






作者 | Ashis Kumar Panda
编译 | VK
来源 | Towards Data Science

在开始这篇博文之前,我强烈建议访问我先前的关于Transformers 概述的博文。为了更好地利用这个博客,请按以下顺序查看我以前的博客文章。
Transformers — Yo_just need Attention(https://machinelearningmarvel.in/transformers-you-just-need-attention/)
Intuitive Maths and Code behind Self-Attention Mechanism of Transformers(https://machinelearningmarvel.in/intuitive-maths-and-code-behind-self-attention-mechanism-of-transformers-for-dummies/)
Concepts about Positional Encoding Yo_Might Not Know About(https://machinelearningmarvel.in/concepts-about-positional-encoding-you-might-not-know-about/)
这篇博文将深入了解注意机制的细节,并使用python从头开始创建一个注意机制。代码和直观的数学解释将齐头并进。
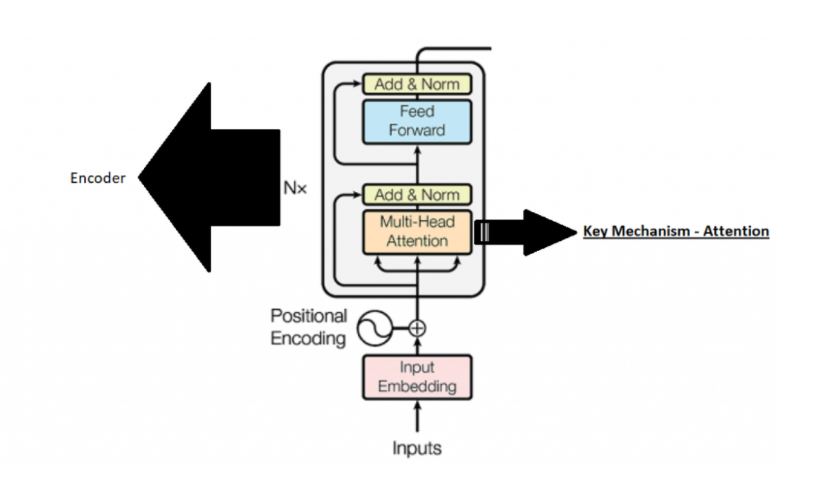
我们要学什么?
注意机制概念
自注意机制的步骤(直觉数学理论和代码)
输入预处理
查询、键和值矩阵
注意分数的概念
多头自注意机制
所以不要再耽搁了,我们开始吧。
注意机制概念
正如前一篇文章所讨论的,当一个句子通过注意机制时会发生什么。例如,假设我们有一个句子“He took the hat and examined it carefully”,注意机制通过记住每个单词与句子中其他单词的关系来创建每个单词的表示(嵌入)。
在上面的句子中,注意机制对句子的理解如此之深,以至于它可以将“it”与“hat”联系起来,而不是与“He”联系起来。
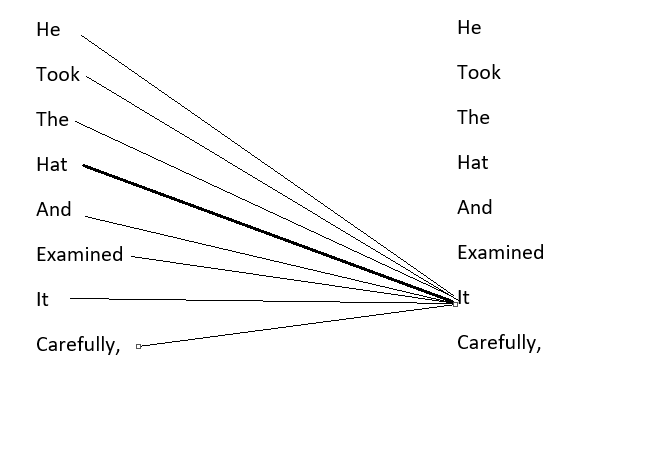
自注意机制的步骤
1.输入正确的格式
我们现在都知道文本输入不适合由Transformer/计算机解释。因此,我们用数字向量来表示文本中的每个单词。让我们为一个句子创建嵌入,例如:-“This is book”,假设嵌入维数为5,那么每个单词都有一个长度为5的向量,如下所示。
Transformer输入
print(f”Shape is :- {np.random.randn(3,5).shape}”)
X=np.random.randn(3,5)
X
Output:-

