







DETR解读
文章目录
1 贡献点
- DETR takes object detection as a direct set prediction problem, which is actually a NMS-free method, leveraging the one-to-one label assignment.
- DETR utilizes the emerging transformer for decoding image representations to a fixed-size set of predictions.
- DETR uses a set-based global loss that forces unique predictions.
其实早在2016年,论文(End-to-End People Detection in Crowded Scenes, CVPR 2016)就提出了类似的框架,DETR的不同之处主要在于:
- 在解码阶段使用vision transformer模型而非LSTM;
- 利用vision transformer的特性,同时输出大小为 N N N的预测集合,而不像传统RNN逐步输出单个预测。
2 模型结构
DETR模型的前向计算流程如下:
- 使用骨干网络获取图像特征,可以是CNN模型 (e.g. ResNet),也可以是Vision Transformer模型 (e.g. SwinT);
- 使用transformer encoder (self-attention only)和transformer decoder (both self-attention & cross-attention)进一步增强特征;
- 使用MLP(or FFN)输出 N N N个预测框的位置和大小,使用带softmax的线性层(即逻辑回归)为每个框的目标分类。
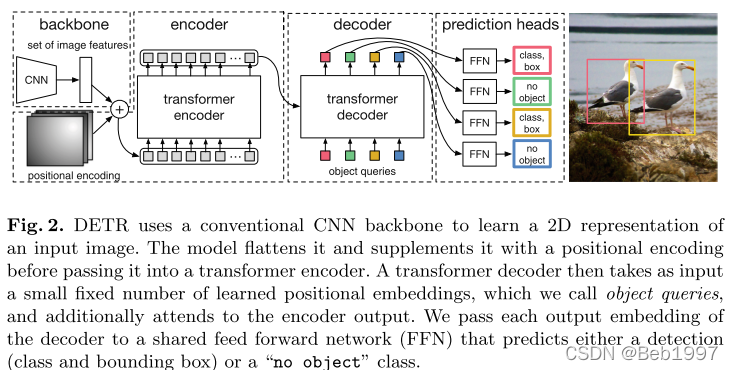
2.1 Backbone
假设
x
i
∈
R
3
×
H
i
×
W
i
x_i\in\mathbb{R}^{3\times H_i\times W_i}
xi∈R3×Hi×Wi表示某张RGB图像,由于每张图像的尺寸有差异,故而将所有图片转换为
x
i
∈
R
3
×
H
0
×
W
0
x_i\in\mathbb{R}^{3\times H_0\times W_0}
xi∈R3×H0×W0以组成小批量。其中
H
0
=
m
a
x
{
H
i
}
H_0=max\{H_i\}
H0=max{Hi},
W
0
=
m
a
x
{
W
i
}
W_0=max\{W_i\}
W0=max{Wi},通过在图像的右边和底边填充0实现。开源代码中的NestedTensor就是为了这个目的。
class NestedTensor(object):
def __init__(self, tensor, mask):
self.tensor = tensor # img tensor itself
self.mask = mask # binary mask containing 1 on padded pixels and 0 on others
def to(self, device):
cast_tensor = self.tensor.to(device)
cast_mask = self.mask.to(device) if self.mask is not None else None
return NestedTensor(cast_tensor, cast_mask)
def decompose(self):
return self.tensor, self.mask
def __repr__(self):
return str(self.tensor)
为了表示方便,省略批量维度,设输入图像 x i m g ∈ R 3 × H 0 × W 0 x_{img}\in\mathbb{R}^{3\times H_0\times W_0} ximg∈R3×H0×W0,通过骨干网络后得到特征图 f ∈ R C × H × W f\in\mathbb{R}^{C\times H\times W} f∈RC×H×W,以ResNet101为例, C = 2048 C=2048 C=2048, H = H 0 32 H=\frac{H_0}{32} H=32H0, W = W 0 32 W=\frac{W_0}{32} W=32W0。图像对应的 m a s k mask mask直接通过双线性插值匹配 f f f的大小。为了降低transformer部分的运算量,使用线性映射(如 1 × 1 c o n v 1\times 1~conv 1×1 conv)将特征图 f f f降维,得到 z 0 ∈ R d × H × W z_0\in\mathbb{R}^{d\times H\times W} z0∈Rd×H×W作为后续输入,在DETR中, C : 2048 → d : 256 C:2048\rightarrow d:256 C:2048→d:256.
