






今儿给大家带来的是关于特征工程的相关处理方式,特征工程是提升模型性能的关键环节。
特征工程通过提取、选择和转换数据特征,可以更好地捕捉数据中的模式和关系。它直接影响模型的学习能力和预测效果,是高质量机器学习模型的基础。特征工程可以有效减少数据噪声、提升模型的泛化能力,并在复杂问题中帮助模型更好地理解数据。
今天我会把最重要、最常用的一些方式先和大家进行简单分享,后面一段时间,我会把其他常见的处理方式都分享出来~
特征选择:递归特征消除(RFE)
特征缩放:标准化(Standardization)
特征编码:独热编码(One-Hot Encoding)
降维:主成分分析(PCA)
特征构造:多项式特征
特征离散化:分位数分箱(Quantile Binning)
特征组合:加法组合
特征选择:LASSO
时间序列特征提取:滑动窗口
文本特征提取:TF-IDF
一起来学习~
1 特征选择:递归特征消除(RFE)
原理
递归特征消除(RFE)是一种特征选择技术,它通过递归地训练模型,并根据模型的重要性逐步消除特征,最终保留最优特征子集。RFE 从所有特征开始,训练模型,并根据某种准则(如权重或系数)评估每个特征的重要性。然后消除最不重要的特征,再重复这一过程,直到达到预定的特征数量或性能。
核心公式
1. 模型训练:选择一个基础模型 ,如线性回归或支持向量机。
2. 特征重要性计算:基于训练后的模型,计算每个特征的重要性分数 ,如线性模型中的回归系数或支持向量机中的权重。
其中 是模型的损失函数, 是第 个特征。
3. 特征消除:移除最不重要的特征(即 最小的特征)。
4. 递归执行:在新的特征子集上重复上述过程,直到达到预定的特征数量。
优缺点与适用场景
优点:
RFE 能有效选择出对模型最重要的特征,从而提升模型的泛化性能。
适用于多种模型,如线性回归、SVM、决策树等。
缺点:
计算成本高,尤其是在特征数量庞大时。
选择的特征子集依赖于选择的基础模型,不同模型可能选择不同的特征子集。
适用场景:
需要解释性强的模型场景,如医学数据分析。
在拥有大量特征的数据集上,需要降维以提高模型性能和可解释性。
核心案例代码
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_classification
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
# 生成模拟数据
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, random_state=42)
# 初始化逻辑回归模型
model = LogisticRegression()
# 进行递归特征消除
rfe = RFE(model, n_features_to_select=5)
