






AutoFIS 总结
AutoFIS是华为提出的一种自动选取二阶以及更高阶特征的特征抽取算法
论文开篇指出:在CTR预估中,交叉特征对于推理模型是非常重要的,在现有的深度模型中,交叉特征都是被手动设计或简单的罗列。罗列出所有的交叉特征不仅需要巨大的内存消耗和计算复杂度,而且无用交叉特征还会移入噪声并使得模型训练复杂化。因此提出了该算法—AutoFIS。
AutoFIS的作用:
- 去除无用交叉特征,甚至是有害的交叉特征
- 基于FM-AUTOFIS网络选取的二阶、三阶交叉特征,可以应用到 state-of-the-art 模型中,即用简单的模型进行交叉特征选择,然后应用到另外的模型中
AutoFIS工作原理
autoFIS模型训练分两个阶段:search stage 和 re-train stage。
search stage:通过 “结构参数”(后面会讲到)学习到各个交叉特征的对于结果的重要性
re-train stage:去除无用交叉特征,然后进行模型训练
对比现有特征选择工具
- Gradient boosting decision tree (GBDT):
缺点:该方法可以将为逻辑回归和FFM模型选择交叉特征。但是实际上,树模型更加适合于连续特征,而不适用于推荐系统中,维度很高的类别数据
- AutoCross技术
该特征选择技术要求 需要训练整个模型 去评估选择出来的交叉特征集合,但是候选集很多。 m个特征的二阶特征就有 2 C m 2 2^{C_{m}^{2} } 2Cm2 个。 AutoCross具体过程为:
(未看过AutoCross,对其不是很了解)
缺点:AutoCross得到交叉特征不一定适用于Deep model。AutoFIS对于AutoCross的优点:
AutoFIS只需要运行search stage就可以评估出所有交叉特征的重要性,这种方法的效率更高;并且得到的交叉特征可以直接应用到search stage中的Deep model中。

模型介绍

上图分别是FM、DeepFM、IPNN。下面就详细介绍一下FM模型:
FM模型
Feature Embedding Layer:
embedding如何得到,请自行百度,大概方法如下:

该层的输出为
[
e
1
,
e
2
,
.
.
.
,
e
m
]
[e_{1}, e_{2},..., e_{m}]
[e1,e2,...,em], 即m个embedding特征。
Feature Interaction Layer.
通过 该层得到交叉特征, 首先通过 “inner product of the pairwise feature interaction”。
[
<
e
1
,
e
2
>
,
<
e
1
,
e
3
>
.
.
.
,
<
e
m
−
1
,
e
m
>
]
[<e_{1}, e_{2}>,<e_{1}, e_{3}>..., <e_{m-1}, e_{m}>]
[<e1,e2>,<e1,e3>...,<em−1,em>]
该层的输出为
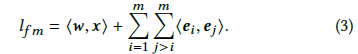
何为inner product: 在数学中,点积(德语:Skalarprodukt;英语:Dot Product)又称数量积或标量积(德语:Skalarprodukt;英语:Scalar Product),是一种接受两个等长的数字序列(通常是坐标向量)、返回单个数字的代数运算。在欧几里得几何中,两个笛卡尔坐标向量的点积常称为内积(德语:inneres Produkt;英语:Inner Product),见内积空间。
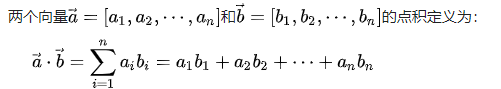
AutoFIS详解
AutoFIS算法的工作原理
AutoFIS工作过程可以分为两个阶段,即搜索阶段,决定各个交叉特征的重要性;训练阶段,基于选择出的交叉特征进行再次训练。
搜索阶段:论文中引进一个gate operation(门操作),个数为等于交叉特征的个数,即
2
C
m
2
2^{C_{m}^{2}}
2Cm2个,在autofis算法中,并不是从整个候选集中离散的形式筛选小候选集,而是引进一个结构参数 a,这样就可以基于梯度下降法去学习稀疏的结构参数a。结构参数如下图所示。

AutoFIS中,interaction layer的输出如下所示,在搜索阶段,
a
i
,
j
a_{i, j}
ai,j代表每个交叉特征对于最终预估结果的重要性。
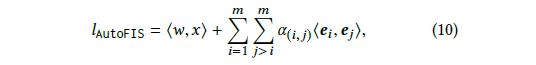
在搜索阶段,论文提出,由于
a
i
,
j
{a_{i,j}}
ai,j与
<
e
i
,
e
j
>
{<e_{i}, e_{j}>}
<ei,ej>是一起训练的,所以
a
i
,
j
{a_{i,j}}
ai,j的结果并不能表明
<
e
i
,
e
j
>
{<e_{i}, e_{j}>}
<ei,ej>的重要性。(tip:我是这样想的,在工作当中,如果让一个时刻和你一起玩耍的人,给你打绩效的话,那么结果一定不是很公证的。)
为了解决
a
i
,
j
{a_{i,j}}
ai,j与
<
e
i
,
e
j
>
{<e_{i}, e_{j}>}
<ei,ej>的问题,论文中在
<
e
i
,
e
j
>
{<e_{i}, e_{j}>}
<ei,ej>上引如了BN层。
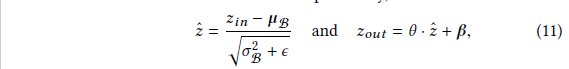
z
i
n
{z_{in}}
zin 、
z
o
u
t
{z_{out}}
zout分表代表BN层的输入和输出,θ and β are trainable scale and shift parameters
of BN; ϵ is a constant for numerical stability。
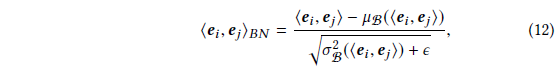
搜索阶段采用的下降法为:GRDA Optimizer (Generalized regularized dual averaging optimizer),该方法的目的是为了得到稀疏深度学习模型
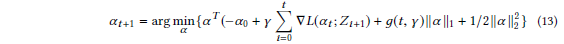















 1366
1366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









