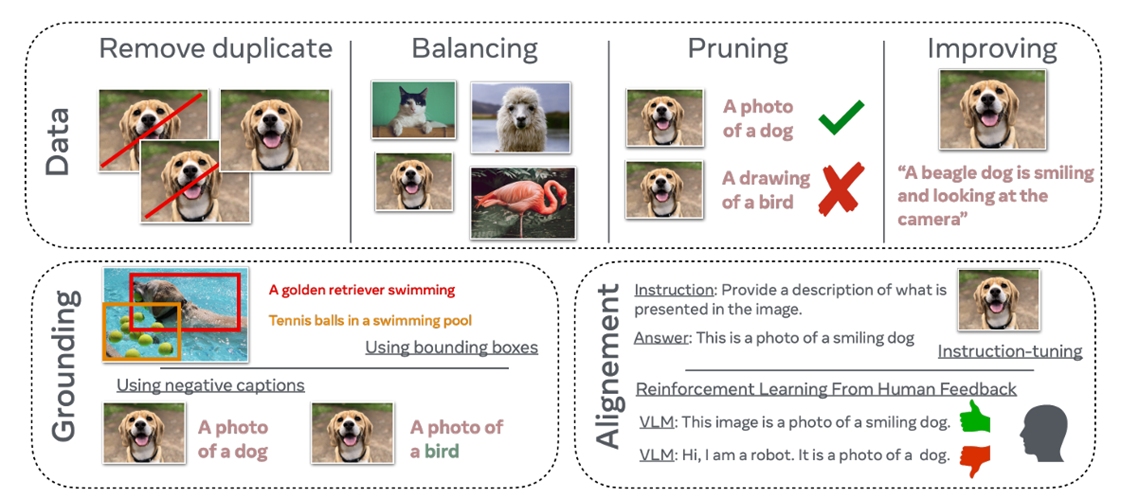
由于scaling law的存在,单纯地增加模型的参数量或训练数据大小,对模型性能的提升不显著。因此在训练VLM时需要引入一些训练策略来突破scaling law。
在训练数据上,常用的策略有:
- 去除训练集中重复的数据
- 保证训练集中各个类别出现的概率平衡
- 对训练集进行数据修剪操作,保留高质量的、正确的训练数据
- 使用人工标注的细粒度数据集进行训练,提升训练数据的质量
常用的训练策略有:
- 使用边界框或负样本以提升模型的基础定位能力
- 微调,包括基于LoRA的方法、基于prompt的方法、基于adapter的方法、基于mapping的方法等
- 基于人类反馈提升模型的细粒度对齐度
3.1 优化训练数据
3.1.1 VLM训练数据修剪
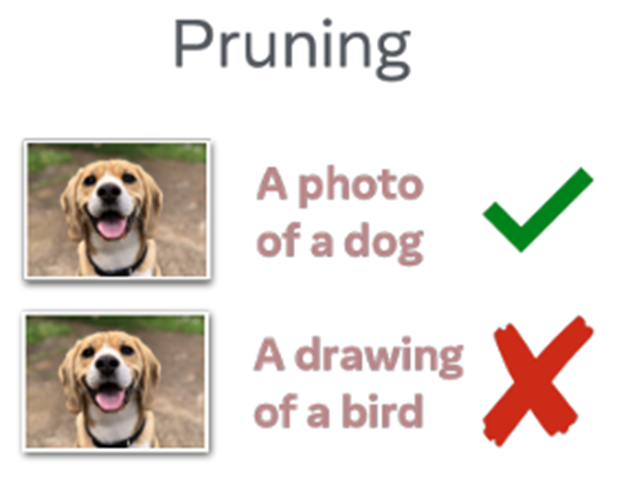
训练数据的质量直接影响到了VLM的性能,论文DataComp中表明可以通过数据修剪(data pruning)技术提升训练效率与VLM模型的表达能力。
VLM的数据修剪方法有以下三类:
- 去除低质量图像文本对数据的启发式方法:
单模态:只考虑数据单一方面的性质,文本方面去除文本复杂度低、non-English alt-text的数据;图像方面去除图像分辨率低、宽高比异常的数据。
多模态:考虑图像文本对的整体性质,使用图像分类器去除重复度高、文本描述异常、图像中不存在物体的数据。
- 利用预训练的视觉语言模型根据图像 - 文本对的多模态对齐程度对其进行排序,丢弃对齐不佳的数据对的自举方法。
- 创建多样化且平衡的数据集的方法 。
3.1.2 使用合成数据集
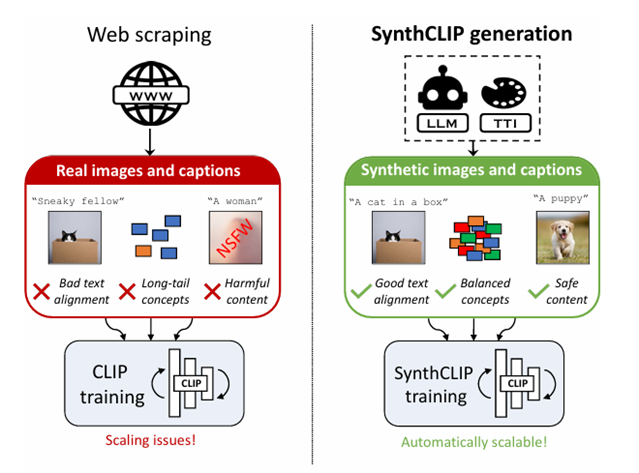
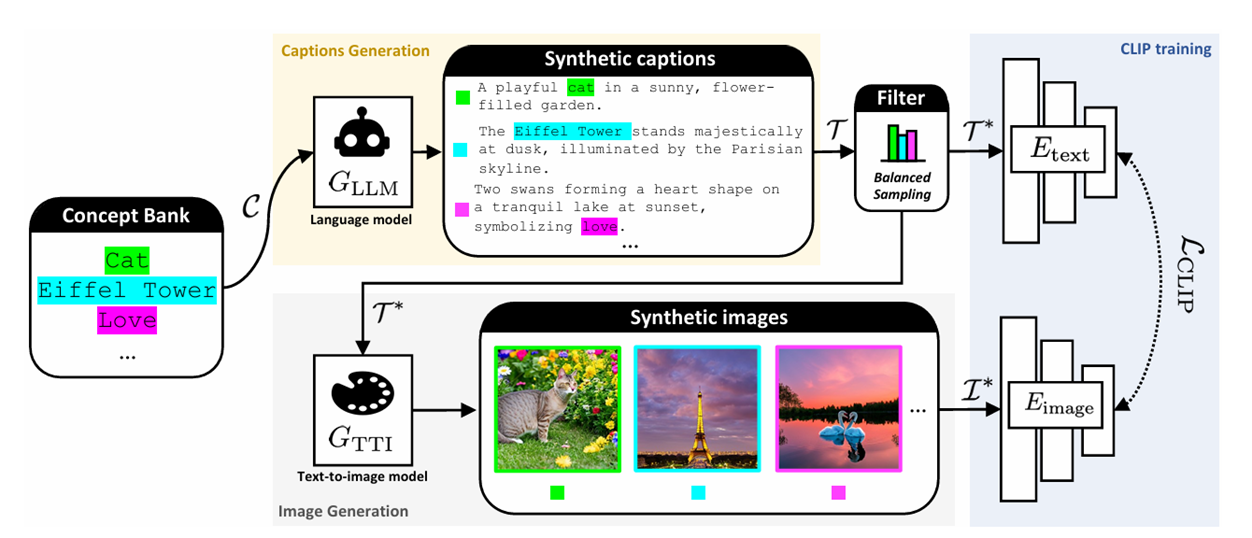
类似自监督学习,不使用从网络上爬取的图像文本对,取而代之的是使用预训练好的模型生成图像文本对数据,再将这些数据用于自身训练。这些生成的数据对齐度良好、数据构成均匀、生成内容安全,可以增强训练数据的多样性,也会引入部分训练噪声来提高模型的泛化能力。
3.1.3 使用数据增强

例如CLIP🚀中使用的非对称增强,生成一对弱增强与强增强样本,其中弱增强样本对图像进行尺度范围 (0.5, 1)的随机剪裁,对文本进行以0.8的概率随机删除文中的stop words;强增强样本对图像进行如下操作:以更宽泛(0.08, 1)的尺度进行随机剪裁,再以0.8的概率对图像对比度、亮度、饱和度和色调进行抖动处理,以0.2的概率进行灰度化处理,以0.5的概率进行高斯模糊、以0.5的概率进行水平翻转。对文本进行如下操作:若同一图像有多个caption,每次增强操作从中独立且均匀地采样一个caption;若只有一个caption,对这个captain进行stop words删除并随机结合同义词替换、单词插入/删除、句子改组三种操作中的一种。