根据上面的输入矩阵,我们将创建两个新矩阵,即键矩阵、查询矩阵和值矩阵。矩阵在注意机制中起着至关重要的作用。让我们看看怎么做?
2.获取查询、键值矩阵
首先,我们需要查询、键和值权重矩阵。目前,我们已经随机初始化了它,但实际上,就像神经网络中的任何其他权重一样,这些都是在训练过程中学习的参数。最后使用最优权重。假设这些权重是代码中所示的最佳权重。下面总结了我们在代码部分将要做的工作

query矩阵的优化权值
weight_of_query=np.random.randn(5,3)
weight_of_query
Output:-

key矩阵的优化权重
weight_of_key=np.random.randn(5,3)
weight_of_key
Output:-

value矩阵的优化权重
weight_of_values=np.random.randn(5,3)
weight_of_values
Output:-

这些权重将乘以我们的输入矩阵(X),从而得到最终的键、查询和值矩阵
key矩阵的计算
Key=np.matmul(X,weight_of_key)
Key

query矩阵的计算
Query=np.matmul(X,weight_of_query)
Query

value矩阵的计算
Values=np.matmul(X,weight_of_values)
Values

查询、关键字和值矩阵中的第一行表示“This”词的查询、关键字和值向量,以此类推。到目前为止,查询、键和值矩阵可能意义不大。让我们看看自我注意机制是如何通过使用查询、键和值向量来发现每个单词与句子中其他单词的关系,从而创建每个单词的表示(嵌入)的。
3.注意得分
注意公式:
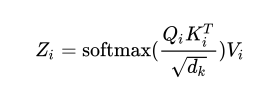
dimension=5
Scores=np.matmul(Query,Key.T)/np.sqrt(dimension)
Scores

在Q.K(转置)中发生的是查询和键矩阵之间的点积,点积定义了相似性,如下图所示。
注意:- 以下图片中的数字都是为了解释而虚构的
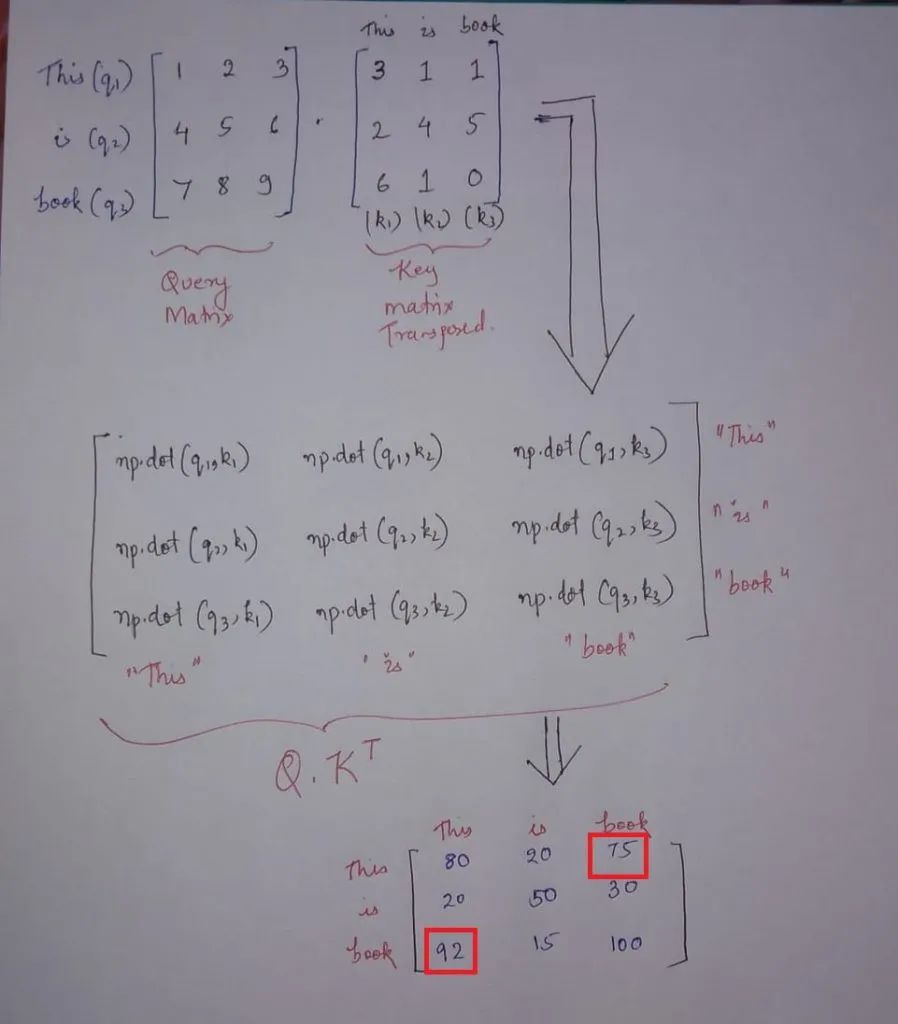
所以在查询向量q1(This)和所有关键向量k1(This)、k2(is)、k3(book)之间有一个点积。
这个计算告诉我们查询向量q1(This)如何与键矩阵k1(This)、k2(is)、k3(book)中的每个向量相关/相似。同样,如果我们关注最终的输出矩阵,我们可以看到每个单词比句子中的任何其他单词都更相关,如对角线矩阵所示。这是因为点积值更高。
其次,“This”一词与上图中以红色突出显示的“book”更相关。如代码的最后一部分所示,我们将Q.K(转置)除以sqrt(维数)。这是一种标准化步骤,在这里进行,以使梯度稳定。
下面代码中的Softmax有助于将其置于0和1的范围内,并分配概率值。
from scipy.special import softmax
Softmax_attention_scores=np.array([softmax(x) for x in Scores])
Softmax_attention_scores
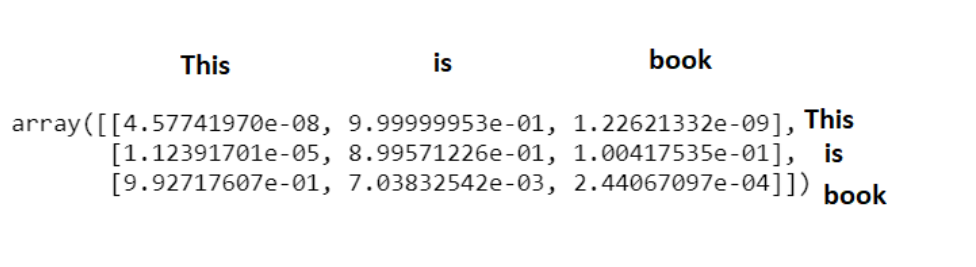
上述矩阵是中间softmax标度注意得分矩阵,其中每行对应于顺序中每个单词的中间注意得分/概率得分。它显示了每个词是如何与其他词的概率。为了得到最终的注意向量,我们将上述分数乘以值矩阵并求和。总结了与“This”相对应的三个注意向量。
在下面的代码片段中,softmax_attention_scores[0][0]是该特定单词的权重,Values[0]是对应于单词“This”的值向量,依此类推。
Softmax_attention_scores[0][0]*Values[0]+\
Softmax_attention_scores[0][1]*Values[1]+\
Softmax_attention_scores[0][2]*Values[2]

