







data mining
几种距离
欧氏距离

曼哈顿距离
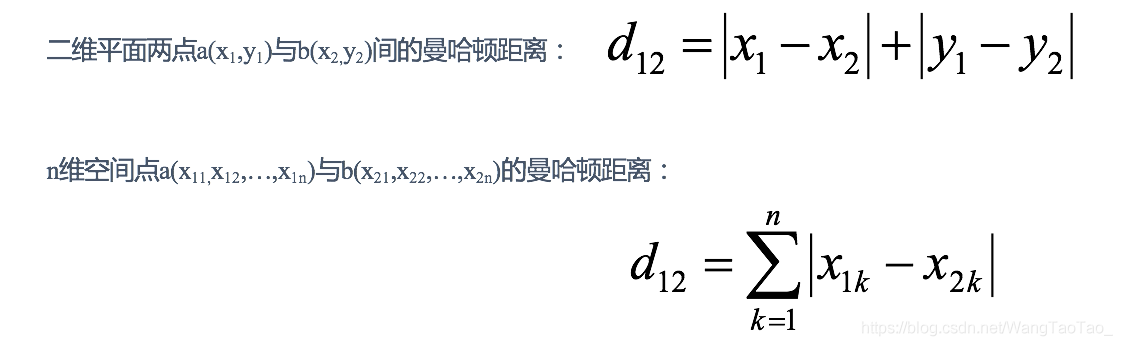
K-Means
局限性
- 能得到局部最优解,不保证全局最优
- 相似度计算和比较时的计算量较大
基于MapReduce的分类算法
KNN K-邻接分类并行化算法
- 总体思想:计算测试样本,到训练样本的距离,选取距离最小的k个,并根据这k个训练样本的标记,并根据k个训练的标记进行加权投票
- 加权投票模型: y’ = ∑Si*yi/∑Si, k=[0,k-1],Si为取值0-1的相似度数值,yi为选取出的最邻近训练样本的分类标记值
MapReduce并行化设计思路
- 将测试样本分块后,分布在不同节点上进行处理,将训练样本数据文件放在DistributedCache中共每个节点访问
- Map: 读出每个此时样本数据 ts(trid,A’,y’)
- Map: 计算与每个训练样本的相似度 S,保留前K个最大的。
- Map: 根据前K大的S值,计算 y‘= ∑Si*yi/∑Si, k=[0,k-1] ,输出(trid,y’)
- Reduce 阶段直接输出(trid, y’)
朴素贝叶斯分类
P
(
Y
i
∣
X
)
=
P
(
Y
i
)
∗
P
(
X
∣
Y
i
)
/
P
(
X
)
P(Yi|X) = P(Yi)*P(X|Yi) / P(X)
P(Yi∣X)=P(Yi)∗P(X∣Yi)/P(X)
y
=
arg
max
c
k
P
(
Y
=
c
k
)
∏
j
P
(
X
j
=
x
j
∣
Y
=
c
k
)
y = \arg\max_{ck} P(Y=ck)\prod_j P(X_j = x_j|Y=ck)
y=argckmaxP(Y=ck)j∏P(Xj=xj∣Y=ck)
- 朴素贝叶斯分类公式
- 选择的概率最大的y 注意是 P(X|Yi)*P(Yi) , 而不是P(X|Yi)最大
并行化算法设计思路
- 计算每个分类的频度FYi,以及每个属性值在Yi中出现的频度FxYij
- 对一个未标记的测试样本X,根据其包含的每个具体属性值xj,根据从训练数据集计算出的FxYij进行求积得到FXYi(即P(X|Yi)),再乘以FYi即可得到X在各个Yi中出现的频度P(X|Yi)P(Yi),取得最大频度的Yi即为X所属的分类
第一步统计频度


输出 Yi出现的频度 和 所有属性 xj 在 Yi中出现的频度
第二步 样本分类预测

基于MapReduce的频繁项集挖掘算法
-
频繁项可以看作是两个或者多个对象的“亲密”程度,如果同时出现次数很多,可以认为这两个对象是高关联度的
-
支持度 support=M/N
-
N是总条目
-
M是项集出现的次数
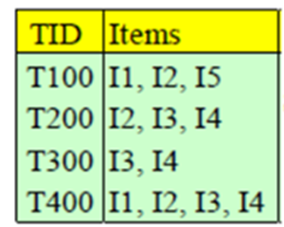
这里的N是4,项集I = {I1,I2}出现次数是2,支持度为 2/4 = 0.5
如果support(I) 不小于设定的阈值,则认为I是一个频繁项集
频繁项集挖掘问题,找出所有的频繁k项集
Apriori算法
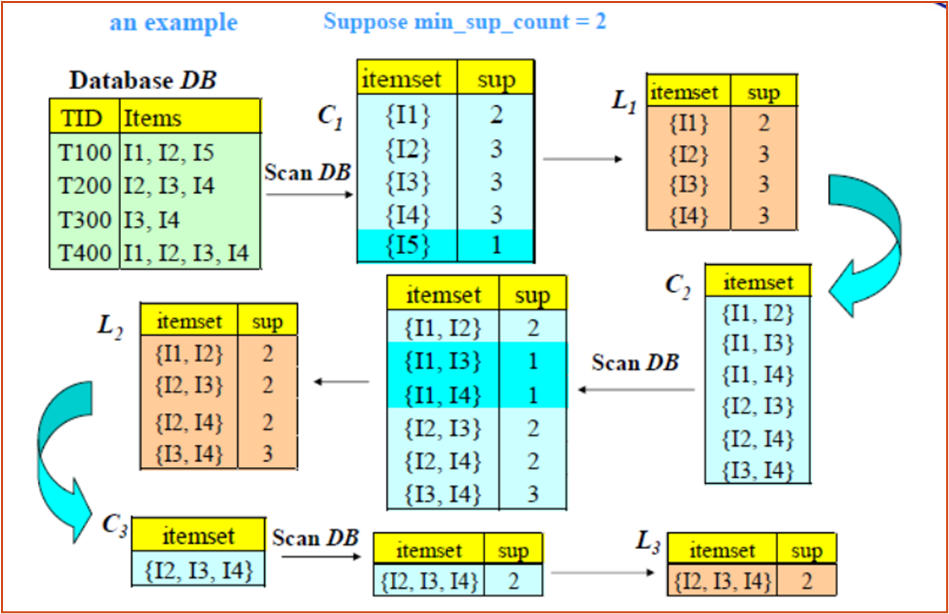
- Apriori算法 通过多轮迭代的方法来逐步挖掘频繁项集
- 第一轮迭代中,发现所有的频繁 1 项集
- 在之后的每一轮迭代中,将前一轮的频繁 k-项集作为本轮迭代的种子项集,由此生成候选 (k+1)-项集
- 在本轮迭代中,需要计算每个候选(k+1)-项集在事务数据库中的支持度,以找出频繁项集
- 生成候选项集,任何频繁项集的非空子项集都是频繁的,
- 非频繁项集的任何超集都是非频繁的















 2649
2649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









