






2022:ArXiv 2023:CVPR
摘要
本文提出Mask DINO,一个统一的目标检测和分割框架。Mask DINO通过添加掩码预测分支来扩展DINO(具有改进的去噪锚框的DETR),该分支支持所有图像分割任务(实例、全景和语义)。它利用迪诺的查询嵌入对高分辨率像素嵌入图进行点积,以预测一组二进制掩码。DINO中的一些关键组件通过共享架构和训练过程进行了扩展以进行分割。Mask DINO简单、高效、可扩展,可以从联合的大规模检测和分割数据集中受益。实验表明,Mask DINO明显优于所有现有的专用分割方法,无论是在ResNet-50骨干网上,还是在具有SwinL骨干网的预训练模型上。值得注意的是,Mask DINO在10亿参数以下的模型中建立了迄今为止在实例分割(COCO上的54.5 AP)、全景分割(COCO上的59.4 PQ)和语义分割(ADE20K上的60.8 mIoU)方面的最佳结果。
代码地址:https://github.com/IDEA-Research/MaskDINO
一、Introduce
目标检测和图像分割是计算机视觉中的基本任务。这两种任务都涉及在图像中定位感兴趣的物体,但具有不同的聚焦水平。
- 目标检测:是定位感兴趣的目标并预测其边界框和类别标签。
- 图像分割:侧重于不同语义的像素级分组。此外,图像分割还包括各种任务,包括实例分割、全景分割和针对不同语义的语义分割,例如实例或类别隶属度、前景或背景类别。
基于transformer模型存在的问题:性能最好的检测和分割模型仍然不统一,这阻碍了检测和分割任务之间的任务和数据合作。
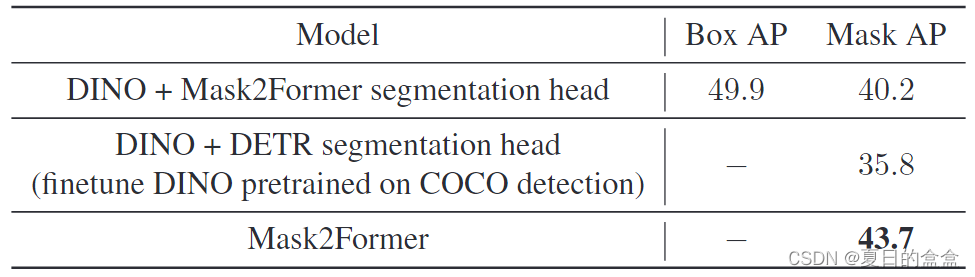
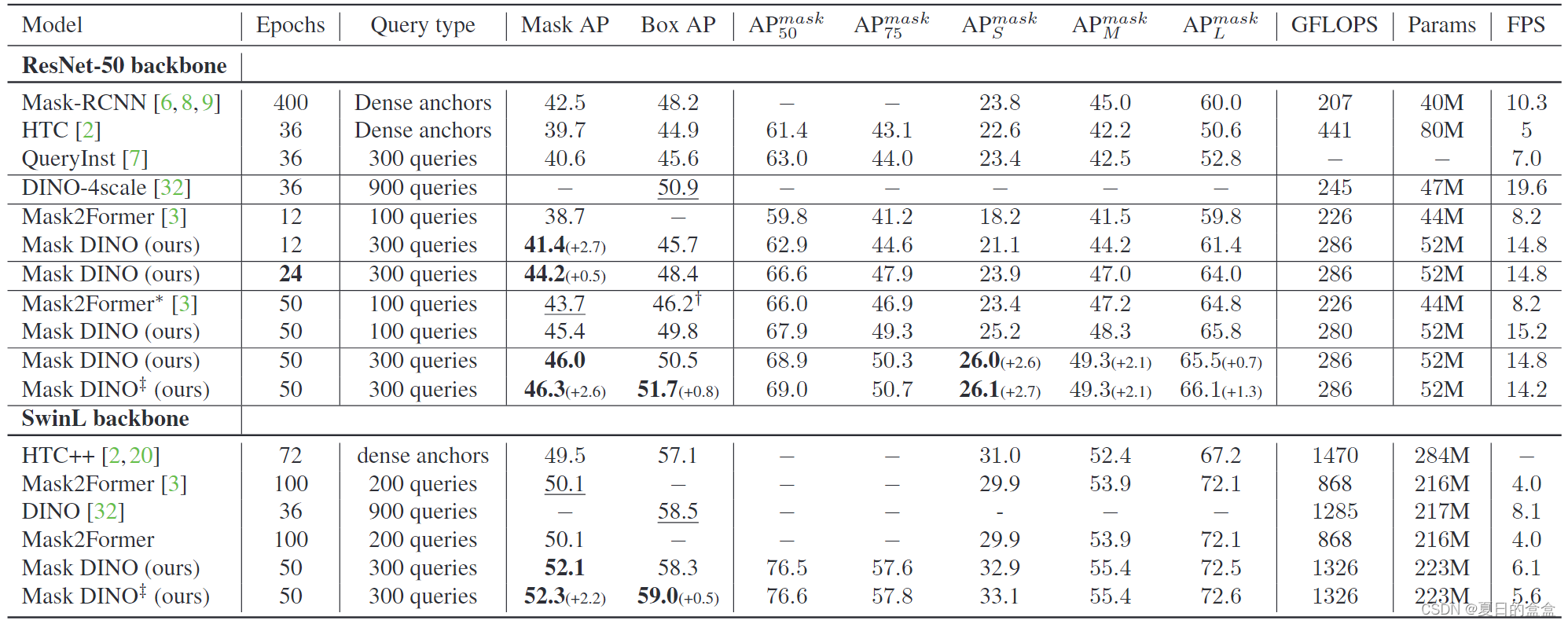
在基于 CNN 的模型中,Mask-R-CNN和 HTC仍然被广泛认为是实现检测和分割之间相互合作的统一模型,以实现比专业模型更好的性能。尽管我们相信检测和分割可以在基于 Transformer 的模型的统一架构中相互帮助,但简单地使用 DINO 进行分割并使用 Mask2Former 进行检测的结果表明它们不能很好地完成其他任务,如表 1 和表 2 所示。
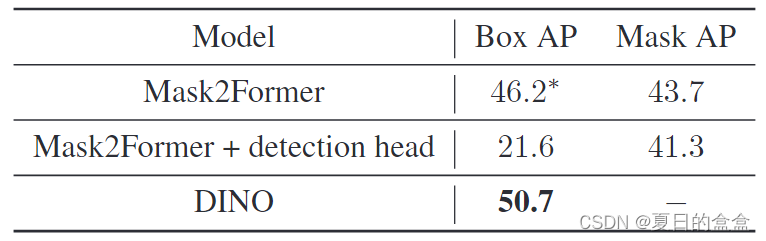
此外,琐碎的多任务训练甚至会损害原始任务的性能。它自然会导致两个问题:1)为什么不能检测和分割任务在基于 Transformer 的模型中相互帮助。2) 是否有可能开发一种统一的架构来取代专门的架构?