fit = rfe.fit(X, y)
# 绘制特征排序图
plt.figure(figsize=(10, 6))
plt.barh(range(X.shape[1]), fit.ranking_, color='skyblue')
plt.xlabel("Ranking")
plt.ylabel("Feature Index")
plt.title("Feature Ranking with RFE")
plt.show()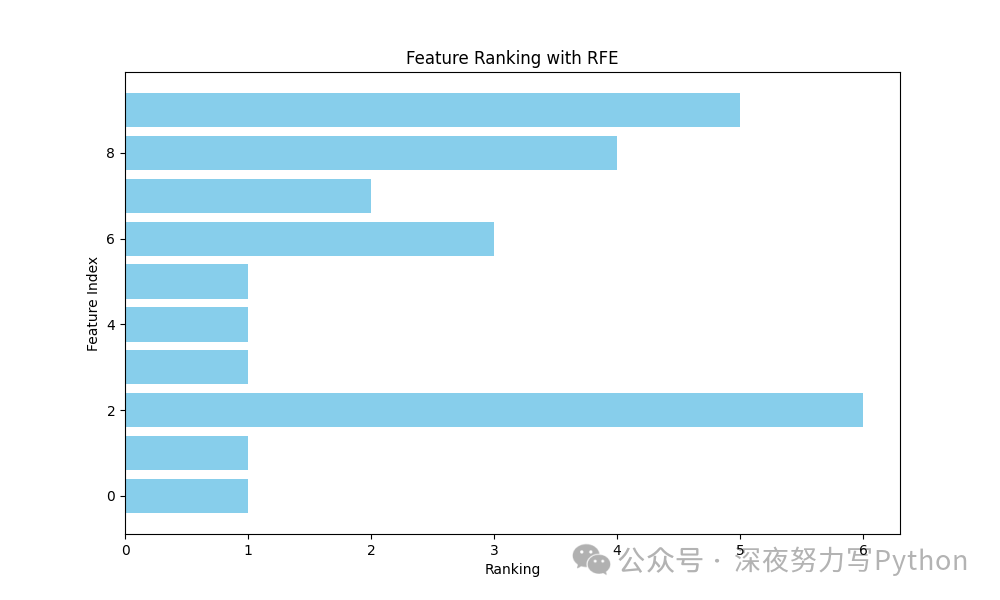
2 特征缩放:标准化(Standardization)
原理
标准化是特征缩放的一种技术,通过将数据的均值调整为零,标准差调整为一,以确保不同特征在同一尺度上进行比较。标准化特别适用于需要比较不同特征贡献的机器学习算法,如线性回归、SVM、KNN等。
核心公式
标准化过程通过以下公式进行:
其中:
是标准化后的特征值。
是原始特征值。
是特征的均值。
是特征的标准差。
推导:
数据中心化:将所有特征值减去均值 。
数据缩放:将结果除以标准差 ,使数据方差为 1。
优缺点与适用场景
优点:
在特征尺度不一致的情况下,标准化可以提高模型的训练效果。
标准化后的数据使梯度下降更快收敛。
缺点:
对于不受尺度影响的模型,如树模型(决策树、随机森林),标准化效果不明显。
适用场景:
算法依赖于特征距离或方差,如线性回归、SVM、KNN、PCA。
核心案例代码
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_wine
# 加载数据
data = load_wine()
X = data.data
# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 对比标准化前后的分布
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.hist(X[:, 0], bins=30, color='blue', alpha=0.7, label='Original')
plt.title('Original Feature Distribution')
plt.xlabel(data.feature_names[0])
plt.legend()
plt.subplot(1, 2, 2)
plt.hist(X_scaled[:, 0], bins=30, color='green', alpha=0.7, label='Standardized')
plt.title('Standardized Feature Distribution')
plt.xlabel(data.feature_names[0])
