






✦
框架选型
✦
SSSegmentation
SSSegmentation 是一个基于 PyTorch 的开源强监督语义分割工具箱。仓库地址:
https://github.com/SegmentationBLWX/sssegmentation 。它为各种语义分割方法提供了一个统一的基准工具箱。将语义分割框架分解为不同的组件,通过组合不同的模块可以轻松构建个性的语义分割框架。一些比较流行的分割网络开箱即用,如 ISNet, DeepLabV3, PSPNet, MCIBI 等。
如何安装:
克隆 sssegmentation 存储库。
git clone https://github.com/SegmentationBLWX/sssegmentation.git
cd sssegmentation
安装依赖。
pip install -r requirements.txt
安装 mmcv-full 的 pre-build 包。
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html
安装对应版本的 torch 和 torchvision。
# CUDA 11.0
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
# CUDA 10.2
pip install torch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0
构建一些 api,例如 coco 数据集的 api(如果不使用 coco,则无需此操作)。
cd ssseg/libs
sh make.sh
安装 sssegmentation(可选的)。
pip install -e .
TorchSeg
该框架也使用 PyTorch 为语义分割模型提供快速、模块化的参考实现。地址:https://github.com/ycszen/TorchSeg 。相对于 SSSegmentation,有下面几点优势:
模块化设计:通过组合不同的组件,轻松构建定制的语义分割模型。此外,支持更多的语义分割数据集。
分布式训练:比多线程并行方法 nn.DataParallel 快 60%,我们使用多进程并行方法。
多 GPU 训练和推理:支持不同的推理方式。
关于该框架的配置和训练方式,在 README 里有更详细的介绍。
Fast_Seg
先给出Fast_Seg的地址:https://github.com/lxtGH/Fast_Seg 。
该框架在一些道路场景数据集(CityScape、Mapillary、Camvid)上实现了最快速语义分割模型。其中,ICnet 实现后评估达到了 74.5% mIoU,比原始论文高出5%。
Fast_Seg 已经提供的 Model Zoo 如下:
1. ICNet:ICnet for real-time semantic segmentation on high-resolution images. ECCV-2018, paper
2. DF-Net: Partial Order Pruning: for Best Speed/Accuracy Trade-off in Neural Architecture Search.CVPR-2019, paper
3. Bi-Seg: Bilateral segmentation network for real-time semantic segmentation.ECCV-2018, paper
4. DFA-Net: Deep feature aggregation for real-time semantic segmentation.CVPR-2019,paper
5. ESP-Net: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation. ECCV-2018,paper
6. SwiftNet: In defense of pre-trained imagenet architectures for real-time semantic segmentation of road-driving images. CVPR2019, paper