2.2 Transformer
2.2.1 Position Embedding
Vision transformer中position embedding(PE)需要同时考虑图像的 h e i g h t height height和 w i d t h width width两个维度,当前主要采用两种方式:
- 可学习PE,如ViT (An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021);
- 同原始transformer一致,使用固定不变的三角函数PE,如DETR。
对于特征图 z 0 ∈ R d × H × W z_0\in\mathbb{R}^{d\times H\times W} z0∈Rd×H×W,相应的位置编码 P E ∈ R d × H × W PE\in\mathbb{R}^{d\times H\times W} PE∈Rd×H×W。对于位置 ( h , w ) (h,w) (h,w),前 d / 2 d/2 d/2维表示 h e i g h t height height方向的位置编码,后 d / 2 d/2 d/2维表示 w i d t h width width方向的位置编码,当然反之亦可,DETR中 d / 2 = 128 d/2=128 d/2=128。令 i i i表示位置编码的维度,则:
P E h , 2 i = s i n ( h 1000 0 2 i / 128 ) PE_{h,2i}=sin(\frac{h}{10000^{2i/128}}) PEh,2i=sin(100002i/128h), P E h , 2 i + 1 = c o s ( h 1000 0 2 i / 128 ) PE_{h,2i+1}=cos(\frac{h}{10000^{2i/128}}) PEh,2i+1=cos(100002i/128h), i = 0 , 1 , 2 , . . . , 63 i=0,1,2,...,63 i=0,1,2,...,63
P E w , 2 i = s i n ( w 1000 0 2 i / 128 ) PE_{w,2i}=sin(\frac{w}{10000^{2i/128}}) PEw,2i=sin(100002i/128w), P E w , 2 i + 1 = c o s ( w 1000 0 2 i / 128 ) PE_{w,2i+1}=cos(\frac{w}{10000^{2i/128}}) PEw,2i+1=cos(100002i/128w), i = 0 , 1 , 2 , . . . , 63 i=0,1,2,...,63 i=0,1,2,...,63
为什么底数取 10000 10000 10000呢,玄学!
import math
import torch
import torch.nn as nn
class LearnablePE(nn.Module):
def __init__(self, pe_dim):
super(LearnablePE, self).__init__()
self.row_embed = nn.Embedding(50, pe_dim) # 50 is larger than img height
self.col_embed = nn.Embedding(50, pe_dim)
self._reset_params()
def _reset_params(self):
"""
nn.Embedding.weight is by default initialized from N(0, 1),
here we use initialization from U(0, 1)
"""
nn.init.uniform_(self.row_embed.weight)
nn.init.uniform_(self.col_embed.weight)
def forward(self, x: NestedTensor):
x = x.tensor
h, w = x.shape[-2:]
i = torch.arange(w, device=x.device)
j = torch.arange(h, device=x.device)
x_emb = self.col_embed(i) # look up for learnable embeddings by index
y_emb = self.row_embed(j)
pos = torch.cat([x_emb.unsqueeze(0).repeat(h, 1, 1),
y_emb.unsqueeze(1).repeat(1, w, 1)],
dim=-1).permute(2, 0, 1).unsqueeze(0).repeat(x.size(0), 1, 1, 1)
return pos