3.1.4 使用交错数据集
Interleaved data(交错数据)是一种多模态数据,将不同模态数据按特定顺序交叉排列组合的数据形式。使用交错数据可帮助模型学习图像和文本之间的细粒度对齐关系,提高模型在视觉问答、图像字幕生成等任务中的性能。
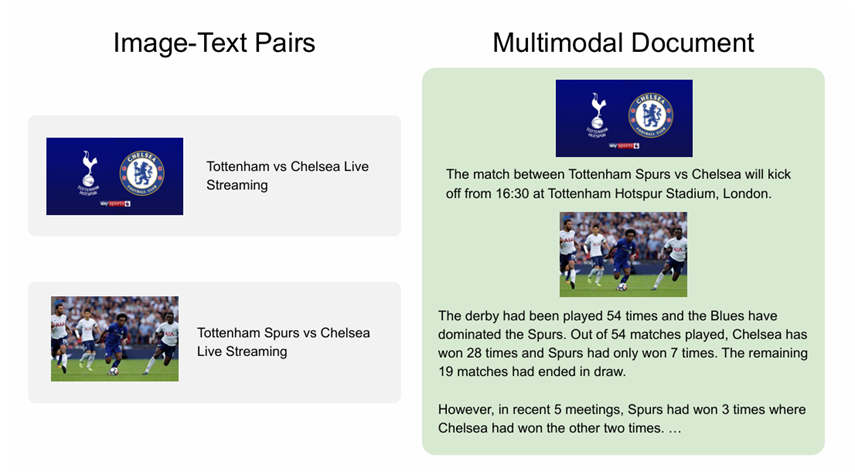
OBELICS数据集,是一种自然的交错数据集,在图文交错的网页上爬取得到。

MMC4数据集,是一种合成的交错数据集,图片从互联网中收集得到,并在图片的上下文中加入文本描述。
3.1.5 其他VLM训练数据优化策略
评价图像文本对数据中文本的质量、图像的质量、图像和文本之间的对齐度等。但整体地评价多模态与交错数据质量的研究还有所欠缺,缺少一种系统性的评价指标。
使用如DCI数据集之类的细粒度人工标注数据集,但细粒度的数据集数量较小,不适用于从零开始训练VLM模型,更适用于对模型的fine-tuning。
3.2 优化训练策略
3.2.1 提升VLM的基础关联能力

Grounding(基础关联能力)是VLM需要提升的一个重要能力。对于文字,VLM需要正确地理解用户输入的文字提示,并将这些提示与图片中的信息相关联。对于图片,VLM需要理解图片中的各种关系:物体A在物体B的左边或右边、物体A是否属于某一类别、统计图中物体A的数量、理解物体A的颜色与纹理等。目前还没有一种简单有效的方法可以提升VLM的基础关联能力,常用的方法有使用边界框标注与负样本标注等。
3.2.2 提升VLM生成的对齐度
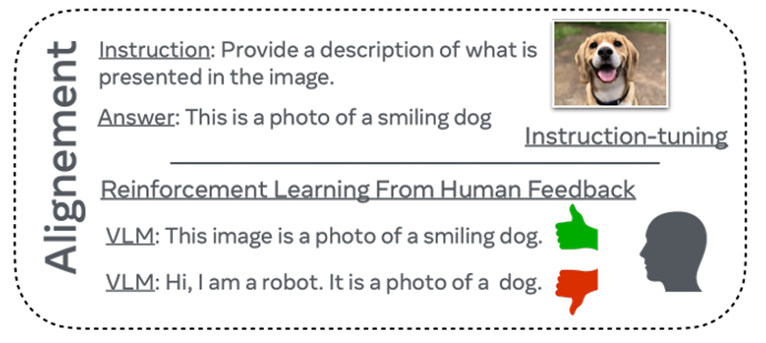
与其他生成式模型一样,VLM的生成也要符合用户的偏好。提升VLM对齐度的方法与语言模型领域的方法一致,常用的方法有指令微调与基于人类反馈的强化学习。
在包含指令、输入和期望输出的监督数据上对VLM进行微调。通常,与预训练数据相比,指令微调数据集要小得多,指令微调数据的规模从几千到十万个样本不等。(LLaVa、InstructBLIP、OpenFlamingo)
目的是使模型输出与人类偏好保持一致。方法为训练一个奖励模型,以匹配人类对模型响应好坏的偏好。虽然指令调整需要有监督的训练样本,而收集这些样本成本可能很高,但RLHF利用辅助奖励模型来模拟人类偏好。然后,VLM会与奖励模型一起进行微调,以使输出与人类偏好一致。
3.2.3 其他VLM训练方向
