







背景
最近在看cufft这个库,传统的cufftPlan3d()这种plan接口逐渐被nvidia舍弃了,说是要用最新的cufftPlanMany,这个函数呢又依赖一个什么Advanced Data Layout(地址),最终把这个api搞得乌烟瘴气很难理解,为了理解自己写了一些测试来验证各个参数的意思,这里简单做一下总结。下面是函数声明以及对应的参数解释,看不懂的话可以结合后面的例子琢磨琢磨。
cufftResult cufftPlanMany(
cufftHandle *plan,
int rank,
int *n,
int *inembed,
int istride,
int idist,
int *onembed,
int ostride,
int odist,
cufftType type,
int batch);

1D
先说说这函数能干啥,因为对于很多信号而言是需要采样的,对于搞过信号的同学理解起来比较方便,比如来了一串信号a=[0,1,2,3,4,5,6,7,8,9], 如果采样频率是2,那么就会得到b=[0,2,4,6,8]长度为5的信号,搁在以前,你要做fft的话,你需要自己提前写好代码把b摘出来,但是现在不需要了,直接用a信号就可以,nv把这个工作做了,具体如下:
//一维不饶很好理解
int rank = 1,
int n[] = {5}, //这个值代表这个维度的fft()的采样后信号长度
int inembed[] = {10}, //代表这个维度的输入信号长度
int istride = 2, // 代表采样步长<可以理解为采样频率>,这个就很蠢,每个维度<2维,3维下>必须一样
int idist = 10, // 一个batch的原始信号长度,一般是等于inembed,
//但有时候需要截取一部分原始信号作为输入信号,所以是小于等于inembed尺寸
int onembed[] = 5, //同上
int ostride = 1, //同上
int odist = 5, //同上
int batch = 1;
图示如下,这里没有画输出,意思和输入一样,接下来做个实验试试。

根据上面的例子可以知道,dist代表batch的大小,尺寸一定要大于nembed的。一个简单的的是代码如下:
#include <stdio.h>
#include <cuda_runtime.h>
#include <cufft.h>
int main() {
cufftHandle plan;
cufftComplex *data;
cufftComplex *d_data;
const int batch_n = 2;
int idist_n = 11;
cudaMalloc(&d_data, sizeof(cufftComplex) * idist_n * batch_n);
data = (cufftComplex *)malloc(sizeof(cufftComplex) * idist_n * batch_n);
for (int i = 0; i < 11; ++i) {
data[i].x = i;
data[i].y = 0;
printf("(%f, %f) ",data[i].x, data[i].y);
};
printf("\n");
for (int i = 11; i < 22; ++i) {
data[i].x = i - 1;
data[i].y = 0;
printf("(%f, %f) ",data[i].x, data[i].y);
};
printf("\n");
cudaMemcpy(d_data, data, sizeof(cufftComplex) * idist_n * batch_n, cudaMemcpyHostToDevice);
int n[1] = { 5 }; // 1D FFT 尺寸
int inembed[] = { 10 }; //
int istride = 2; //
int idist = idist_n; //
int onembed[] = { 8};
int ostride = 1; //
int odist = 10; //
cufftPlanMany(&plan, 1, n, inembed, istride, idist, onembed, ostride, odist, CUFFT_C2C, batch_n);
cufftExecC2C(plan, d_data, d_data, CUFFT_FORWARD);
cudaMemcpy(data, d_data, sizeof(cufftComplex) * batch_n * idist_n, cudaMemcpyDeviceToHost);
printf("FFT result:\n");
for (int i = 0; i < batch_n; ++i) {
for (int j = 0; j < idist_n; ++j) {
int idx = i * idist_n + j;
printf("(%f, %f)\t", data[idx].x, data[idx].y);
}
printf("\n");
}
cufftDestroy(plan);
cudaFree(d_data);
free(data);
return 0;
}
2D
2d的话其实本质和上面一样,但是采样却很蠢,只有stride只有一个大小,也就是横竖的采样步长一样。
3D
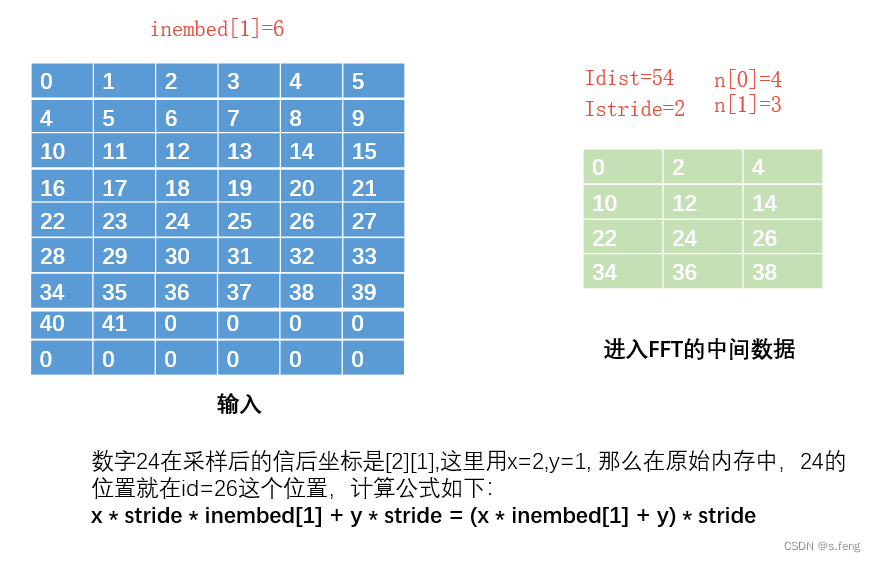
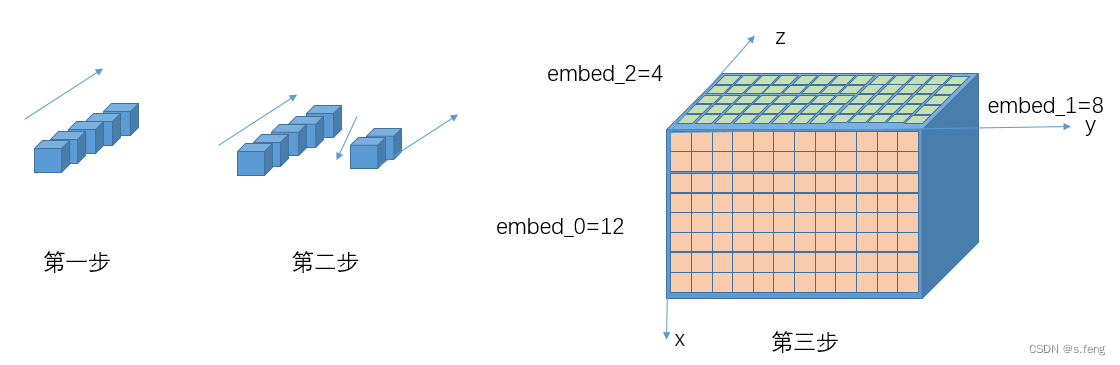
3D的数据数据排布有点反常,一般3d数据都是正视图的那一个平面先排满后,再排第二个切面,但是这里是先排满一个俯视图平面后,再排下一个切面,这里的embed_2=Nz, embed_1=ny, embed_0 = nx, 如下图,图中的坐标系是我们经常使用的方式。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