7. Real-Time Semantic Segmentation via Multiply Spatial Fusion Network.(face++) arxiv,paper
8. Fast-SCNN: Fast Semantic Segmentation Network.BMVC-2019 paper
Fast_Seg使用简单,配置后使用 train_distribute.py 开启训练,使用 prediction_test_different_size.py 调整不同大小输入的预测。
✦
模型选型
✦
FCN
对于一般的分类 CNN 网络,如 VGG 和 Resnet,都会在网络的最后加入一些全连接层,经过 softmax 后就可以获得类别概率信息。但是这个概率信息是 1 维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适用于图像分割。
而 FCN 提出可以把后面几个全连接都换成卷积,这样就可以获得一张 2 维的 feature map,后接 softmax 获得每个像素点的分类信息,从而解决了分割问题。关于 FCN,这里不做更多的介绍了。
U-Net Family
U-Net 系列的改进网络,可以分为 2 dim 和 3 dim,这里挑选了一部分介绍下。关于 SE 结构在 U-Net 网络中的应用,就不多说了,SE 是在竞赛中最常用的长点手段。
Attention-Unet
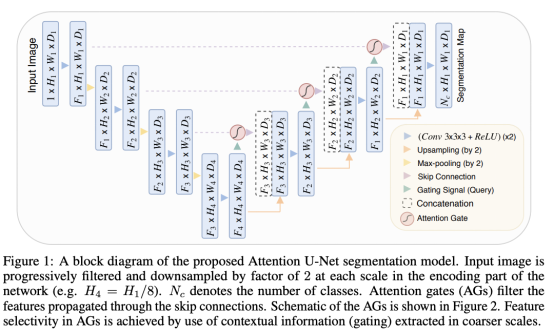
Attention-Unet 的主要目标是,抑制输入图像中的不相关区域,同时突出特定局部区域的显著特征;用 soft-attention 代替 hard-attention 的思路(注意:soft-attention 可微,可以微分的 attention 就可以通过神经网络算出梯度并且前向传播和后向反馈来学习得到 attention 的权重);集成到标准 U-Net 网络结构中时要简单方便、计算开销小,最重要的是提高模型的灵敏度和预测的精度。
将 Attention 融入到 U-Net 的结构如下图所示。
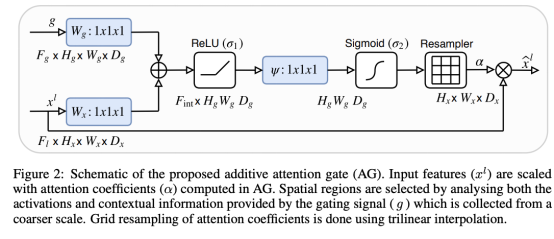
Attention Gate(AG)的具体结构如下图所示。
U-Net++
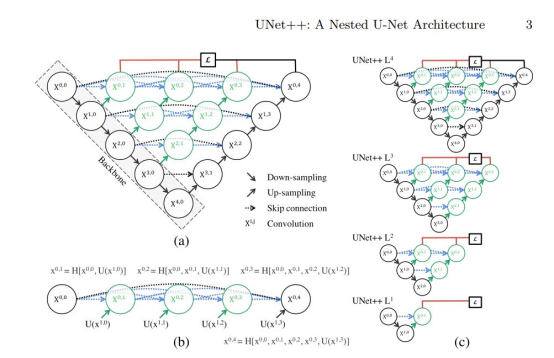
U-Net++ 在于把不同尺寸的 U-Net 结构融入到了一个网络里。我们知道,在运用 CNN 的分割问题上,主要分为以 FCN 为基础的结构,和以 U-Net 为基础的结构。前者的 encoder-decoder 是非对称的,后者的 encoder-decoder 是对称的;另外两者的特征融合方式也有些差别。但本质上分割网络都是差不多的:先 encoder 再decoder。那么到底 encoder 应该多大,decoder 应该多大呢?
相对于原来的 U-Net网络,Unet++ 把 1~4 层的 U-Net 全给链接在一起了。这个结构的好处就是让网络自己去学习不同深度的特征的重要性。第二个好处是它共享了一个特征提取器,也就是你不需要训练一堆 U-Net,而是只训练一个 encoder,它的不同层次的特征由不同的 decoder 路径来还原。这个 encoder 依旧可以灵活的用各种不同的 backbone 来代替。
Unet++ 主要改进就是将原来空心的 U-Net 填满了,优势是可以抓取不同层次的特征,将它们通过特征叠加的方式整合,不同层次的特征,或者说不同大小的感受野,对于大小不一的目标对象的敏感度是不同的,比如,感受野大的特征,可以很容易的识别出大物体的,但是在实际分割中,大物体边缘信息和小物体本身是很容易被深层网络一次次的降采样和一次次升采样给弄丢的,这个时候就可能需要感受野小的特征来帮助。
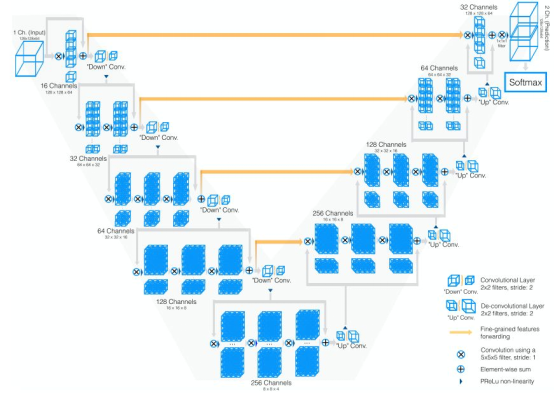
V-Net
