






Datawhale干货
作者:阿水、北航硕士、Datawhale成员
本项目以科大讯飞《智能家居使用场景识别挑战赛》为实践背景,详细讲解了数据挖掘分类实践任务的解题思路,针对该项目给出了完整实践代码供大家学习实践。
项目来源
为了让用户切身感受到智能家居产品的智能化和便捷性,每个代理商均有自己的智能家居体验店和展厅。在智能家居体验过程中,需要针对展厅类的场景做特殊的场景优化。识别当前智能家居产品使用环境是真实的家庭还是智能化体验的公共区域至关重要。
赛事地址:https://challenge.xfyun.cn/topic/info?type=smart-home-2022&ch=ds22-dw-gy02
思路解读
解题思路
本题的任务是构建一种模型,用于预测智能家居产品所处的环境场景类别。这种类型的任务是典型的二分类问题(家庭/公共区域),模型的预测输出为 0 或 1。
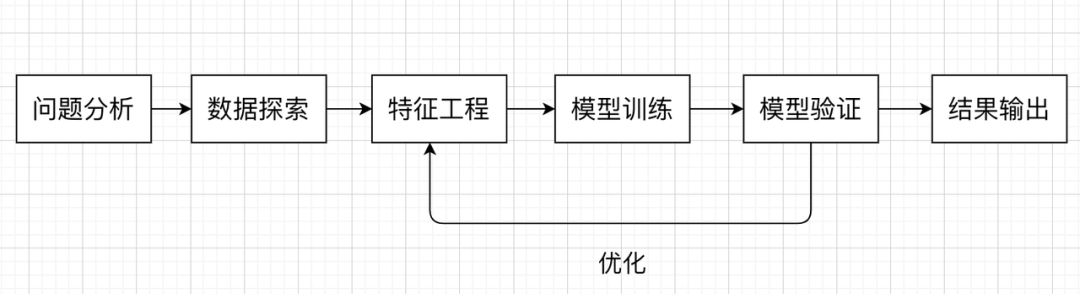
机器学习中,关于分类任务我们一般会想到逻辑回归、决策树、随机森林等算法,在这个 Baseline 中,我们尝试使用随机森林来构建我们的模型。我们在解决机器学习问题时,一般会遵循以下流程:
代码实现
以下代码,请在jupyter notbook或python编译器环境中实现。
完成实践文档:https://xj15uxcopw.feishu.cn/docx/doxcn1OvgxBzjpx2Ggh2p5umVEh
导入模块
#安装相关依赖库 如果是windows系统,cmd命令框中输入pip安装,参考上述环境配置
#!pip install sklearn
#!pip install pandas
#!pip install numpy
#!pip install codecs
#导入库
#----------------数据探索----------------
import pandas as pd
import numpy as np
import codecs
#----------------核心模型----------------
from sklearn.ensemble import RandomForestClassifier
#----------------忽略报警----------------
import warnings
warnings.filterwarnings('ignore')数据预处理
本次比赛为参赛选手提供了4类数据:账号信息、设备列表、控制操作日志、设备上报日志。其中账号基础数据的训练集我们会打上使用场景是家庭用户还是体验厅的标签。
比赛赛题是一个典型的多表建模任务,我们需要考虑:
如何对单张表提取特征
如何将多张表特征聚合到一起
数据预处理后会发现,本赛题数据比较干净,不存在缺失值和异常值。
# 读取训练数据和测试数据
# 由于原始数据包含的格式不对,这里自行定义了数据读取
def robust_readcsv(path, sep=','):
try:
lines = codecs.open(path).readlines()
except:
lines = codecs.open(path, encoding='latin-1').readlines()
header = lines[0].strip().split(sep)
content = []
for line in lines[1:]:
line = line.strip()
try:
index = [i for i, x in enumerate(line) if x == ',']
if len(index) == len(header) - 1:
content.append(line.split(sep))
else:
line_content = []
index = [0] + index
for idx in range(len(header)-1):
line_content.append(line[index[idx]:index[idx+1]].strip(sep))
line_content.append(line[index[len(header)-1]:].strip(sep))
content.append(line_content)
except:
pass
return pd.DataFrame(content, columns=header)
# 主表:训练集和测试集
train_cus = pd.read_csv('智能家居使用场景识别挑战赛数据集/训练集/cus.csv', sep=',')
test_cus = pd.read_csv('智能家居使用场景识别挑战赛数据集/测试集/cus.csv', sep=',')
# 其他表:设备列表
train_devupdate = robust_readcsv('智能家居使用场景识别挑战赛数据集/训练集/devUpdata.csv', sep=',')
test_devupdate = robust_readcsv('智能家居使用场景识别挑战赛数据集/测试集/devUpdata.csv', sep=',')
# 其他表:操作表
train_control = robust_readcsv('智能家居使用场景识别挑战赛数据集/训练集/control.csv', sep=',')
test_control = robust_readcsv('智能家居使用场景识别挑战赛数据集/测试集/control.csv', sep=',')
# 其他表:设备更新表
train_devlist = robust_readcsv('智能家居使用场景识别挑战赛数据集/训练集/devList.csv', sep=',')
test_devlist = robust_readcsv('智能家居使用场景识别挑战赛数据集/测试集/devList.csv', sep=',')
# 数据集shape信息,快速了解数据基本情况
train_cus.shape, test_cus.shape
train_devupdate.shape, test_devupdate.shape
train_control.shape, test_control.shape
train_devlist.shape, test_devlist.shape特征工程
将多个表的字段进行合并,然后和主表进行merge得到可以训练的数据。这里对单张表的数据特征提取可以自行选择,下面的代码只进行了基础的数据统计。
#不同数据集中以uid做分组,不同维度唯一值的统计次数
train_devupdate_feat = train_devupdate.groupby('uid').agg({
'did': 'nunique',
'data': 'nunique',