VLM除了需要理解图像中的物体与物体间的关系之外,也需要理解图像中的文本信息(这里的文本信息是图像中的文本,而不是VLM多模态输入中的文本)。与多模态大语言模型类似,VLM需要在不经过OCR训练的情况下实现图像的文本识别与理解。目前的研究方向有:使用细粒度富含文本的数据进行指令微调(LLaVAR)、处理高分辨率图像中的细粒度文本(Monkey)、解耦场景文本识别模块与多模态大语言模型(Lumos)
由于VLM参数量较大,在某些应用场景下重新训练VLM或对VLM整体的参数进行微调不太可行,因此需要根据实际应用任务对VLM的部分组件的参数进行高效的fine-tuning。现有的PEFT方法有:基于低秩适配器(LoRa)的方法、基于提示(Prompt)的方法、基于适配器(Adapter)的方法以及基于映射(Mapping)的方法
四、VLM基准测试

评价VLM的性能就是要评价VLM是否能将文本与图片进行正确映射,或者VLM能否根据图片中的线索进行推理并正确回答问题。同时,VLM的输出不应该出现对物体的错误描述、错误分类、幻觉等错误信息。VLM基准测试主要有下面几种:
4.1 视觉语言能力基准测试
视觉语言能力基准测试是一系列的测试,用于评估VLM 是否能够将特定的单词或短语与相应的视觉线索联系起来,可以直观地评价VLM视觉-语言映射的学习效果。这一系列的测试如下:
4.2 VLM偏差与差异的基准测试
VLM中的偏差(bias)是指模型在处理视觉和语言信息时,对不同群体或类别表现出的不公平、不一致或不准确的倾向。例如,在给定不同种族和性别的医生图片,并询问“描述这个人的 5 个关键词”时,模型可能会对黑人或肥胖人群生成更多带有负面或刻板印象的词汇。评价VLM偏差与差异的方法如下:
首先定义偏差类型,如人口统计学中的偏差(性别、年龄、肤色、种族等)、语义关联偏差(“程序员”与男性、“护士”与女性等),评估的数据集可以是基于真实的数据集也可以是合成数据集,在数据集上评估模型对这些偏差的分类情况。
该方法不是评估分类等特定的最终任务,而是分析文本和图像的表示之间的关系。嵌入空间分析可以揭示在评估任务中难以衡量的学习关系。Grounded-WEAT/SEAT通过计算文本嵌入与图像嵌入的相似性,检测模型是否将特定群体属性(如性别、种族)与刻板概念关联。
4.3 幻觉基准测试
VLM中的幻觉(bias)是指模型生成图像无关、错误或虚构的信息,包含对象级幻觉(生成图像中不存在的对象)、属性级幻觉(错误描述对象的属性)、关系级幻觉(虚构对象间的交互)、上下文级幻觉(生成与图像无关的上下文)。主流的测试方法有CHAIR (Caption Hallucination Assessment with Image Relevance)与POPE (Polling-based Object Probing Evaluation)。

CHAIR可以检测对象级幻觉,使用预定义的对象词汇表对比VLM生成描述中的对象与图像真实标注的对象,计算幻觉率。