为解决这些问题,本文提出Mask DINO:用一个掩码预测分支对DINO进行扩展,并与DINO的盒子预测分支并行。
- 受其他用于图像分割的统一模型[3]、[4]、[28]的启发,重用DINO的内容查询嵌入,在从骨干和Transformer编码器特征获得的高分辨率像素嵌入图(输入图像分辨率)上对所有分割任务执行掩码分类。
- mask分支通过简单地用像素嵌入图生成每个内容查询嵌入来预测二进制掩码。
由于DINO是区域级回归的检测模型,因此它不是为像素级对齐而设计的。为了更好地对齐检测和分割之间的特征,本文还提出了三个关键组件来提高分割性能:
- 提出一种统一的、增强的查询选择方法。它利用编码器密集先验,从排名靠前的标记中预测掩码,将掩码查询初始化为锚点。
- 像素级分割在早期阶段更容易学习,建议使用初始掩码来增强盒子,实现任务协作。提出一种统一的掩模去噪训练,以加速分割训练。
- 然后,使用混合二部图匹配算法实现真实值与掩码的精确匹配。
主要贡献:
- 开发了一个基于transformer的统一框架,用于目标检测和分割。由于该框架从DINO扩展而来,通过添加掩码预测分支,它自然地继承了DINO中的大多数算法改进,包括锚框引导的交叉注意力、查询选择、去噪训练,甚至在大规模检测数据集上预训练的更好的表示。
- 证明了检测和分割可以通过共享的架构设计和训练方法相互帮助。特别是,检测可以显著帮助分割任务,即使是分割背景“东西”类别。在相同的设置下,使用ResNet-50骨干网络,与DINO (COCO检测时0.8 AP)和Mask2Former (COCO实例、COCO全景和ADE20K语义分割时2.6 AP、1.1 PQ和1.5 mIoU)相比,Mask DINO的性能优于所有现有模型。
- 通过一个统一的框架,分割可以从大规模检测数据集的检测预训练中受益。在具有SwinL骨干的Objects365数据集上进行检测预训练后,Mask DINO显著提高了所有分割任务,并在十亿参数下的模型之间的实例(COCO上的54.5 AP)、全景(COCO上的59.4 PQ)和语义(ADE20K上的60.8 mIoU)分割上取得了最佳结果。
二、Related Work
2.1目标检测
主流的检测算法一直被基于卷积神经网络的框架所主导,直到最近基于transformer的检测器取得了很大的进展:
- 《End-to-End Object Detection with Transformers》[1]:DETR是第一个端到端的、基于查询的Transformer目标检测器,采用二分图匹配的集合预测目标。