plt.legend()
plt.show()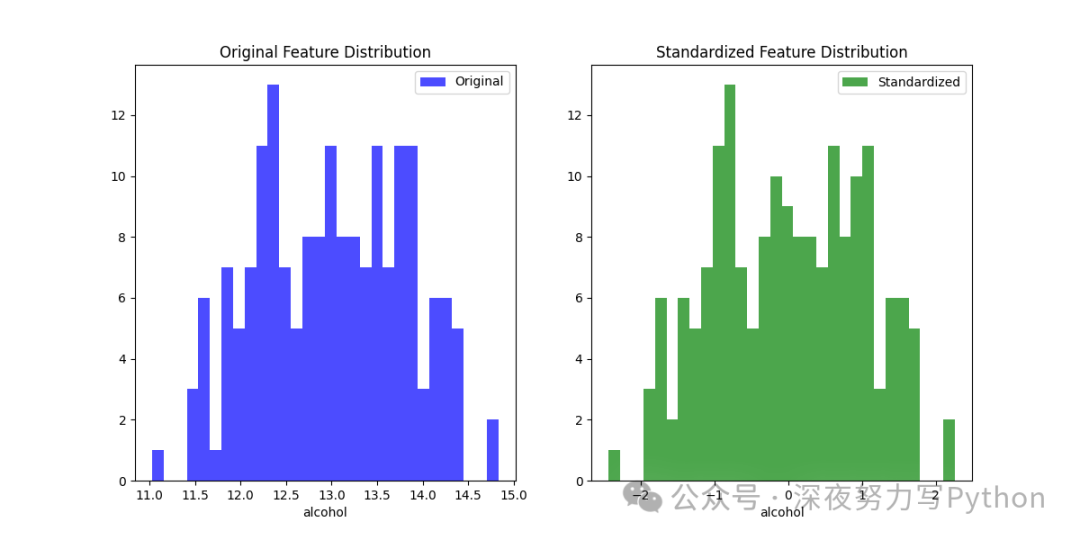
3 特征编码:独热编码(One-Hot Encoding)
原理
独热编码将分类变量转换为二进制特征向量,每个类别对应一个二进制特征。对于具有 个不同类别的分类变量,独热编码会创建 个二进制特征。
核心公式
假设有一个分类特征 ,取值 ,独热编码后的特征表示为:
独热编码通过创建二进制指示器矩阵来实现。
优缺点与适用场景
优点:
简单直观,适用于大多数分类变量的处理。
使得模型能够处理非数值型数据。
缺点:
高维数据集下,可能导致维度灾难(尤其是类别数目较多时)。
对于某些模型(如决策树),独热编码可能会降低模型性能。
适用场景:
用于处理非数值的分类变量,如性别、城市、职业等。
核心案例代码
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
# 创建样本数据集
data = {'City': ['New York', 'Los Angeles', 'Chicago', 'Houston', 'Phoenix']}
df = pd.DataFrame(data)
# 独热编码
df_encoded = pd.get_dummies(df, columns=['City'])
# 数据可视化
sns.heatmap(df_encoded.T, annot=True, cmap="YlGnBu", cbar=False)
plt.title("One-Hot Encoding Visualization")
plt.show()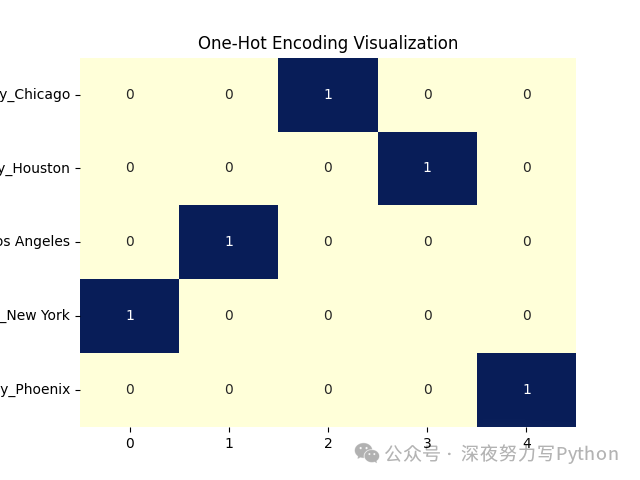
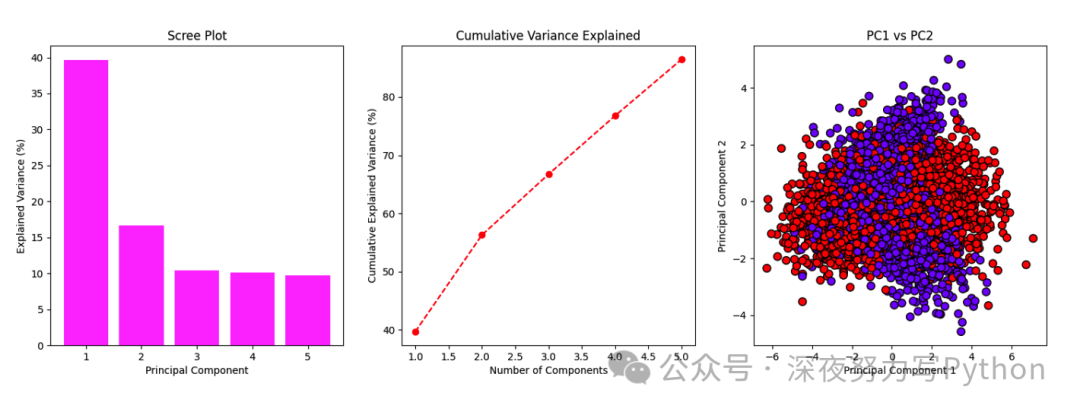
4 降维:主成分分析(PCA)
原理
主成分分析(PCA)是一种无监督的降维技术,通过线性变换将原始特征空间转化为新的特征空间,使得新特征(主成分)的方差最大化。PCA 的核心思想是找到数据集中变化最大的方向,并将数据投影到这些方向上。
核心公式
1. 协方差矩阵:
其中, 是第 个样本, 是样本均值。
2. 特征值分解:计算协方差矩阵的特征值 和特征向量 。
3. 降维:选择前 个最大特征值对应的特征向量,构成新的特征空间。
其中 是由 个特征向量组成的矩阵, 是降维后的数据。
优缺点与适用场景
优点:
在保持数据变异性较大的情况下,有效降低数据维度。
降维后,能使模型更易于理解和计算。
缺点:
PCA 只关注线性相关性,可能无法捕捉复杂的非线性结构。
新特征(主成分)可能缺乏直观解释性。
适用场景:
高维数据分析,如图像数据、基因数据。
数据预处理中的降噪步骤。
核心案例代码