POPE生成“图中是否有[对象]?”的提问,然后统计模型回答的准确率。
4.4 记忆能力基准测试

记忆能力基准测试评估模型是否过度记住了训练数据中的特定样本或敏感信息,而不是学习通用的跨模态关联。Déjà Vu Memorization(既视感记忆检测)是一个常用的方法,用于衡量VLM对训练数据中特定图片对象或细节的记忆能力,即使这些细节未在对应的图片描述中以文字的形式存在。
在该方法中,选择一个目标训练样本,其中图像包含某些未在文本中描述的对象(如背景中的物体)。使用一个未接触过该训练样本的参考模型,在公开数据集(ImageNet)中搜索与目标文本最相似的图像。对比目标模型和参考模型对同一批图像的预测结果。对目标模型的训练样本文本,找到公开数据集中与之最相似的 k 张图像。使用目标模型和参考模型分别预测这些图像中的对象。计算两模型在对象检测精度和召回率上的差异。若目标模型在未描述的物体上显著优于参考模型(更高的召回率),则表明目标模型可能记忆了训练数据中的视觉细节。
参考文献
Bordes, F., Pang, R. Y., Ajay, A., Li, A. C., Bardes, A., Petryk, S., … Chandra, V. (2024). An introduction to vision-language modeling.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … Sutskever, I. (2021). Learning transferable visual models from Natural Language Supervision.
A. Singh et al., "FLAVA: A Foundational Language And Vision Alignment Model," 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Sorscher, B., Ganguli, S., Geirhos, R., Shekhar, S., Morcos, A. S. (2022). Beyond neural scaling laws: beating power law scaling via data pruning.
Hasan Abed Al Kader Hammoud, Hani Itani, Fabio Pizzati, Philip Torr, Adel Bibi, and Bernard Ghanem(2024). Synthclip: Are we ready for a fully synthetic clip training?
Enrico Fini, Pietro Astolfi, Adriana Romero-Soriano, Jakob Verbeek, and Michal Drozdzal(2023). Improved baselines for vision-language pre-training.
Wanrong Zhu, Jack Hessel, Anas Awadalla, Samir Yitzhak Gadre, Jesse Dodge, Alex Fang, Youngjae Yu, Ludwig Schmidt, William Yang Wang, and Yejin Choi(2023). Multimodal c4: An open, billion-scale corpus of images interleaved with text.
Hugo Laurençon, Lucile Saulnier, Leo Tronchon, Stas Bekman, Amanpreet Singh, An ton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M Rush, Douwe Kiela, Matthieu Cord, and Victor Sanh(2023). OBELICS: An open web-scale filtered dataset of in terleaved image-text documents.
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. (2018). Object Hallucination in Image Captioning.
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. (2023). Evaluating Object Hallucination in Large Vision-Language Models.
Bargav Jayaraman, Chuan Guo, and Kamalika Chaudhuri. (2024). Déjà vu memorization in vision-language models.
Zongxia Li et al. (2025). A Survey of State of the Art Large Vision Language Models: Alignment, Benchmark, Evaluations and Challenges.

















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