})
train_devupdate_feat.reset_index(inplace=True)
train_devupdate_feat.columns = ['uid', 'devupdate_did_count', 'devupdate_data_count']
test_devupdate_feat = test_devupdate.groupby('uid').agg({
'did': 'nunique',
'data': 'nunique',
})
test_devupdate_feat.reset_index(inplace=True)
test_devupdate_feat.columns = ['uid', 'devupdate_did_count', 'devupdate_data_count']
train_control_feat = train_control.groupby('uid').agg({
'did': 'nunique',
'form': 'nunique',
'data': 'nunique',
})
train_control_feat.reset_index(inplace=True)
train_control_feat.columns = ['uid', 'devcontrol_did_count',
'devcontrol_form_count', 'devcontrol_data_count']
test_control_feat = test_control.groupby('uid').agg({
'did': 'nunique',
'form': 'nunique',
'data': 'nunique',
})
test_control_feat.reset_index(inplace=True)
test_control_feat.columns = ['uid', 'devcontrol_did_count',
'devcontrol_form_count', 'devcontrol_data_count']
train_devlist_feat = train_devlist.groupby('uid').agg({
'did': 'nunique',
'type': 'nunique',
'area': ['unique', 'nunique', 'count']
})
train_devlist_feat.reset_index(inplace=True)
train_devlist_feat.columns = [x[0] + x[1] for x in train_devlist_feat.columns]
test_devlist_feat = test_devlist.groupby('uid').agg({
'did': 'nunique',
'type': 'nunique',
'area': ['unique', 'nunique', 'count']
})
test_devlist_feat.reset_index(inplace=True)
test_devlist_feat.columns = [x[0] + x[1] for x in test_devlist_feat.columns]
#所有训练集的表组合为train_feat
train_feat = train_cus.merge(train_devlist_feat, on='uid')
train_feat = train_feat.merge(train_control_feat, on='uid', how='left')
train_feat = train_feat.merge(train_devupdate_feat, on='uid', how='left')
train_feat.fillna(0, inplace=True)
#所有测试集的表组合为test_feat
test_feat = test_cus.merge(test_devlist_feat, on='uid')
test_feat = test_feat.merge(test_control_feat, on='uid', how='left')
test_feat = test_feat.merge(test_devupdate_feat, on='uid', how='left')
test_feat.fillna(0, inplace=True)
#使用tfidf算法做文本特征提取
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(max_features=400)
train_dev_tfidf = tfidf.fit_transform(train_feat['areaunique'].apply(lambda x: ' '.join(x)))
test_dev_tfidf = tfidf.transform(test_feat['areaunique'].apply(lambda x: ' '.join(x)))
train_dev_tfidf = pd.DataFrame(train_dev_tfidf.toarray(), columns=tfidf.get_feature_names())
test_dev_tfidf = pd.DataFrame(test_dev_tfidf.toarray(), columns=tfidf.get_feature_names())
train_feat = pd.concat([train_dev_tfidf, train_feat], axis=1)
test_feat = pd.concat([test_dev_tfidf, test_feat], axis=1)训练模型
作为基线方案将选择经典的随机森林分类器作为模型。
clf = RandomForestClssifier()
clf.fit(train_feat.drop(['uid', 'label', 'areaunique'], axis=1), train_feat['label'])
test_cus['label'] = clf.predict(test_feat.drop(['uid','areaunique'], axis=1),)结果保存
test_cus.to_csv('result.csv', index=None)
往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码














 8070
8070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









