







K-均值聚类(K-Means)简介可以参考: http://blog.csdn.net/fengbingchun/article/details/79276668
以下是K-Means的C++实现,code参考OpenCV 3.3中的cv::kmeans函数,均值点初始化的方法仅支持KMEANS_RANDOM_CENTERS。
以下是从数据集MNIST中提取的40幅图像,0,1,2,3四类各20张,如下图:

实现及测试代码如下:
kmeans.hpp:
#ifndef FBC_SRC_NN_KMEANS_HPP_
#define FBC_SRC_NN_KMEANS_HPP_
#include <vector>
namespace ANN {
typedef enum KmeansFlags {
// Select random initial centers in each attempt
KMEANS_RANDOM_CENTERS = 0,
// Use kmeans++ center initialization by Arthur and Vassilvitskii [Arthur2007]
//KMEANS_PP_CENTERS = 2,
// During the first (and possibly the only) attempt, use the
//user-supplied labels instead of computing them from the initial centers. For the second and
//further attempts, use the random or semi-random centers. Use one of KMEANS_\*_CENTERS flag
//to specify the exact method.
//KMEANS_USE_INITIAL_LABELS = 1
} KmeansFlags;
template<typename T>
int kmeans(const std::vector<std::vector<T>>& data, int K, std::vector<int>& best_labels, std::vector<std::vector<T>>& centers, double& compactness_measure,
int max_iter_count = 100, double epsilon = 0.001, int attempts = 3, int flags = KMEANS_RANDOM_CENTERS);
} // namespace ANN
#endif // FBC_SRC_NN_KMEANS_HPP_kmeans.cpp:
#include "kmeans.hpp"
#include <algorithm>
#include <limits>
#include<random>
#include "common.hpp"
namespace ANN {
namespace {
template<typename T>
void generate_random_center(const std::vector<std::vector<T>>& box, std::vector<T>& center)
{
std::random_device rd;
std::mt19937 generator(rd());
std::uniform_real_distribution<T> distribution((T)0, (T)0.0001);
int dims = box.size();
T margin = 1.f / dims;
for (int j = 0; j < dims; j++) {
center[j] = (distribution(generator) * (1. + margin * 2.) - margin) * (box[j][1] - box[j][0]) + box[j][0];
}
}
template<typename T>
inline T norm_L2_Sqr(const T* a, const T* b, int n)
{
double s = 0.f;
for (int i = 0; i < n; i++) {
double v = double(a[i] - b[i]);
s += v*v;
}
return s;
}
template<typename T>
void distance_computer(std::vector<double>& distances, std::vector<int>& labels, const std::vector<std::vector<T>>& data,
const std::vector<std::vector<T>>& centers, bool only_distance = false)
{
const int K = centers.size();
const int dims = centers[0].size();
for (int i = 0; i < distances.size(); ++i) {
const std::vector<T> sample = data[i];
if (only_distance) {
const std::vector<T> center = centers[labels[i]];
distances[i] = norm_L2_Sqr(sample.data(), center.data(), dims);
continue;
}
int k_best = 0;
double min_dist = std::numeric_limits<double>::max(); // DBL_MAX
for (int k = 0; k < K; ++k) {
const std::vector<T> center = centers[k];
const double dist = norm_L2_Sqr(sample.data(), center.data(), dims);
if (min_dist > dist) {
min_dist = dist;
k_best = k;
}
}
distances[i] = min_dist;
labels[i] = k_best;
}
}
} // namespace
template<typename T>
int kmeans(const std::vector<std::vector<T>>& data, int K, std::vector<int>& best_labels, std::vector<std::vector<T>>& centers, double& compactness_measure,
int max_iter_count, double epsilon, int attempts, int flags)
{
CHECK(flags == KMEANS_RANDOM_CENTERS);
int N = data.size();
CHECK(K > 0 && N >= K);
int dims = data[0].size();
attempts = std::max(attempts, 1);
best_labels.resize(N);
std::vector<int> labels(N);
centers.resize(K);
std::vector<std::vector<T>> centers_(K), old_centers(K);
std::vector<T> temp(dims, (T)0.);
for (int i = 0; i < K; ++i) {