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import seaborn as sns
# 加载数据
data = load_iris()
X = data.data
# PCA降维至2D
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 绘制2D PCA图
plt.figure(figsize=(8, 6))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=data.target, palette='viridis')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of IRIS Dataset')
plt.show()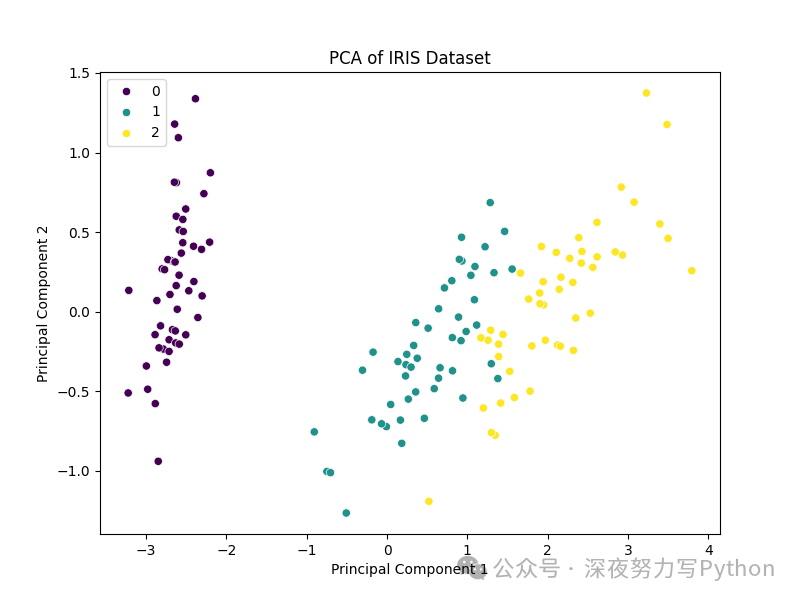
5 特征构造:多项式特征
原理
多项式特征通过将原始特征扩展到多项式空间,以提高模型的表达能力。它是通过生成原始特征的所有可能组合来创建新特征。
核心公式
对于一组特征 ,其二阶多项式特征表示为:
若包含二阶项和交叉项:
优缺点与适用场景
优点:
增强模型捕捉非线性关系的能力,适用于线性模型扩展为非线性模型。
通过生成特征组合,提升模型的复杂性和预测能力。
缺点:
可能导致特征数量激增,增加计算成本和过拟合风险。
需要对生成的多项式特征进行特征选择或正则化。
适用场景:
非线性回归问题,如多项式回归。
线性模型(如线性回归、SVM)扩展为非线性模型。
核心案例代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
# 生成模拟数据
np.random.seed(42)
X = np.random.rand(1000, 1) * 2 - 1
y = X**2 + 0.1 * np.random.randn(1000, 1)
# 多项式特征构造
poly = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly.fit_transform(X)
# 拟合线性回归模型
model = LinearRegression()
model.fit(X_poly, y)
# 绘图
plt.scatter(X, y, color='blue', label='Original data')
X_fit = np.linspace(-1, 1, 100).reshape(-1, 1)
y_fit = model.predict(poly.transform(X_fit))
plt.plot(X_fit, y_fit, color='red', label='Polynomial Regression')