class FixedPE(nn.Module):
def __init__(self, pe_dim, temperature=10000, normalize=True, scale=None):
super(FixedPE, self).__init__()
self.pe_dim = pe_dim
self.t = temperature
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
self.norm = normalize
self.scale = scale if scale is not None else 2 * math.pi
def forward(self, x: NestedTensor):
assert x.mask is not None
not_msk = ~x.mask
x = x.tensor
y_embed = not_msk.cumsum(1, dtype=torch.float32)
x_embed = not_msk.cumsum(2, dtype=torch.float32)
if self.norm: # normalize to [0, 2*PI]
y_embed = y_embed / (y_embed[:, -1:, :] + 1e-6) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + 1e-6) * self.scale
dim = torch.arange(self.pe_dim, dtype=torch.float32, device=x.device)
dim = self.t ** (2 * (dim // 2) / self.pe_dim)
pos_x = x_embed[:, :, :, None] / dim
pos_y = y_embed[:, :, :, None] / dim
pos_x = torch.stack([pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()], dim=4).flatten(3)
pos_y = torch.stack([pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()], dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos
由于骨干网络的输出即transformer部分的输入,所以在DETR官方开源代码中,将PE的获取放在了backbone部分,并定义Joiner类,得到骨干网络不同stage的输出,和相对应的PE。
2.2.2 Encoder & Decoder
DETR所使用的transformer结构有如下特点:
- 原始transformer仅在输入使用位置编码(position embedding, PE),DETR在每一个注意力层之前均使用;
- DETR中,PE仅在
Q
Q
Q和
K
K
K上使用。
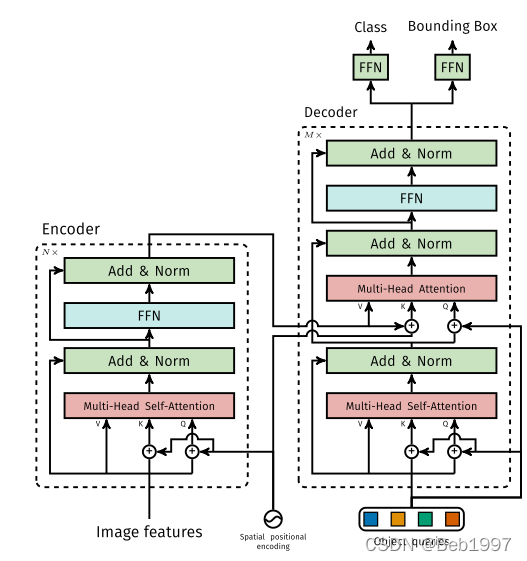
骨干网络的输出 z 0 ∈ R d × H × W z_0\in\mathbb{R}^{d\times H\times W} z0∈Rd×H×W和对应的位置编码 P E ∈ R d × H × W PE\in\mathbb{R}^{d\times H\times W} PE∈Rd×H×W均被reshape到 R ( H W ) × d \mathbb{R}^{(HW)\times d} R(HW)×d作为encoder部分的输入,记encoder的输出为 m e m o r y ∈ R ( H W ) × d memory \in \mathbb{R}^{(HW) \times d} memory∈R(HW)×d。
decoder的输入包含:(1) encoder的输出 m e m o r y ∈ R ( H W ) × d memory \in \mathbb{R}^{(HW) \times d} memory∈R(HW)×d,(2) 可学习的object query,记为 q u e r y ∈ R N × d query \in \mathbb{R}^{N \times d} query∈RN×d,(3) t a r g e t ∈ R N × d target\in \mathbb{R}^{N \times d} target∈RN×d和 q u e r y query query形状相同,初始化为0。decoder的输出为 o u t ∈ R N × d out \in \mathbb{R}^{N \times d} out∈RN×d,DETR中取 N = 100 , d = 256 N=100,~d=256 N=100, d=256.
