







背景
当下做AI基本都用float16进行推理,目前用的比较多的还有bfloat16, 这里我们只讨论float16的这个数据类型。float16有个优点是大部分的GPU或者部分CPU支持float16的计算,速度快于float32, 此外显存或者内存也可以减少一半,基于这个特点,所以有必要彻底弄清楚float16。
- float32
float32就是我们日常说的float,一共四个字节,32个bit位,下面是125.5的bit分布。置于是怎么算的可以参考浮点数计算方法

- float16
float16也称为半精度,一共两个字节,16个bit位。IEEE规定的格式是下面这种,一个符号位,5个指数,10个尾数(计算和float32原理一样,也是11位,有一个隐式位)。参考wiki
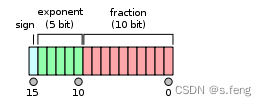
这里简单给一些demo计算:
测试一、
flaot16: 0 01111 0000000000
sign = 0
exponent = 15
fraction (二进制)= 1.0000000000
可以看到移动位数=exponent-15=0, 所以fraction的小数点不需要浮动,结果就是1
测试二、
flaot16: 0 01101 0101010101
sign = 0
exponent = 13
fraction (二进制)= 1.0101010101
可以看到移动位数=exponent-15= -2, 所以fraction的小数点需要往左浮动2位,fraction就编程了0.010101010101,计算结果为pow(2, -2) + pow(2, -4) + pow(2, -6)+pow(2, -8) + pow(2, -10)+ pow(2, -12) ≈ 0.333252
如何转
我们知道在C++上没有float16这个数据类型,16bit的数据类型只有uint16_t这个基础类型,所以fp32转成fp16的话需要用uint16_t或者unsigned short来当容器。流程就把fp32的整数部分转为二进制,小数部分转为二进制,算出小数点浮动的位置。
举例:
float:0.333252
转成二进制为:0.010101010101…
可以知道往左浮动了2位,所以exponent=13, 对应二进制为01101
float16:0 01101 0101010101
这是一个粗略的想法,其实还要考虑各种数值范围什么的,考虑到比较麻烦,这里有一些存在的api:
方法一:x86intrin.h
#include <x86intrin.h>
#include <iostream>
int main()
{
float f32;
unsigned short f16;
f32 = 3.14159265358979323846;
f16 = _cvtss_sh(f32, 0);
std::cout << f32 << std::endl;
f32 = _cvtsh_ss(f16);
std::cout << f32 << std::endl;
return 0;
}
g++ -march=native a.cpp
在这里_cvtss_sh函数就可以把float32转为float16。如果我们想看看fp16里面是不是符合预期,可以自己打印出来看看,工具函数如下:
void show(int num)
{
stack<bool> s;
for(int i=0; i<sizeof(float)*8; i++)
{
s.push(num&1);
num >>= 1;
}
for(int i=0; i<32; i++)
{
int tmp = s.top();
s.pop();
cout<<tmp<<" ";
}
cout<<endl;
}
union Bits
{
float f;
int i;
uint16_t ih;
};
int main()
{
Bits bit;
float f32;
uint16_t f16;
f32 = 3.14159265358979323846;
bit.f = f32;
show(bit.i);
f16 = _cvtss_sh(f32, 0);
std::cout << f32 << std::endl;
bit.i = 0;
bit.ih = f16;
show(bit.i);
f32 = _cvtsh_ss(f16);
std::cout << f16 << std::endl;
return 0;
}
方法二:cuda_fp16.h
在cuda中,也有针对host端给出的float16定义,不过类型名叫做half, 用户可以直接利用该类型:
#include <iostream>
#include <cuda_fp16.h>
int main()
{
half h_num = 0.234567f;
h_num = h_num * 2;//实现了一些基础算子
//h_num *= 2; 没有实现*=这个操作符
cout<<h_num<<endl;//会被隐式转为float
}
方法三:自己实现
可以参考stackoverflow
这里高赞版本已经更新为模板了,之前的版本可以参考PaddlePaddle中的paddle/phi/common/float16.h:105L, 这个就是借鉴stackoverflow的上高赞版本的第一次回答的方案。
综上
下面都是在cpu端可以实现float32转float16的相关手段。
explicit float16(float val) { //构造函数
#if defined(__cuda__)
half tmp = __float2half(val);
x = *reinterpret_cast<uint16_t*>(&tmp);
// arm给的实现方式
#elif defined(__arm__)
float32x4_t tmp = vld1q_dup_f32(&val);
float16_t res = vget_lane_f16(vcvt_f16_f32(tmp), 0);
x = *reinterpret_cast<uint16_t*>(&res);
#elif defined(__x86__)
x = _cvtss_sh(val, 0);
#else
// Conversion routine adapted from
// http://stackoverflow.com/questions/1659440/32-bit-to-16-bit-floating-point-conversion
Bits v, s;
v.f = val;
uint32_t sign = v.si & sigN;
v.si ^= sign;
sign >>= shiftSign; // logical shift
s.si = mulN;
s.si = s.f * v.f; // correct subnormals
v.si ^= (s.si ^ v.si) & -(minN > v.si);
v.si ^= (infN ^ v.si) & -((infN > v.si) & (v.si > maxN));
v.si ^= (nanN ^ v.si) & -((nanN > v.si) & (v.si > infN));
v.ui >>= shift; // logical shift
v.si ^= ((v.si - maxD) ^ v.si) & -(v.si > maxC);
v.si ^= ((v.si - minD) ^ v.si) & -(v.si > subC);
x = v.ui | sign;
#endif
}















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