plt.title('Polynomial Features')
plt.legend()
plt.show()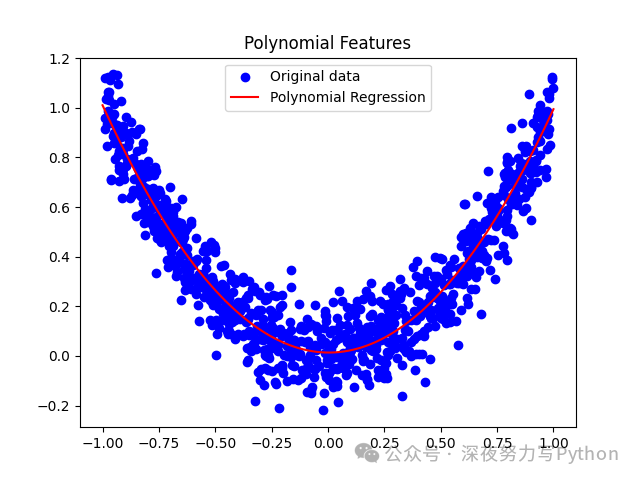
6 特征离散化:分位数分箱(Quantile Binning)
原理
分位数分箱是一种数据离散化技术,将连续特征值按照指定的分位数进行分箱。每个分箱包含相同数量的数据点,这有助于减少连续特征中的噪声。
核心公式
1. 计算分位数:对于每个数据点,计算其在数据分布中的分位数位置 。
其中 是数据点 的排序位置, 是数据点总数。
2. 分箱:将数据点分配到分位数范围对应的箱中。
优缺点与适用场景
优点:
能处理数据中的异常值,使模型更加鲁棒。
对于不满足正态分布的数据,分位数分箱可以平衡数据分布。
缺点:
可能丢失连续特征中的精确信息。
如果数据中分布极不均匀,分箱结果可能不理想。
适用场景:
数据预处理中的离散化步骤,如回归问题中的连续特征离散化。
数据分析中的分布平滑。
核心案例代码
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 生成随机数据
np.random.seed(0)
data = np.random.randn(1000)
# 分位数分箱
df = pd.DataFrame(data, columns=['Feature'])
df['QuantileBin'] = pd.qcut(df['Feature'], 4, labels=False)
# 数据可视化
plt.figure(figsize=(10, 6))
plt.hist(df['Feature'], bins=30, alpha=0.7, label='Original Data', color='blue')
for i in range(4):
plt.axvline(df[df['QuantileBin'] == i]['Feature'].max(), color='red', linestyle='--', label=f'Bin {i+1}' if i == 0 else "")
plt.legend()
plt.title('Quantile Binning')
plt.show()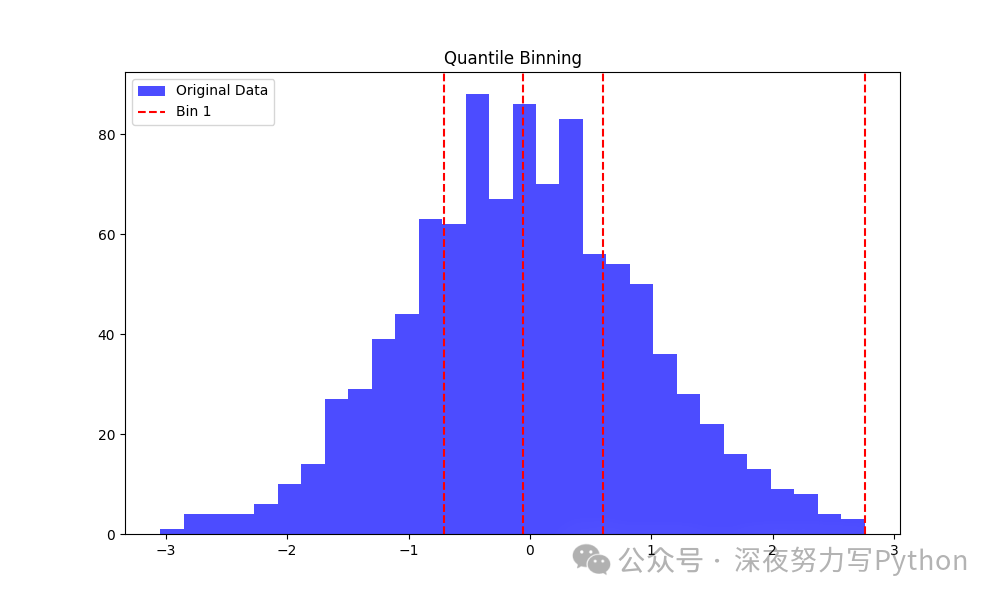
7 特征组合:加法组合
原理
加法组合是一种简单的特征组合方法,通过将两个或多个特征相加来创建新的特征。这种方法可以捕捉特征之间的线性组合关系,提升模型表达能力。
核心公式
对于特征 和 ,加法组合后的新特征 表示为:
优缺点与适用场景
优点:
简单易实现,可以快速生成新的特征。
有助于线性模型捕捉特征间的关系。
缺点:
过多的特征组合可能导致维度灾难。
加法组合只能捕捉线性关系,无法捕捉更复杂的非线性关系。
适用场景:
简单线性模型的特征增强,如线性回归。
数据预处理中创建新特征。
核心案例代码
import pandas as pd
import matplotlib.pyplot as plt
# 创建样本数据集
data = {
'Feature_1': [1, 2, 3, 4, 5],
'Feature_2': [10, 20, 30, 40, 50]
}
df = pd.DataFrame(data)
# 特征加法组合
df['Feature_Sum'] = df['Feature_1'] + df['Feature_2']
# 可视化新特征
plt.figure(figsize=(8, 6))
plt.plot(df['Feature_1'], df['Feature_Sum'], marker='o', linestyle='-', color='purple', label='Feature 1 + Feature 2')
plt.xlabel('Feature 1')
plt.ylabel('Sum Feature')
plt.title('Additive Feature Combination')
plt.legend()
plt.show()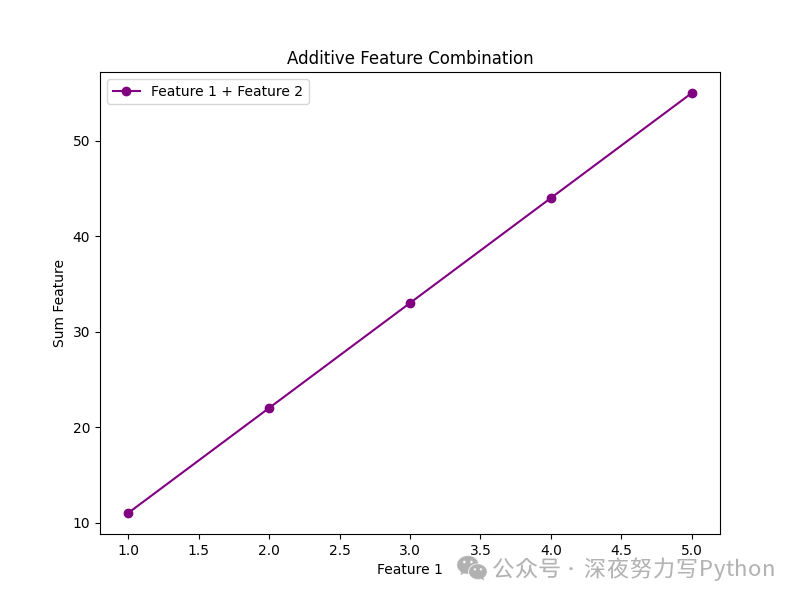
8 特征选择:LASSO
原理
LASSO(Least Absolute Shrinkage and Selection Operator)是一种带正则化的线性回归方法,通过对回归系数加上 正则化项,从而达到稀疏性特征选择的目的。LASSO 可以将一些回归系数压缩为零,从而有效选择出重要特征。
核心公式
LASSO 的目标函数:
其中:
是第 个样本的目标值。
是第 个样本的特征向量。
是回归系数。
是正则化参数。
推导:
正则化会惩罚回归系数,使得一些系数压缩为零。
通过调整 ,可以控制稀疏性和模型复杂度。
优缺点与适用场景
优点:
能自动执行特征选择,选择出对模型最重要的特征。
在高维数据中,LASSO 能有效避免过拟合。
缺点:
在高相关性特征下,LASSO 会随机选择一个特征并压缩其他特征为零。
对于一些复杂问题,LASSO 的预测效果可能不如其他方法。
适用场景:
高维度数据中的特征选择。
线性模型的特征稀疏化。
核心案例代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso
from sklearn.datasets import make_regression
# 生成模拟数据
X, y = make_regression(n_samples=1000, n_features=10, noise=0.1, random_state=42)