- 《DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR》[18]:DAB-DETR通过将查询表述为4D锚框并逐层细化预测来改进DETR。
- 《DN-DETR: Accelerate DETR Training by Introducing Query DeNoising》[15]:DN-DETR引入了去噪训练方法来加速收敛。
- 《DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection》[32]:在DAB-DETR和DN-DETR的基础上,DINO在去噪和锚点细化方面提出了一些新的改进,在COCO检测上取得了新的SOTA结果。
尽管取得了令人鼓舞的进展,但DETR-like检测模型在分割方面并不具有竞争力。Vanilla DETR在其架构中包含一个分割头。然而,它的分割性能不如专门的分割模型,仅显示了DETR-like检测模型同时处理检测和分割的可行性。
2.2分割
分割分为:
- 实例分割是为每个对象实例预测掩码及其对应的类别。
- 语义分割需要将包括背景在内的每个像素划分为不同的语义类别。
- 全景分割将实例和语义分割任务统一起来,并为每个对象实例或背景分割预测一个掩码。
在过去的几年里,研究人员为这三项任务开发了专门的架构:
- MASK-RCNN和HTC只能处理实例分割,因为它们根据每个实例的框预测来预测其掩码。
- FCN和U-Net只能进行语义分割,因为它们是基于像素分类来预测一个分割图。
- 全景分割模型《Panoptic Feature Pyramid Networks》和《UPSNet: A Unified Panoptic Segmentation Network》虽然统一了上述两个任务,但它们通常不如专门实例和语义分割模型。
直到最近,还开发了一些图像分割模型 [3, 4]将这三个任务与通用架构统一起来:
- 《Per-Pixel Classification is Not All You Need for Semantic Segmentation》[4]:MaskFormer
- 《Masked-attention Mask Transformer for Universal Image Segmentation》[3]:Mask2Former
- Mask2Former通过在Transformer中引入掩码注意来改进MaskFormer。
- Mask2Former具有与DETR类似的架构,用可学习的查询探测图像特征,但在使用不同的分割分支和一些专门的掩码预测设计方面有所不同。