centers[i].resize(dims);
centers_[i].resize(dims);
old_centers[i].resize(dims);
}
compactness_measure = std::numeric_limits<double>::max(); // DBL_MAX
double compactness = 0.;
epsilon = std::max(epsilon, (double)0.);
epsilon *= epsilon;
max_iter_count = std::min(std::max(max_iter_count, 2), 100);
if (K == 1) {
attempts = 1;
max_iter_count = 2;
}
std::vector<std::vector<T>> box(dims);
for (int i = 0; i < dims; ++i) {
box[i].resize(2);
}
std::vector<double> dists(N, 0.);
std::vector<int> counters(K);
const T* sample = data[0].data();
for (int i = 0; i < dims; ++i) {
box[i][0] = sample[i];
box[i][1] = sample[i];
}
for (int i = 1; i < N; ++i) {
sample = data[i].data();
for (int j = 0; j < dims; ++j) {
T v = sample[j];
box[j][0] = std::min(box[j][0], v);
box[j][1] = std::max(box[j][1], v);
}
}
for (int a = 0; a < attempts; ++a) {
double max_center_shift = std::numeric_limits<double>::max(); // DBL_MAX
for (int iter = 0;;) {
centers_.swap(old_centers);
if (iter == 0 && (a > 0 || true)) {
for (int k = 0; k < K; ++k) {
generate_random_center(box, centers_[k]);
}
} else {
// compute centers
for (auto& center : centers_) {
std::for_each(center.begin(), center.end(), [](T& v){v = (T)0; });
}
std::for_each(counters.begin(), counters.end(), [](int& v) {v = 0; });
for (int i = 0; i < N; ++i) {
sample = data[i].data();
int k = labels[i];
auto& center = centers_[k];
for (int j = 0; j < dims; ++j) {
center[j] += sample[j];
}
counters[k]++;
}
if (iter > 0) max_center_shift = 0;
for (int k = 0; k < K; ++k) {
if (counters[k] != 0) continue;
// if some cluster appeared to be empty then:
// 1. find the biggest cluster
// 2. find the farthest from the center point in the biggest cluster
// 3. exclude the farthest point from the biggest cluster and form a new 1-point cluster.
int max_k = 0;
for (int k1 = 1; k1 < K; ++k1) {
if (counters[max_k] < counters[k1])
max_k = k1;
}
double max_dist = 0;
int farthest_i = -1;
auto& new_center = centers_[k];
auto& old_center = centers_[max_k];
auto& _old_center = temp; // normalized
T scale = (T)1.f / counters[max_k];
for (int j = 0; j < dims; j++) {
_old_center[j] = old_center[j] * scale;
}
for (int i = 0; i < N; ++i) {
if (labels[i] != max_k)
continue;
sample = data[i].data();
double dist = norm_L2_Sqr(sample, _old_center.data(), dims);
if (max_dist <= dist) {
max_dist = dist;
farthest_i = i;
}
}
counters[max_k]--;
counters[k]++;
labels[farthest_i] = k;
sample = data[farthest_i].data();
for (int j = 0; j < dims; ++j) {
old_center[j] -= sample[j];
new_center[j] += sample[j];
}
}
for (int k = 0; k < K; ++k) {
auto& center = centers_[k];
CHECK(counters[k] != 0);
T scale = (T)1.f / counters[k];
for (int j = 0; j < dims; ++j) {
center[j] *= scale;
}
if (iter > 0) {
double dist = 0;
const auto old_center = old_centers[k];
for (int j = 0; j < dims; j++) {
T t = center[j] - old_center[j];
dist += t*t;
}
max_center_shift = std::max(max_center_shift, dist);
}
}
}
bool isLastIter = (++iter == std::max(max_iter_count, 2) || max_center_shift <= epsilon);
// assign labels
std::for_each(dists.begin(), dists.end(), [](double& v){v = 0; });
distance_computer(dists, labels, data, centers_, isLastIter);
std::for_each(dists.cbegin(), dists.cend(), [&compactness](double v) { compactness += v; });
if (isLastIter) break;
}
if (compactness < compactness_measure) {
compactness_measure = compactness;