# LASSO回归
lasso = Lasso(alpha=0.1)
lasso.fit(X, y)
# 可视化回归系数
plt.figure(figsize=(10, 6))
plt.bar(range(X.shape[1]), lasso.coef_, color='darkorange')
plt.xlabel('Feature Index')
plt.ylabel('Lasso Coefficients')
plt.title('Lasso Feature Selection')
plt.show()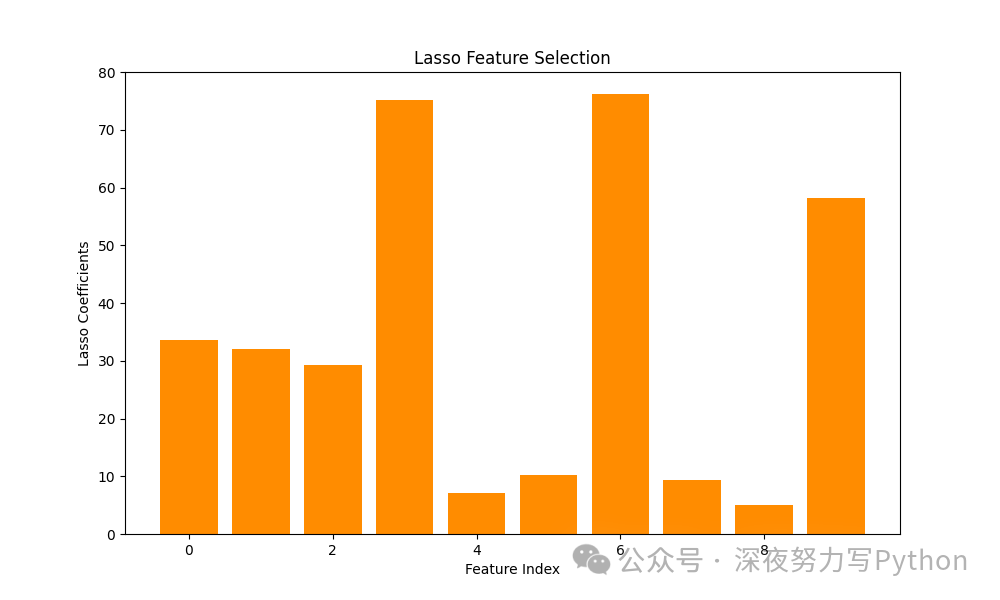
9 时间序列特征提取:滑动窗口
原理
滑动窗口是一种常用于时间序列分析的特征提取方法,通过在时间序列数据上应用固定长度的窗口,并计算窗口内的统计特征(如均值、标准差等),从而生成新的特征序列。
核心公式
假设时间序列数据为 ,滑动窗口大小为 ,对于第 个滑动窗口(从 到 ),计算窗口内的均值:
类似地,可以计算标准差、最大值、最小值等特征。
优缺点与适用场景
优点:
能捕捉时间序列中的局部特征,有助于识别趋势、周期等模式。
简单有效,广泛应用于各种时间序列问题。
缺点:
选择不当的窗口大小可能导致信息丢失或噪声增加。
滑动窗口产生的新特征数量会显著增加数据维度。
适用场景:
时间序列预测、异常检测、信号处理等领域。
核心案例代码
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 生成模拟时间序列数据
np.random.seed(42)
time_series = np.cumsum(np.random.randn(1000))
# 滑动窗口计算
window_size = 50
rolling_mean = pd.Series(time_series).rolling(window=window_size).mean()
# 绘图
plt.figure(figsize=(12, 6))
plt.plot(time_series, label='Original Time Series', color='blue', alpha=0.6)
plt.plot(rolling_mean, label=f'Rolling Mean (window={window_size})', color='red')
plt.title('Sliding Window Feature Extraction')
plt.legend()
plt.show()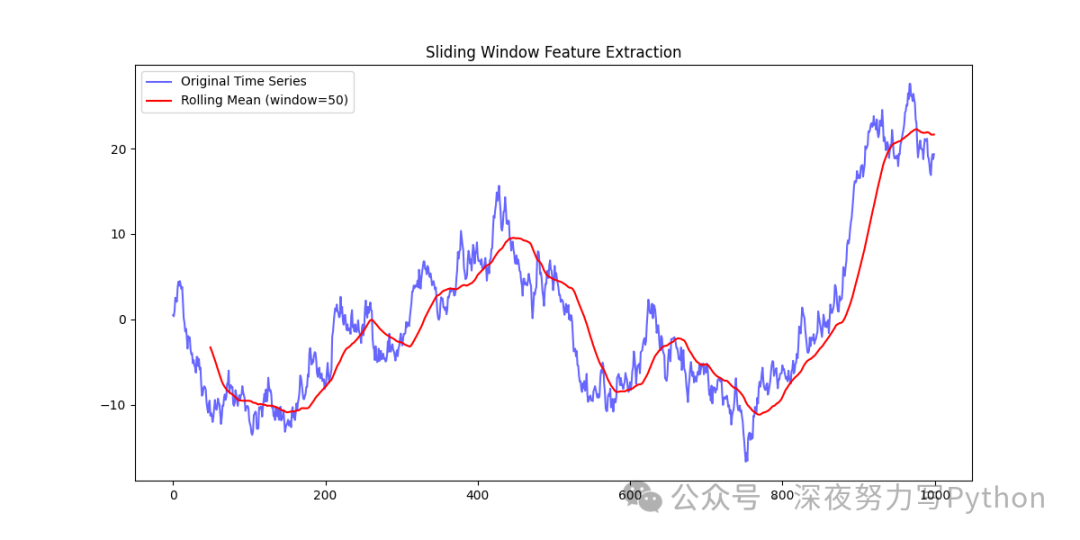
10 文本特征提取:TF-IDF
原理