- 然而,虽然Mask2Former在统一所有分割任务方面取得了巨大的成功,但它没有触及目标检测,我们的实证研究表明,其专门的架构设计不适合预测框。
2.3统一的方法
由于目标检测和分割都涉及目标定位,因此它们自然共享共同的模型架构和视觉表示。一个统一的框架不仅有助于简化算法开发工作,而且允许同时使用检测和分割数据来改进表示学习。
- Mask RCNN扩展了Faster RCNN,并从RPN提出的感兴趣区域(ROI)中池化图像特征。HTC进一步提出了一种预测盒子和口罩的交错方式。然而,这两个模型只能进行实例分割。
- DETR以端到端的方式预测盒子和掩码。然而,其分割性能在很大程度上落后于其他模型。
由表2可知,将DETR的分割头添加到DINO中,实例分割结果较差。如何实现分割和检测之间的相互辅助一直是一个需要解决的重要问题。
三、Mask Dino
Mask DINO是DINO的扩展。在内容查询嵌入的基础上,DINO有两个用于框预测和标签预测的分支。boxes是动态更新的,用于指导每个Transformer解码器中的可变形注意力。Mask DINO为掩码预测添加了另一个分支,并最低限度地扩展了检测中的几个关键组件,以适应分割任务。
3.1Dino
DINO是一个典型的类似DETR的模型,由骨干、Transformer编码器和Transformer解码器组成。框架如图1所示(蓝色阴影部分没有红线)。
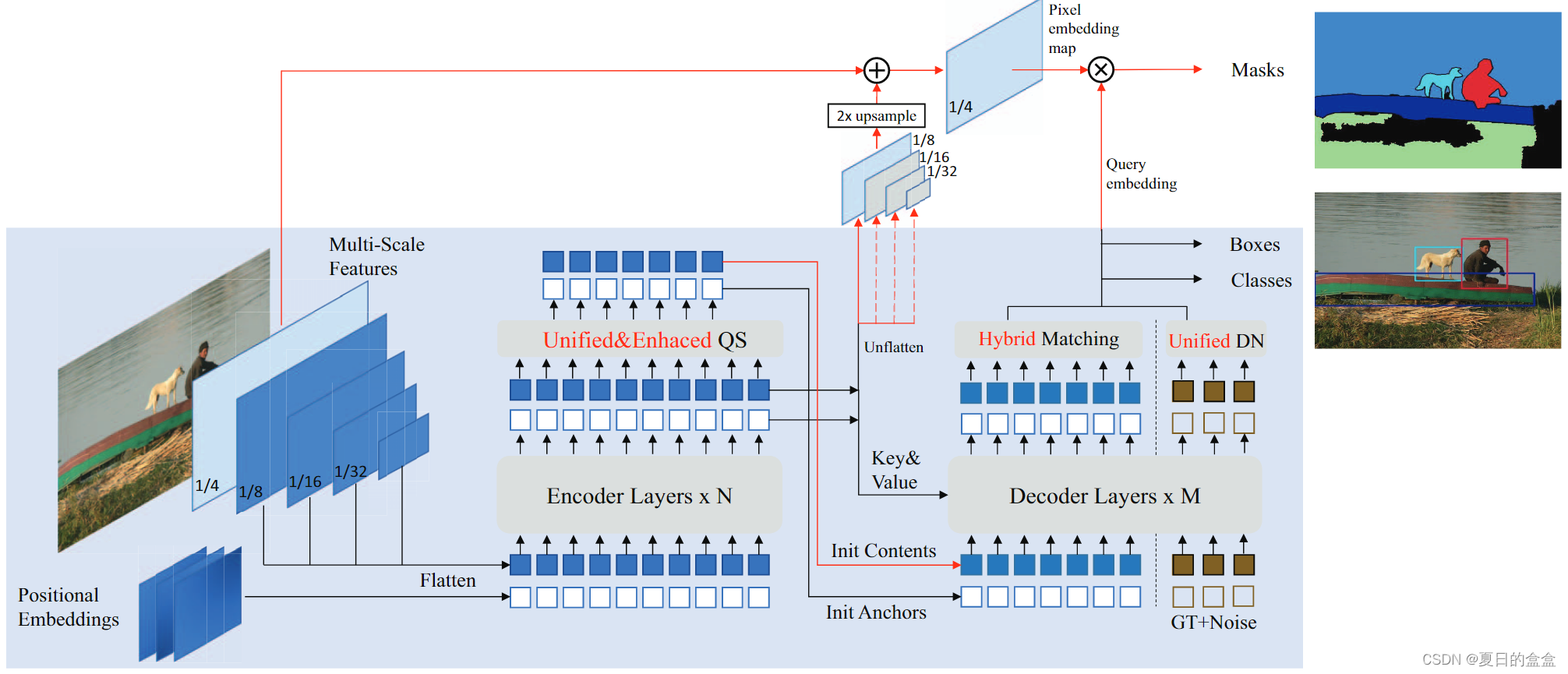
- 遵循DAB-DETR,DINO将DETR中的每个位置查询表示为一个4D锚框,并在每个解码器层中动态更新。注意,DINO使用了具有可变形注意力的多尺度特征。因此,更新后的锚框也被用来以稀疏和柔和的方式约束可变形注意力。
- 遵循DN-DETR,DINO采用去噪训练,并进一步发展对比去噪以加快训练收敛。
- 此外,DINO提出了一种混合查询选择方案来初始化解码器中的位置查询,并提出了一种前视两次的方法来改进box梯度反向传播。
3.2为什么通用模型没有取代DETR类模型中的专用模型
基于transformer的检测器和分割模型已经取得了显著的进展。例如,DINO和Mask2Former分别在COCO检测和全景分割上取得了最好的结果。在这种进展的启发下,我们试图简单地将这些专门的模型扩展到其他任务中,但发现其他任务的性能远远落后于原始任务,如表1和表2所示。看似微不足道的多任务训练甚至会损害原始任务的性能。然而,在基于卷积的模型中,将检测和实例分割任务相结合是有效和互利的。例如,Mask R-CNN头部的检测模型在COCO实例分割上仍然排名第一。我们将以DINO和Mask2Former为例讨论统一基于transformer的检测和分割的挑战。