类似地,我们可以计算像is和book这样的词的注意力。这就是自注意的机制。接下来,我们将探讨多头注意机制,它的基本原理来自于自我注意机制。
多头自注意机制
简单地说,多头注意机制就是多个自我注意机制串联在一起。如果我们将每个自我注意流/过程表示为一个头部,那么我们将把所有的自注意机制连接在一起,得到一个多头注意机制。
当我们在一篇即将发表的博文中进行实际操作时,我们将看到每个编码器的输出尺寸为512,总共有8个头。所以所发生的是,每个自注意模块都会输出到一个(no_of_words_in_sentence,64个)维矩阵。
当所有这些维度串联起来时,我们将看到最后的矩阵将是(no_of_words_in_sentence,(64*8)=512)维。最后一步是将连接的头部乘以一个权重矩阵(假设在这个过程中权重矩阵已经训练过),这将是我们多头部注意力的输出。
在我们的下一篇博文中,我们将讨论Hugging Face Transformers 的实现。如果你觉得这有帮助,请随时查看其他博客文章
Transformers — Yo_just need Attention(https://machinelearningmarvel.in/transformers-you-just-need-attention/)
Intuitive Maths and Code behind Self-Attention Mechanism of Transformers(https://machinelearningmarvel.in/intuitive-maths-and-code-behind-self-attention-mechanism-of-transformers-for-dummies/)
Concepts about Positional Encoding Yo_Might Not Know About(https://machinelearningmarvel.in/concepts-about-positional-encoding-you-might-not-know-about/)
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑黄海广老师《机器学习课程》课件合集
本站qq群851320808,加入微信群请扫码:















 484
484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