- 在self-attention部分, Q Q Q, K K K和 V V V均由 t a r g e t target target得到, Q Q Q和 K K K使用位置编码,即 Q , K = t a r g e t + q u e r y Q,K=target+query Q,K=target+query, V V V无位置编码,即 V = t a r g e t V=target V=target;
- 在cross-attention部分, Q Q Q由self-attention的输出结合位置编码 q u e r y query query得到, K K K由encoder部分的输出结合位置编码 P E PE PE得到,即 K = m e m o r y + P E K=memory+PE K=memory+PE, V V V不使用位置编码,即 V = m e m o r y V=memory V=memory。
2.3 Head
假设
y
i
=
(
c
i
,
b
i
)
y_i=(c_i,b_i)
yi=(ci,bi)为第
i
i
i个GT标注,其中
c
i
∈
{
∅
,
0
,
1
,
2
,
.
.
.
}
c_i\in\{\varnothing,0,1,2,...\}
ci∈{∅,0,1,2,...}为目标的类别标注,
b
i
=
(
b
i
,
x
,
b
i
,
y
,
b
i
,
h
,
b
i
,
w
)
b_i=(b_{i,x},b_{i,y},b_{i,h},b_{i,w})
bi=(bi,x,bi,y,bi,h,bi,w)分别表示检测框的中心坐标
(
b
i
,
x
,
b
i
,
y
)
(b_{i,x},b_{i,y})
(bi,x,bi,y)、相对高度和宽度。本节标题Head即为原文中Prediction Feed-Forward Networks (FFNs),包含两部分:
- 用于为目标分类的逻辑回归层(线性映射+
softmax),定义为class_head=nn.Linear(d, num_classes+1),"+1"是因为引入了 ∅ \varnothing ∅类别标注; - 用于检测框回归的MLP,定义为
box_head=MLP(input_dim=d, hidden_dim=d, output_dim=4, num_layers=3)。
3 损失函数
假设 y = { y i ∣ y i = ( c i , b i ) } i = 1 N y=\{y_i|y_i=(c_i,b_i)\}_{i=1}^N y={yi∣yi=(ci,bi)}i=1N表示 N N N个GT标注, y ^ = { y ^ i ∣ y ^ i = ( c ^ i , b ^ i ) } i = 1 N \hat y=\{\hat y_i|\hat y_i=(\hat c_i,\hat b_i)\}_{i=1}^N y^={y^i∣y^i=(c^i,b^i)}i=1N表示模型的 N N N个预测。由于DETR采用了one-to-one label assignment的方式,故而需要将每一个预测的box和标注box匹配起来,文章采用匈牙利算法(Hungarian algorithm)来实现,即找到代价最小的一种匹配(match)方式。
- 论文中, L m a t c h \mathcal L_{match} Lmatch表示代价函数,包含分类 L c l s \mathcal L_{cls} Lcls和预测框 L b o x \mathcal L_{box} Lbox两个部分;
- L b o x \mathcal L_{box} Lbox又包含了IoU损失 L i o u \mathcal L_{iou} Liou和 ℓ 1 \ell_1 ℓ1损失两部分;
损失函数每部分的具体细节可参考论文,比较直观和简单。匈牙利算法可以使用scipy库中的linear_sum_assignment实现。
4 相关工作
基于DETR,已有后续相关工作,如:
- Deformable DETR (Deformable DETR: Deformable Transformers for End-to-End Object Detection, ICLR 2021)结合可变形卷积的思想,在计算注意力时将 K K K稀疏采样,降低了计算的复杂度,在维持模型整体计算量相近的同时引入FPN特征,较好地解决了DETR小目标检测性能差的问题;
- Sparse DETR (Sparse DETR: Efficient End-to-End Object Detection with Learnable Sparsity)进一步将 Q Q Q稀疏化,降低了模型整体的计算复杂度;
- MaskFormer (Per-Pixel Classification is Not All You Need for Semantic Segmentation, NeurIPS 2021)基于DETR统一了语义分割、实例分割和全景分割,并取得了不错的效果。















 1910
1910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









