







1.记录神经网络相关技术发展
神经网络思想的提出已经是75年前的事情了,现今的神经网络和深度学习的设计理论是一步步的完善的。在这漫长的发展岁月中,有一些取得关键突破的闪光时刻。其中有1960年代,基本网络结构设计完善后的黄金时代,也有在1969年异或问题被提出后(人们惊奇的发现神经网络模型连简单的异或问题也无法解决),神经网络模型被束之高阁的黑暗时代。虽然在1986年,新提出的多层的神经网络解决了异或问题,但随着90年代后理论更完备并且实践效果更好的SVM等机器学习模型的兴起,神经网络并未得到重视。真正的兴起是在2010年左右,基于神经网络模型改进的技术在语音和计算机视觉任务上大放异彩,也逐渐被证明在更多的任务(自然语言处理以及海量数据的任务)上有效。至此,神经网络模型重新焕发生机,并有了一个更加响亮的名字:深度学习。
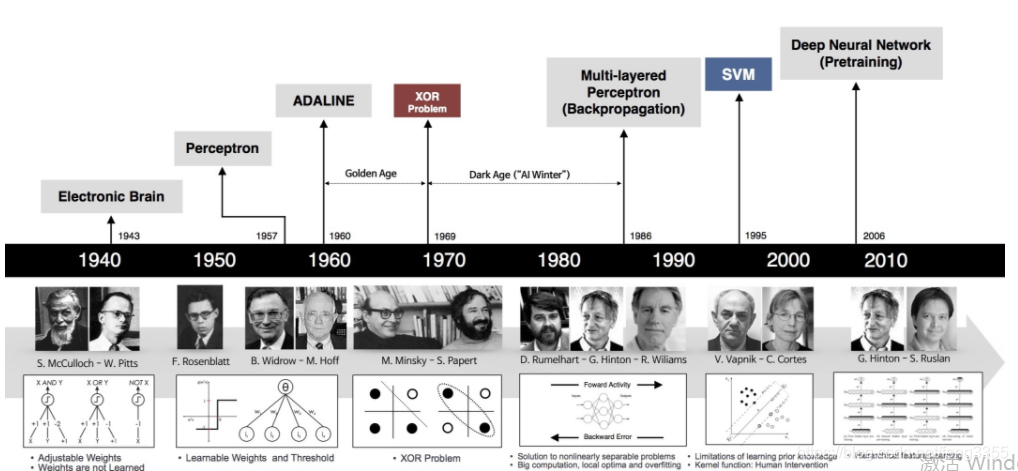
早在1998年,一些科学家就已经使用神经网络模型识别手写字母图像了。但深度学习在计算机视觉应用上的兴起,还是在2012年ImageNet比赛上,使用AlexNet做图像分类。如果比较下98年和12年的模型,会发现两者在网络结构上非常类似,仅在一些细节上有所优化。在这十四年间计算性能的大幅提升和数据量的爆发式增长,促使模型完成了从“简单的字母识别”到“复杂的图像分类”的跨越。
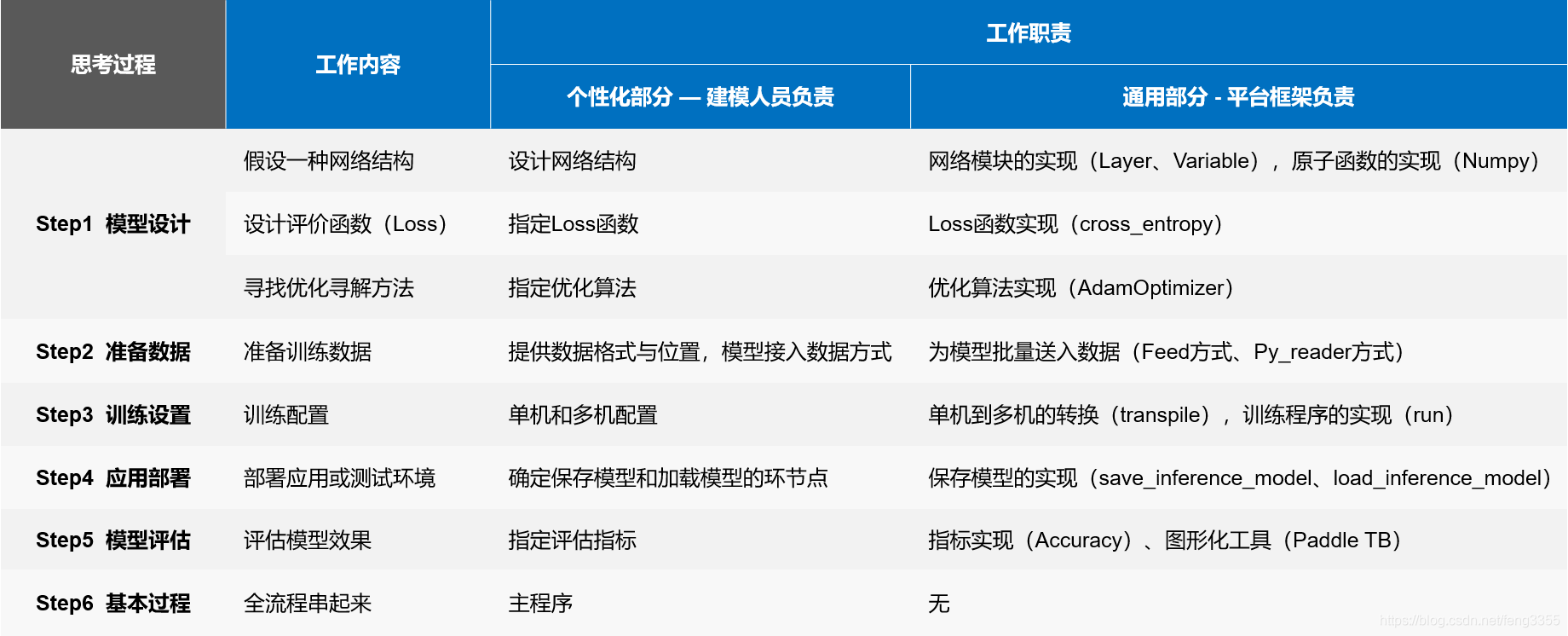
但在深度学习框架下的诸多算法结构有较大的通用性,例如常用与计算机视觉的卷积神经网络模型(CNN)和常用于自然语言处理的长期短期记忆模型(LSTM),均可以分为组网模块,梯度下降的优化模块,预测模块等。这使得抽象出统一的框架成为了可能,并大大降低了编写建模代码的成本。一些相对通用的模块,如网络基础算子的实现,各种优化算法等均可以由框架实现。建模者只需要关注数据处理,配置组网的方式,以及用少量代码串起训练和预测的流程即可.