- 专业检测模型和分割模型之间的区别是什么:图像分割是像素级的分类任务,而目标检测是区域级的回归任务。在基于DETR的模型中,解码器查询负责这些任务。例如,Mask2Former使用这种解码器查询来点积高分辨率特征图以产生分割掩码,而DINO使用它们来回归框。然而,由于Mask2Former中的此类查询只需要与图像特征进行逐像素相似性比较,因此它们可能不知道每个实例的区域级别位置。相反,DINO的查询不是为了与这种低级特征交互以学习像素级表示而设计的。相反,它们编码丰富的位置信息和用于检测的高级语义。
- 为什么Mask2Former不能很好地进行检测:
- 首先,它的查询遵循了DETR的设计,但没有利用条件DETR、锚点DETR和DAB-DETR所研究的更好的位置先验信息;例如,它的内容查询与Transformer编码器的特征在语义上对齐,而它的位置查询只是可学习的向量,如普通的DETR,而不是与单模位置相关联。如果我们删除它的mask分支,它就变成了DETR的变体,其性能不如最近改进的DETR模型。
- 其次,Mask2Former在Transformer解码器中采用了掩码注意力(multi-head attention with attention mask)。从上一层预测的注意力掩码具有高分辨率,并用作注意力计算的硬约束。它们对于框预测既不高效也不灵活。第三,Mask2Former不能显式地逐层执行盒细化。
- 此外,其在解码器中从粗到细的掩码细化未能利用编码器的多尺度特征。
3. 为什么DETR/DINO不能很好地进行分割
- DETR的分割头不是最优的。vanilla DETR让每个查询嵌入与最小特征图的点积,以计算注意力图,然后对它们进行上采样以获得掩码预测。这种设计缺乏查询与来自主干的更大特征图之间的交互。此外,头部过重,无法使用面罩辅助损失进行面罩细化。
- 原因是改进的检测模型中的特征与分割不一致。例如,DINO继承了[18], [32], [35] 的许多设计,如查询公式,去噪训练和查询选择。然而,这些组件旨在加强用于检测的区域级表示,这对分割不是最优的。
3.3Our Method: Mask Dino
Mask DINO采用了与DINO相同的检测架构设计,只是进行了最小的修改。在Transformer解码器中,Mask DINO添加了一个掩码分支以进行分割,并扩展DINO中的几个关键组件以进行分割任务。如图1所示,蓝色阴影部分的框架为原始DINO模型,红色线标记了用于分割的附加设计。