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征提取方法,通过衡量词语在文档和整个语料库中的重要性来生成特征向量。它考虑了词语在文档中的频率(TF)和词语在整个语料库中的稀有性(IDF)。
核心公式
1. 词频 (TF):
其中 是词 在文档 中出现的次数,分母是文档中所有词的出现次数。
2. 逆文档频率 (IDF):
其中 是文档总数,分母是包含词 的文档数目。
3. TF-IDF:
优缺点与适用场景
优点:
能有效衡量词语的重要性,忽略常见的停用词。
简单易实现,广泛应用于文本分类、信息检索等领域。
缺点:
无法捕捉词语之间的顺序和语义信息。
对长文档或短文档可能有偏差,需要进一步处理。
适用场景:
文本分类、情感分析、信息检索等。
核心案例代码
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
import seaborn as sns
import matplotlib.pyplot as plt
# 创建样本文本数据
documents = [
"The sky is blue",
"The sun is bright",
"The sun in the sky is bright",
"We can see the shining sun, the bright sun"
]
# 计算TF-IDF
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(documents)
# 转换为DataFrame
df_tfidf = pd.DataFrame(tfidf_matrix.toarray(), columns=vectorizer.get_feature_names_out())
# 可视化
plt.figure(figsize=(10, 6))
sns.heatmap(df_tfidf, annot=True, cmap="Blues", cbar=False)
plt.title("TF-IDF Feature Matrix")
plt.xlabel("Words")
plt.ylabel("Documents")
plt.show()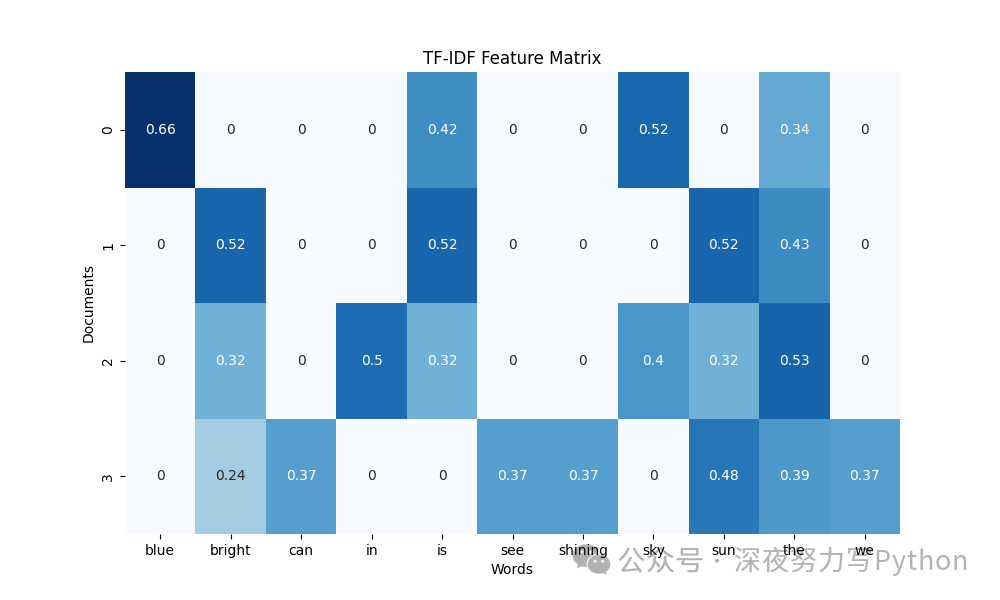
最后
大家有问题可以直接在评论区留言即可~
喜欢本文的朋友可以收藏、点赞、转发起来!

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)
















 7328
7328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









