







背景
平时写代码,总感觉飘在空中,不知道自己的这行代码底层怎么和硬件打交道,此外软件层面很多框架都是开源的,有问题看看源码就行,也不算有特别的门槛,不过编译原理发现周围人了解的不多,所以打算学一下,这里通过记录博客的方式来督促自己进行学习。借用Ralph Waldo Emerson的一句话:
“If you learn only methods, you’ll be tied to your methods. But if you learn principles, you can devise your own methods.”
相关概念
编译器:从源码到机器语言的翻译
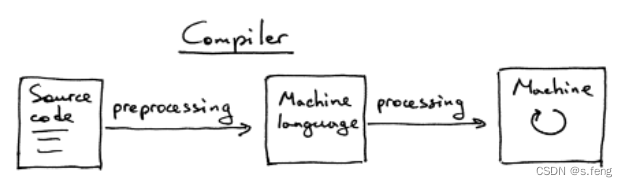
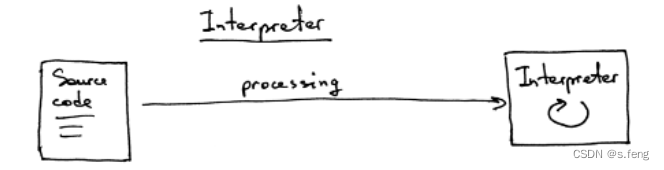
解释器:处理源码,但是还没有把他翻译成机器语言
代码示例
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, EOF = 'INTEGER', 'PLUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, PLUS, or EOF
self.type = type
# token value: 0, 1, 2. 3, 4, 5, 6, 7, 8, 9, '+', or None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# client string input, e.g. "3+5"
self.text = text
# self.pos is an index into self.text
self.pos = 0
# current token instance
self.current_token = None
def error(self):
raise Exception('Error parsing input')
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
text = self.text
# is self.pos index past the end of the self.text ?
# if so, then return EOF token because there is no more
# input left to convert into tokens
if self.pos > len(text) - 1:
return Token(EOF, None)
# get a character at the position self.pos and decide
# what token to create based on the single character
current_char = text[self.pos]
# if the character is a digit then convert it to
# integer, create an INTEGER token, increment self.pos
# index to point to the next character after the digit,
# and return the INTEGER token
if current_char.isdigit():
token = Token(INTEGER, int(current_char))
self.pos += 1
return token
if current_char == '+':
token = Token(PLUS, current_char)
self.pos += 1
return token
self.error()
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def expr(self):
"""expr -> INTEGER PLUS INTEGER"""
# set current token to the first token taken from the input
self.current_token = self.get_next_token()
# we expect the current token to be a single-digit integer
left = self.current_token
self.eat(INTEGER)
# we expect the current token to be a '+' token
op = self.current_token
self.eat(PLUS)
# we expect the current token to be a single-digit integer
right = self.current_token
self.eat(INTEGER)
# after the above call the self.current_token is set to
# EOF token
# at this point INTEGER PLUS INTEGER sequence of tokens
# has been successfully found and the method can just
# return the result of adding two integers, thus
# effectively interpreting client input
result = left.value + right.value
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
运行上述代码:
calc> 1+2
5
整个流程:首先是获取这个字符串"1+2", 然后把字符串拆开三个token, token我觉得简单理解为一个个的对象就行,token是有类型和值的,这里1和2就是整数类型,'+'就是加法类型,这里还有一个结尾类型,不过这个token没用到。
名词解释:其中把这个字符串拆成token的过程叫做语法分析,在解释器中这一部分叫做语法分析器(lexical analyzer), 也有很多人叫他:scanner、tokenizer
从上面的流程可以知道,字符串被拆为:INTEGER -> PLUS -> INTEGER,接下来解释器要要去处理这个结构,这里用了expr这个函数,这个函数目的就是负责判断解析出来的结构是不是这个结构(INTEGER -> PLUS -> INTEGER),最后给出计算结果,到此位置,这个解释器成功的处理你给的一串字符串"1+2"。














 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