3.4分割的分支
遵循其他用于图像分割的统一模型Mask2Former、MaskFormer,我们对所有分割任务执行掩码分类。请注意,DINO 不是为像素级对齐而设计的,因为它的位置查询被表述为锚框,其内容查询用于预测框偏移和类成员资格。为了执行掩码分类,我们采用 Mask2Former的关键思想是构建一个从主干和 Transformer 编码器特征中获得的像素嵌入图。如图 1 所示,像素嵌入图是通过将主干中的 1/4 分辨率特征图 Cb 与 Transformer 编码器中的上采样 1/8 分辨率特征图 Ce 融合来获得的。然后,我们使用像素嵌入映射在解码器中对每个内容查询嵌入 qc 进行点积,以获得输出掩码 m。
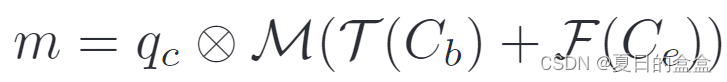
其中 M 是分割头,T 是卷积层,用于将通道维度映射到 Transformer 隐藏维度,F 是执行 Ce 2x 上采样的简单插值函数。该分割分支在概念上很简单,易于实现在DINO框架中。
3.3统一和增强查询选择
掩码的统一查询选择:查询选择已广泛用于传统的两阶段模型和许多类似 DETR 的模型以提高检测性能。我们进一步改进了Mask DINO中的查询选择方案来完成分割任务。
编码器输出特征包含密集特征,可以作为解码器更好的先验。因此,我们在编码器输出中采用了三个预测头(分类、检测和分割)。注意,这三个头与解码器的头是相同的。每个token的分类分数被视为置信度,以选择排名最高的特征,并将它们作为内容查询提供给解码器。所选特征还将回归框并与高分辨率特征图点积以预测掩码。预测的框和掩码将由地面真实值监督,并被视为解码器的初始锚点。请注意,我们在Mask DINO中初始化内容和锚框查询,而DINO只初始化锚框查询。
掩码增强的锚框初始化:如第 3.2 节所述,图像分割是一个像素级分类任务,而对象检测是一个区域级位置回归任务。因此,与检测相比,虽然分割是一项更困难的细粒度任务,但在初始阶段更容易学习。例如,掩码是通过使用高分辨率特征图的点积查询来预测的,这只需要比较逐像素语义相似性。然而,检测需要直接回归图像中的框坐标。因此,在统一查询选择后的初始阶段,掩码预测比框更准确(不同阶段的掩码预测和框预测之间的定性 AP 比较如表 8 和表 9 所示)。因此,在统一的查询选择之后,我们从预测的掩码中导出框作为解码器更好的锚框初始化。通过这种有效的任务合作,增强的框初始化可以显着提高检测性能。
3.4Segmentation Micro Design