V-Net 有几个需要重点关注的地方, 基本上网络架构就是 3D conv+residual Block 版的 U-Net,池化用卷积代替,转置卷积上采样。V-Net 的论文中提出了一个新的指标函数,类似 IoU、Pa,叫做 Dice coefficient。下图是 V-Net 的网络架构。进行卷积的目的是从数据中提取特征,并在每个阶段的最后通过使用适当的步幅降低其分辨率。网络的左侧部分由编码路径组成,而右侧部分对信号进行解码,直到达到其原始大小为止。卷积全部使用适当的 padding 操作。
nn-Unet
一种鲁棒的基于 2D UNe t和 3D UNet 的自适应框架。这个框架和目前的 STOA 方法进行了比较,且该方法不需要手动调参,nnUNet 都得到了最高的平均 dice 值。通过简单的使用U-Net一种结构,一棒子打死了近年来所有的新的网络结构。认为网络结构上的改进并没有什么用,应该更多的关注结构以外的部分,比如预处理、训练和推理策略、后处理等部分。
Trans-Unet
在语义分割上,FCN 这类卷积的编码器-解码器架构衍生出的模型在过去几年取得了实质性进展,但这类模型存在两个局限。第一,卷积仅能从邻域像素收集信息,缺乏提取明确全局依赖性特征的能力;第二,卷积核的大小和形状往往是固定的,因此它们不能灵活适应输入的图像或其他内容。相反,Transformer architecture 由于自注意力机制具有捕获全局依赖特征的能力,且允许网络根据输入内容动态收集相关特征。
Transformer 建立在多头自注意机制 (MHSA) 模块上,MHSA 是由多个 Self-Attention 组成的。下图是 Self-Attention 的结构,在计算的时候需要用到矩阵 Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量 x 组成的矩阵 X) 或者上一个 Encoder block 的输出。而 Q,K,V 是通过 Self-Attention 的输入进行线性变换得到的。
得到矩阵 Q, K, V 之后就可以计算出 Self-Attention 的输出了,计算的公式如下。其中 d 是 Q,K 矩阵的列数(向量维度),公式中计算矩阵 Q 和 K 每一行向量的内积,为了防止内积过大,因此除以 d 的平方根。将 Q, K, V 展平并转置为大小为 n × d 的序列,其中 n = HW。P ∈ Rn×n 被命名为上下文聚合矩阵,用作权重以收集上下文信息。
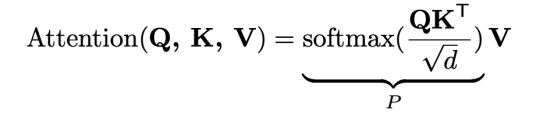
通过这种方式,self-attention 本质上具有全局感受野,擅长捕捉全局依赖。此外,上下文聚合矩阵可以适应输入内容,以实现更好的特征聚合。关于更细节的内容,这里就不多介绍了。需要关注的是,n×d 矩阵的点乘会导致 O(n2d) 复杂度。通常,当特征图的分辨率很大时,n 远大于 d,因此序列长度 n 在自注意力计算中占主导地位,这使得高分辨率特征图中应用自注意力是不可行的,例如对于 16 × 16 特征图,n = 256,对于 128 × 128 特征图,n = 16384。
回到 TransUNet 本身,它同时具有 Transformers 和 U-Net 的优点,是医学图像分割的强大替代方案。一方面,Transformer 将来自卷积神经网络(CNN)特征图的标记化图像块编码为提取全局上下文的输入序列。另一方面,解码器对编码的特征进行上采样,然后将其与高分辨率的 CNN 特征图组合以实现精确的定位。借助 U-Net 的组合,通过恢复局部的空间信息,可以将 Transformers 用作医学图像分割任务的强大编码器。

SegNet
SegNet 也是传统的编码-解码结构,和 U-Net 最大的区别在于,U-Net 用于生物医学图像分割,U-Net 整个特征映射不是使用池化索引,而是从编码器传输到解码器,然后使用 concatenation 串联来执行卷积。这使模型更大,需要更多内存。
SegNet 的结构如下图所示:
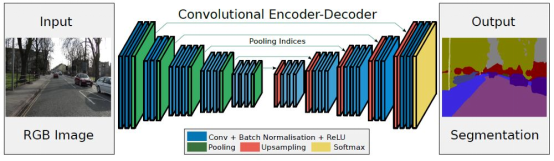