for (int i = 0; i < K; ++i) {
memcpy(centers[i].data(), centers_[i].data(), sizeof(T)* dims);
}
memcpy(best_labels.data(), labels.data(), sizeof(int)* N);
}
}
return 0;
}
template int kmeans<float>(const std::vector<std::vector<float>>&, int K, std::vector<int>&, std::vector<std::vector<float>>&, double&,
int max_iter_count, double epsilon, int attempts, int flags);
template int kmeans<double>(const std::vector<std::vector<double>>&, int K, std::vector<int>&, std::vector<std::vector<double>>&, double&,
int max_iter_count, double epsilon, int attempts, int flags);
} // namespace ANNmain.cpp:
#include "funset.hpp"
#include <iostream>
#include <opencv2/opencv.hpp>
#include "perceptron.hpp"
#include "BP.hpp""
#include "CNN.hpp"
#include "linear_regression.hpp"
#include "naive_bayes_classifier.hpp"
#include "logistic_regression.hpp"
#include "common.hpp"
#include "knn.hpp"
#include "decision_tree.hpp"
#include "pca.hpp"
#include "logistic_regression2.hpp"
#include "single_hidden_layer.hpp"
#include "kmeans.hpp"
// ================================= K-Means ===============================
int test_kmeans()
{
const std::string image_path{ "E:/GitCode/NN_Test/data/images/digit/handwriting_0_and_1/" };
cv::Mat tmp = cv::imread(image_path + "0_1.jpg", 0);
CHECK(tmp.data != nullptr && tmp.channels() == 1);
const int samples_number{ 80 }, every_class_number{ 20 }, categories_number{ samples_number / every_class_number };
cv::Mat samples_data(samples_number, tmp.rows * tmp.cols, CV_32FC1);
cv::Mat labels(samples_number, 1, CV_32FC1);
float* p1 = reinterpret_cast<float*>(labels.data);
for (int i = 1; i <= every_class_number; ++i) {
static const std::vector<std::string> digit{ "0_", "1_", "2_", "3_" };
CHECK(digit.size() == categories_number);
static const std::string suffix{ ".jpg" };
for (int j = 0; j < categories_number; ++j) {
std::string image_name = image_path + digit[j] + std::to_string(i) + suffix;
cv::Mat image = cv::imread(image_name, 0);
CHECK(!image.empty() && image.channels() == 1);
image.convertTo(image, CV_32FC1);
image = image.reshape(0, 1);
tmp = samples_data.rowRange((i - 1) * categories_number + j, (i - 1) * categories_number + j + 1);
image.copyTo(tmp);
p1[(i - 1) * categories_number + j] = j;
}
}
std::vector<std::vector<float>> data(samples_data.rows);
for (int i = 0; i < samples_data.rows; ++i) {
data[i].resize(samples_data.cols);
const float* p = (const float*)samples_data.ptr(i);
memcpy(data[i].data(), p, sizeof(float)* samples_data.cols);
}
const int K{ 4 }, attemps{ 100 }, max_iter_count{ 100 };
const double epsilon{ 0.001 };
const int flags = ANN::KMEANS_RANDOM_CENTERS;
std::vector<int> best_labels;
double compactness_measure{ 0. };
std::vector<std::vector<float>> centers;
ANN::kmeans<float>(data, K, best_labels, centers, compactness_measure, max_iter_count, epsilon, attemps, flags);
fprintf(stdout, "K = %d, attemps = %d, iter count = %d, compactness measure = %f\n",
K, attemps, max_iter_count, compactness_measure);
CHECK(best_labels.size() == samples_number);
const auto* p2 = best_labels.data();
for (int i = 1; i <= every_class_number; ++i) {
for (int j = 0; j < categories_number; ++j) {
fprintf(stdout, " %d ", *p2++);
}
fprintf(stdout, "\n");
}
return 0;
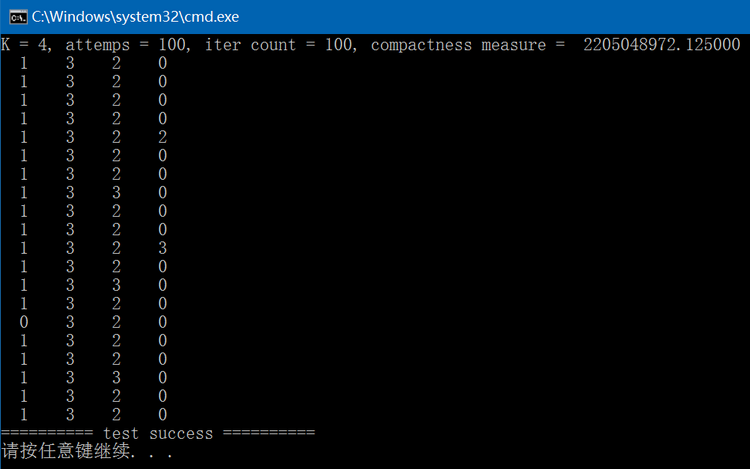
}执行结果如下,下图中每一列表示期望是同一个label。















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