掩码的统一去噪:目标检测中的查询去噪已经显示出有效的[15,32]来加速收敛和提高性能。它将噪声添加到groundtruth框和标签中,并将它们提供给Transformer解码器作为噪声位置查询和内容查询。该模型经过训练以在给定噪声版本的情况下重建地面实况对象。我们还将这种技术扩展到分割任务。由于掩码可以被视为框的更细粒度的表示,因此框和掩码是自然连接的。因此,我们可以将框视为掩码的噪声版本,并训练模型预测给定框的掩码作为去噪任务。给定用于掩码预测的框也被随机噪声,以实现更有效的掩码去噪训练。
Hybrid matching:Mask DINO,就像在一些传统模型 [2, 9] 中一样,它以松散耦合的方式预测具有两个并行头的框和掩码。因此,两个头可以预测一对彼此不一致的框和掩码。为了解决这个问题,除了二部匹配中的原始框和分类损失外,我们还添加了掩码预测损失,以鼓励一个查询更准确和一致的匹配结果。因此,匹配成本变为![]() ,其中Lcls、Lbox 和 Lmask 是分类、框和掩码损失,λ 是它们对应的权重。
,其中Lcls、Lbox 和 Lmask 是分类、框和掩码损失,λ 是它们对应的权重。
四、实验
分割结果:
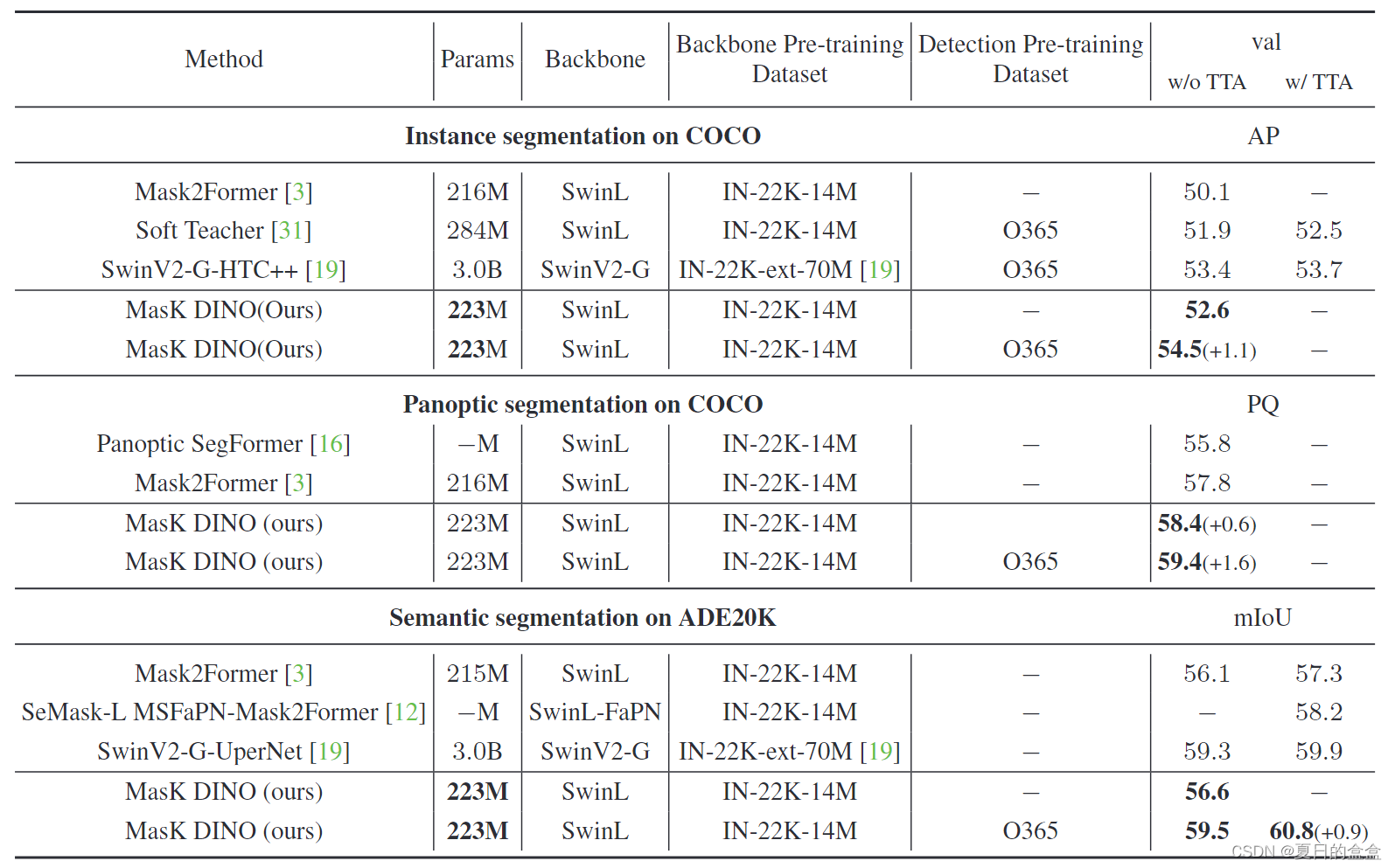
在COCO val2017上使用ResNet-50和SwinL骨干的Mask DINO和其他目标检测和实例分割模型的结果 :
五、结论
在本文中,我们提出了 Mask DINO 作为一个统一的基于 Transformer 的框架,用于对象检测和图像分割。从概念上讲,Mask DINO是DINO从检测到分割的自然扩展,对一些关键组件进行了最小的修改。Mask DINO 优于以前的专业模型,并在 10 亿个参数下的模型中在所有三个分割任务(实例、全景和语义)上都取得了最佳结果。
此外,Mask DINO 表明检测和分割可以在基于查询的模型中相互帮助。特别是,Mask DINO 支持语义和全景分割,以从在大规模检测数据集上预训练的更好的视觉表示中受益。我们希望Mask DINO可以为实现任务合作和数据合作,为更多的视觉任务设计通用模型提供见解。局限性:在COCO全景分割中,不同的分割任务无法在Mask DINO中实现相互帮助。例如,在COCO全景分割中,掩码AP仍然落后于仅使用实例训练的模型。

















 1957
1957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