SegNet 尝试了两个数据集。一个是用于道路场景分割的 CamVid 数据集。一个是用于室内场景分割的 SUN RGB-D 数据集。
Deeplabv3
Deeplab 网络是一个专门用来处理语义分割的模型,有 Deeplabv1, Deeplabv2 和Deeplabv3。因为之前的语义分割网络存在池化导致丢失了信息,并且没有利用标签之间的概率关系,所以Deeplab系列使用空洞卷积来避免池化带来的信息损失。
Deeplabv3为解决多尺度物体问题给出四种方案:
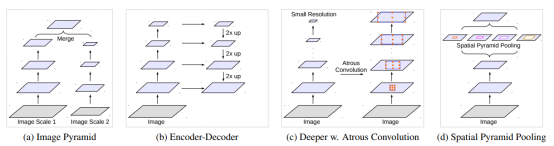
把输入图片缩放成不同尺度,经过同一个网络后最终融合成一个特征图。
在解码过程中融合编码过程网络中不同阶段的特征图。
在原先网络中加入 context 模块。
最后一层中加入并行结构SPP(空间金字塔池化),获取不同尺度的物体信息。
使用并行池化解决随着膨胀率的增大而使卷积核的权重无效问题。
✦
常用 trick 介绍
✦
从 Loss 上解决数据集imbalance 的方法
比如小目标图像分割任务(医疗方向),往往一幅图像中只有一个或者两个目标,而且目标的像素比例比较小,使网络训练较为困难,一般可能有三种的解决方式:
选择合适 Loss function,对网络进行合理的优化,关注较小的目标。
改变网络结构,使用 attention 机制(类别判断作为辅助)。
与上面的根本原理一致,类属 attention,即:先检测目标区域,裁剪之后进行分割训练。
值得注意的是,通过使用设计合理的 Loss function,相比于另两种方式要更加简单易行,能够保留图像所有信息的情况下进行网络优化,达到对小目标精确分割的目的。
上采样方法
上采样的技术是图像进行超分辨率的必要步骤,上采样大致被总结成了三个类别:
基于线性插值的上采样。
基于深度学习的上采样(转置卷积)。
Unpooling 的方法。其实第三种只是做各种简单的补零或者扩充操作。
其中,线性插值用的比较多的主要有三种:最近邻插值算法、双线性插值、双三次插值(BiCubic),当然还有各种其改进型。如今S这些方法仍然广泛应用。这些方法各有优劣和劣势,主要在于处理效果和计算量的差别。计算效果上:最近邻插值算法 < 双线性插值 < 双三次插值,计算速度上:最近邻插值算法 > 双线性插值 > 双三次插值。
基于深度学习的上采样,有转置卷积、PixelShuffle(亚像素卷积,CVPR2016)、DUpsampling(亚像素卷积,CVPR2019)、Meta-Upscale(任意尺度缩放,CVPR2019)和 CAPAFE(内容关注与核重组,ICCV2019)等。
超参数调节
超参数调节不只是图像分割任务的重点,下面仅列出了几种需要重点关注的策略。
关于 MRI 类型的数据。数据预处理更加重要,对噪声的处理比较关键(比赛数据则不必担心)。
如何训练。
🔸观察训练趋势,metric 和 loss 的曲线。
🔸根据任务和数据不同,loss 的值会有差别。
🔸停止训练的标志:验证集上指标曲线达到高点且平稳。
使用多个而不是单一学习率。
🔸差分学习率(Differential Learning rates)。
🔸基于已有模型来训练深度学习网络。
🔸大部分已有网络(如 Resnet、VGG 和 Inception 等)都是在 ImageNet 数据集训练的,因此我们要根据所用数据集与 ImageNet 图像的相似性,来适当改变网络权重。
如何找到合适的学习率。
🔸周期性学习率。
🔸用余弦函数来降低学习率。
🔸带重启的 SGD 算法。
更多内置函数:Dropout 层、TTA。TTA 可以为原始图像造出多个不同版本,包括不同区域裁剪和更改缩放程度等,并将它们输入到模型中;然后对多个版本进行计算得到平均输出,作为图像的最终输出分数。
— End —

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码













 1293
1293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