数据处理
数据处理包含五个部分:数据导入、数据形状变换、数据集划分、数据归一化处理和封装load data函数。数据预处理后,才能被模型调用。
数据归一化处理
对每个特征进行归一化处理,使得每个特征的取值缩放到0~1之间。这样做有两个好处:一是模型训练更高效;二是特征前的权重大小可以代表该变量对预测结果的贡献度(因为每个特征值本身的范围相同)。
随机梯度下降法( Stochastic Gradient Descent)
在上述程序中,每次损失函数和梯度计算都是基于数据集中的全量数据。对于波士顿房价预测任务数据集而言,样本数比较少,只有404个。但在实际问题中,数据集往往非常大,如果每次都使用全量数据进行计算,效率非常低,通俗的说就是“杀鸡焉用牛刀”。由于参数每次只沿着梯度反方向更新一点点,因此方向并不需要那么精确。一个合理的解决方案是每次从总的数据集中随机抽取出小部分数据来代表整体,基于这部分数据计算梯度和损失来更新参数,这种方法被称作随机梯度下降法(Stochastic Gradient Descent,SGD),核心概念如下:
- min-batch:每次迭代时抽取出来的一批数据被称为一个min-batch。
- batch_size:一个mini-batch所包含的样本数目称为batch_size。
- epoch:当程序迭代的时候,按mini-batch逐渐抽取出样本,当把整个数据集都遍历到了的时候,则完成了一轮的训练,也叫一个epoch。启动训练时,可以将训练的轮数num_epochs和batch_size作为参数传入。
下面结合程序介绍具体的实现过程,涉及到数据处理和训练过程两部分代码的修改。
观察上述Loss的变化,随机梯度下降加快了训练过程,但由于每次仅基于少量样本更新参数和计算损失,所以损失下降曲线会出现震荡。
下图:深度学习框架示意图
Yan LeCun是最早将卷积神经网络应用到图像识别领域的,其主要逻辑是使用卷积神经网络提取图像特征,并对图像所属类别进行预测,通过训练数据不断调整网络参数,最终形成一套能自动提取图像特征并对这些特征进行分类的网络.

















 1764
1764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









